
自作データセットで物体検出モデル yolov9 を訓練する

先月末に、物体検出モデル「YOLO」のバージョン 9 が発表されたので、手元の PC (Ubuntu 22.04) で動かしてみました。
論文はこちら
Github はこちら
(2024.3.24 追記) 論文紹介を書きました。
※この投稿は 2024 年 3 月 3 日時点 (v0.1) の情報に基づいています。コードは日々更新されており、時間が経てばもう少しユーザーに親切な構成になるとは思いますが、「今すぐ動かしたいんだ」という方向けに共有します。
動作の確認
リポジトリとデータのコピー
デスクトップに yolov9 のレポジトリをコピーします
cd Desktop
git clone https://github.com/WongKinYiu/yolov9
cd yolov9pretrained というフォルダを作り、事前訓練済みのモデルもダウンロードします。現時点では v0.1 ですが、変わるかもしれません。
wget -P pretrained -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt
wget -P pretrained -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt
wget -P pretrained -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt
wget -P pretrained -q https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt同様に、お試しで検出する画像を sample_images フォルダにダウンロードします。

wget -P sample_images https://raw.githubusercontent.com/ultralytics/yolov5/master/data/images/bus.jpg
wget -P sample_images https://raw.githubusercontent.com/Megvii-BaseDetection/YOLOX/main/assets/dog.jpgライブラリのインストール
Anaconda の仮想環境を構築し、必要なライブラリをインストールします。python のバージョンは適当です (3.9 で動きました)。
conda create -n yolov9 python=3.9
conda activate yolov9
pip install -r requirements.txt事前学習モデルによる検出
python detect.py --weights pretrained/yolov9-c.pt --source sample_images \n
--data data/coco.yaml --device 0AttributeError: 'list' object has no attribute 'device'
自分が動かしたときには、 上のようなエラーが出ました。GitHub の issue を見ると、yolov9-c, yolov9-e で検出する場合には、utils/general.py の 903 行目を以下のように修正する必要があるそうです。
prediction = prediction[0][1] # prediction[0]この修正をしたうえでもう一度検出したところ、正常に動きました。runs/detect/exp フォルダに以下のファイルが出力されます。
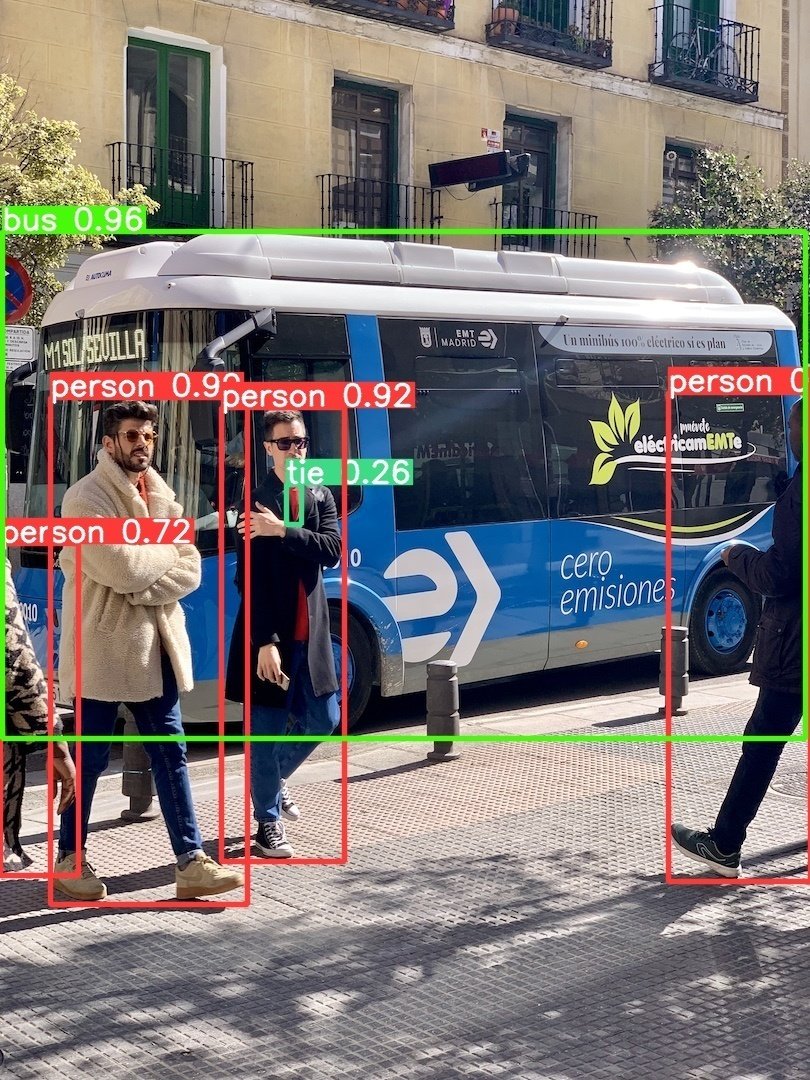

自作データセットでの訓練
データセットの準備
データセットの構成はこれまでの yolo と同じです。画像名は任意ですが、同じ名前のテキストファイルを /labels に作る必要があります。
└─{データセット名}
├─train
│ ├─images
│ │ 0001.jpg
│ │ 0002.jpg
│ │ ...
│ └─labels
│ 0001.txt
│ 0002.txt
│ ...
├─val
│ ├─images
│ │ ...
│ └─labels
│ ...
│
└─test
├─images
│ ...
└─labels
...データファイルの作成
data フォルダにある coco.yaml を参考に、データセットのパスとクラス名を指定します。自分は他のバージョンの yolo も使っているので、データセットは yolo9 フォルダの外に置いています。custom_dataset.yaml という名前で同じフォルダに保存します。
# Train/val/test sets
path: ../yolo_datasets/dataset1 # dataset root dir
train: train # train images (relative to 'path')
val: val # val images (relative to 'path')
test: test # test images (optional)
# number of classes
nc: 3
# Classes
names:
0: tooth
1: denticle
2: saw-toothed0から訓練
GitHub の記載に従って、とりあえず 3 epoch で訓練を実施してみます。
python train_dual.py --workers 8 --device 0 --batch 16 \n
--data data/custom_dataset.yaml --cfg models/detect/yolov9-c.yaml \n
--img 640 --weights '' --hyp hyp.scratch-high.yaml --min-items 0 --epochs 3自分はプログラムは回ったものの、しつこく AttributeError が出ました。GitHub の Issue を参考に、Pillow を再インストールしたら直りました。(2024.10.8 追記)Pillow のバージョンを下げると,ライブラリの依存関係が崩れる可能性があります.GitHub の Issue には utils/plots.py を 1 行だけ書き換える修正が提案されています.詳しくは以下の記事をご覧ください.
訓練中はログが出力されますが、かなり低い精度になっていると思います。引数 --weights を指定しない場合、ランダムに初期化された重みからの訓練になるようです。
事前学習モデルのファインチューン
そこで、先ほどダウンロードした事前学習モデルを使ってファインチューニングをしてみます。先ほどよりは精度が改善すると思います。
python train_dual.py --workers 8 --device 0 --batch 16 \n
--data data/custom_dataset.yaml --cfg models/detect/yolov9-c.yaml \n
--img 640 --weights pretrained/yolov9-c.pt --hyp hyp.scratch-high.yaml \n
--min-items 0 --epochs 3テスト
テストデータを使ってテストをします。--weights には先ほどの訓練で保存されたモデルのパスを指定します(exp を exp2, exp3 などと書き替えてください)。
python val.py --data data/custom_dataset.yaml --img 640 --batch 32 \n
--conf 0.001 --iou 0.7 --device 0 \n
--weights runs/train/exp/weights/best.pt --task test結果は runs/val 以下に出力されます。PR曲線を比べてみると、事前学習モデルを使った方が精度が高いことが分かります。
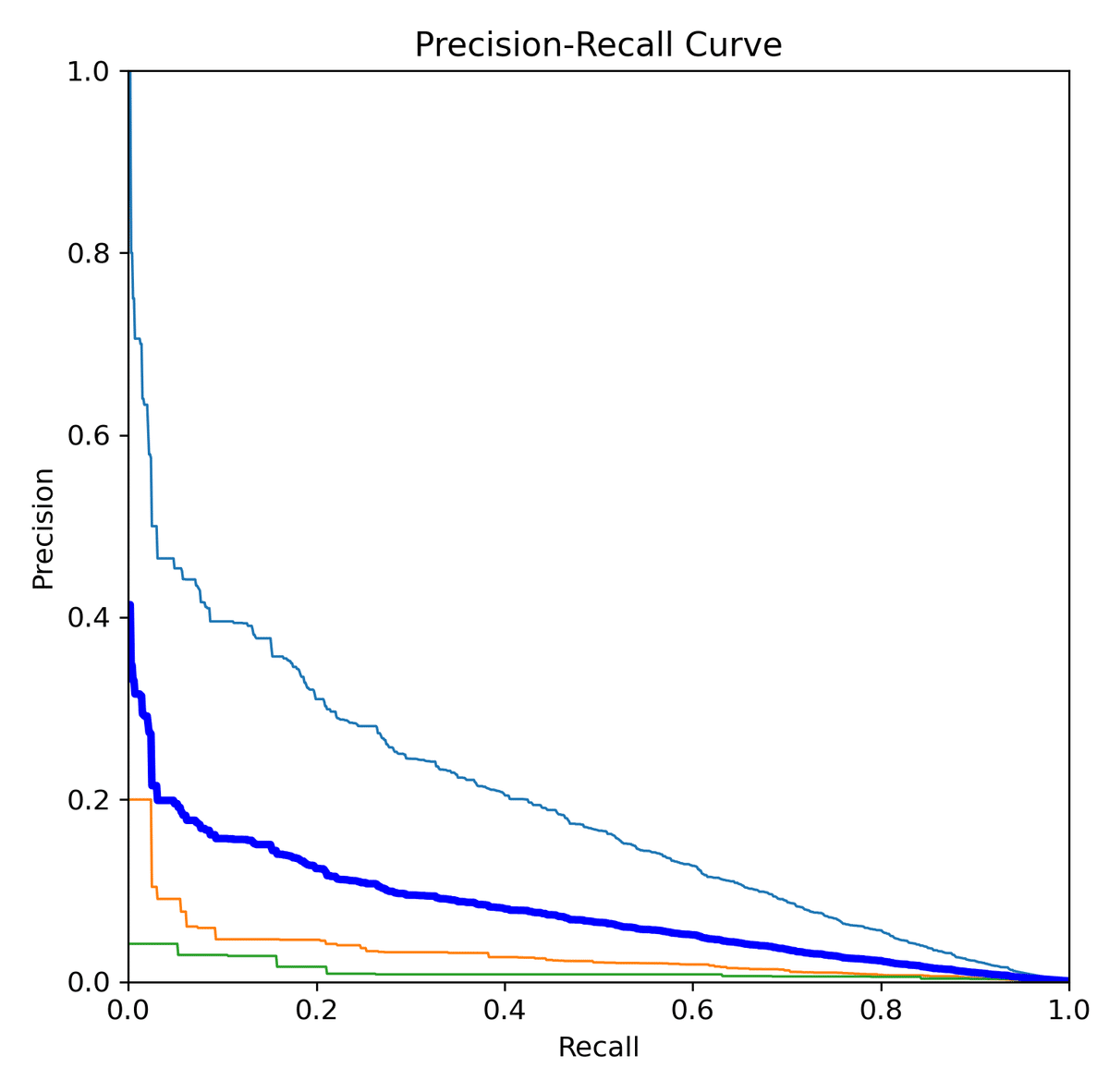
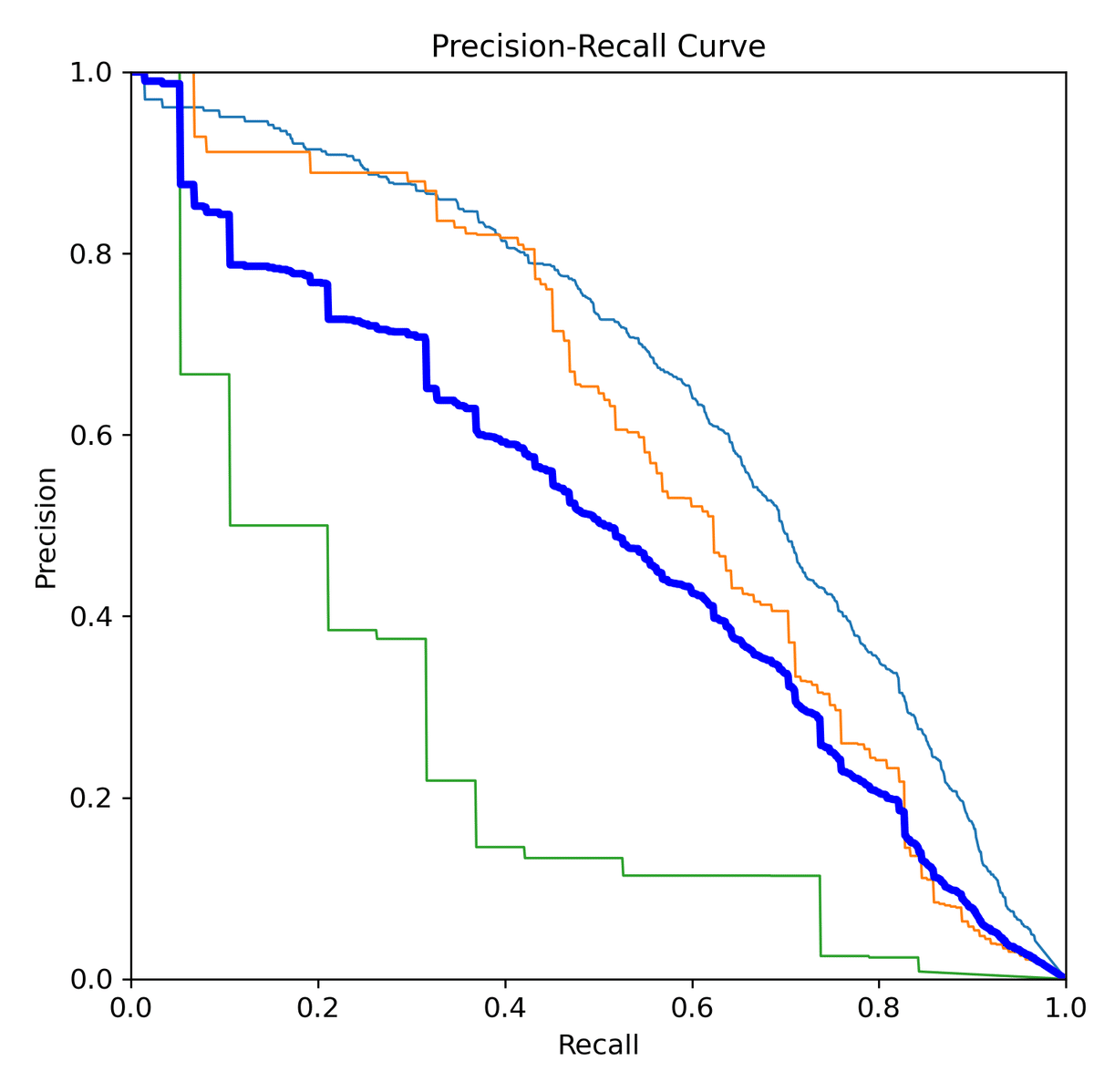
あとはエポックを増やすなり、ハイパーパラメータファイルをいじるなりしてガンガン回してください。
ここまで読んで頂きありがとうございました。何かのお役に立てれば嬉しいです。
追記
2024/3/5: note 公式マガジン「つくってみた・やってみた(総合)」に追加されました。ありがとうございます!