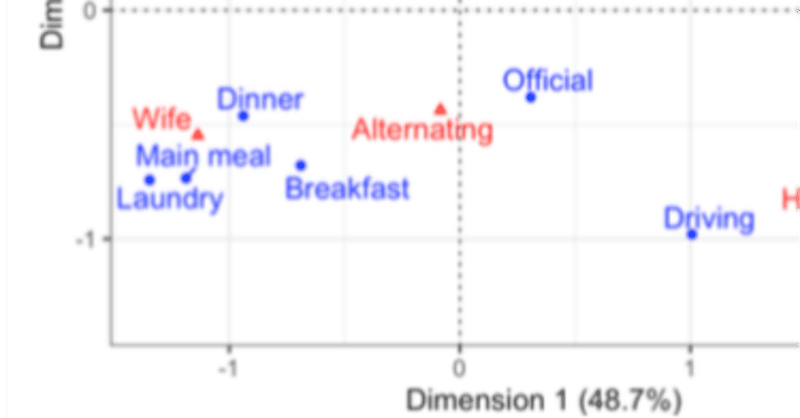
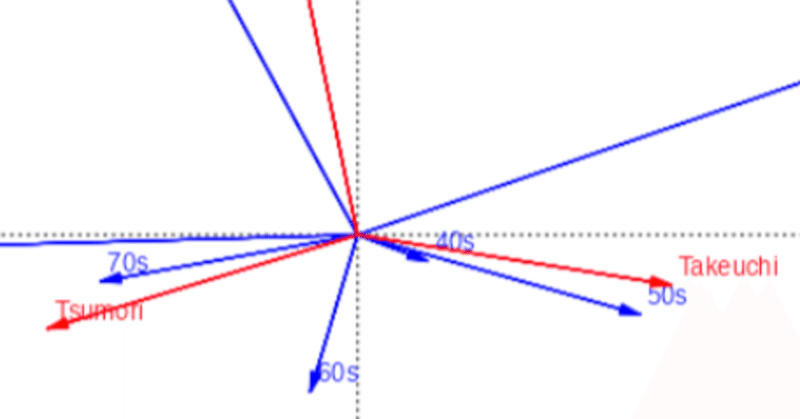
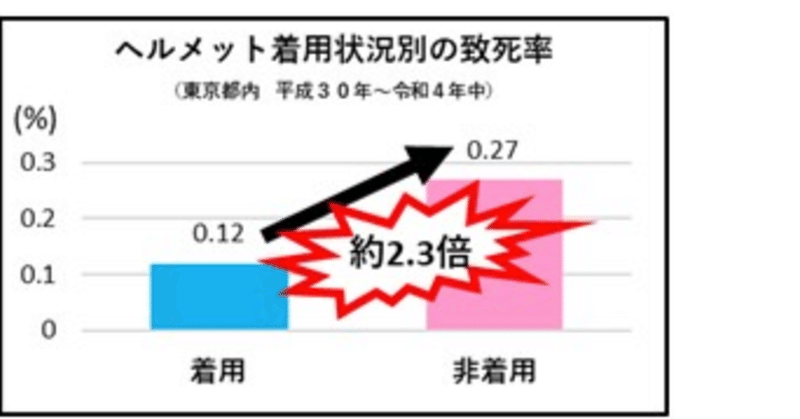
対応分析のcaパッケージを初めて使ったのは2009年のことだった。
Package ‘ca’
Michael Greenacre 著、藤本 一男氏訳の本がオーム社から出ている。
『データサイエンスのための統計学入門・第2版』(黒川利明氏訳、オライリー・ジャパン)の第7章の「コレスポンデンス分析」でも、caパッケージが使われている。翻訳の誤りが各所にある。
library(ca).tbl <- matrix(c(12593,20650,23579,9256,9117,30032,7387,3088,4884,5968,3243,2004,