
ロボットアームで器用な作業を実現する模倣学習-Action Chunking Transfomer Policyの紹介

ロボットの動作獲得でも学習ベースの手法がメジャーになりつつある。特に模倣学習は人間のデモンストレーションからロボットの動作を獲得する手法として注目されている。一方で模倣学習でマニピュレーションを実現しようとすると位置精度の良い高価なロボットやセンサが必要になる。さらにお手本となる人間の複雑な動作が課題となり実現は容易ではない。ALOHAと呼ばれるプロジェクトは安価な双腕マニピュレーターを使ったテレオペレーションシステムとWEBカメラによるビジョンのみを利用して器用なマニピュレーションを模倣学習で実現しようとしている。模倣学習のアルゴリズムとしてTransformerで構成したConditional Variation Auto Encoder(CVAE)の方策Action Chunking Transformer(ACT) Policyを提案した。電池交換やフリーザーパックの口留タスクなどで従来手法を上回る結果を出している。
この記事では以下論文について、提案手法がどのように模倣学習の課題に対してアプローチしているかを紹介する。
Learning Fine-Grained Bimanual Manipulation with Low Cost Hardware
1.ALOHA プロジェクトのモチベーション
低コストで実現できる双腕ロボットアームによる器用な物体操作の実現
器用な物体操作をするマニピュレーションにはアクチュエータの位置決め精度や力覚触覚センサなどが必要となり必然的に高価なシステムが必要になる。筆者らは低価格なロボットアームを使った双腕ロボットアームの器用な物体操作を実現させようとしている。
具体的には ViperX(6DoF+グリッパ)を2台用いた双腕ロボットとWEBカメラを用いて模倣学習によって乾電池の入れ替えやフリーザーパックの口留めなど、操作対象が認識しづらく、形状も変化しやすく器用さと高い視覚能力を必要とするタスク実現させている。
2.模倣学習の課題とAction Chunking Transformer
模倣学習の課題
人間のデモンストレーションに起因する多峰性と非マルコフ性
模倣学習が難しい理由の一つに人間のデモンストレーションによる学習データがある。人間のデモンストレーションには一貫性がない。タスクによってはゴールまでの手順は複数あり、解き方はときどきによって変化する。一貫性のないデータから方策を学習させることが課題だ。
また別の課題として非マルコフ性への対応も挙げられる。学習ベースの方策は現在の状態を元に行動を決定する。行動の決定は現在の状態にのみ依存している。これがマルコフ過程だ。しかし、現実のタスクでは状態が同じであっても必ずしも同じ行動を取るわけではない。例えば一時的に物を保持して停止するアクションは同じ状態が続く。マルコフ性に従うならば、状態変化がないため結果は常に停止となりタスクは再開されずに失敗してしまう。
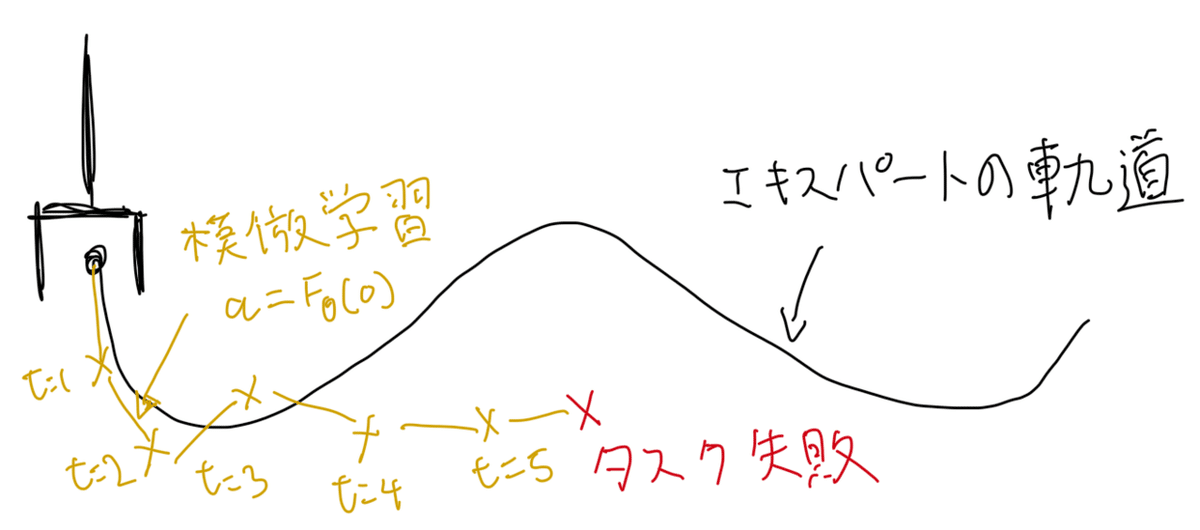
さらに推論時に蓄積する誤差が蓄積することで状態が学習データの内挿の範囲外に逸脱してしまう(Coupounding Error)という課題もある(図1)。
これらの課題に対して、Action Chunking Transformer Policy(以下ACT)というネットワークを提案し、さらにAction ChunkingとAction Chunking + Ensemblingを提案している。
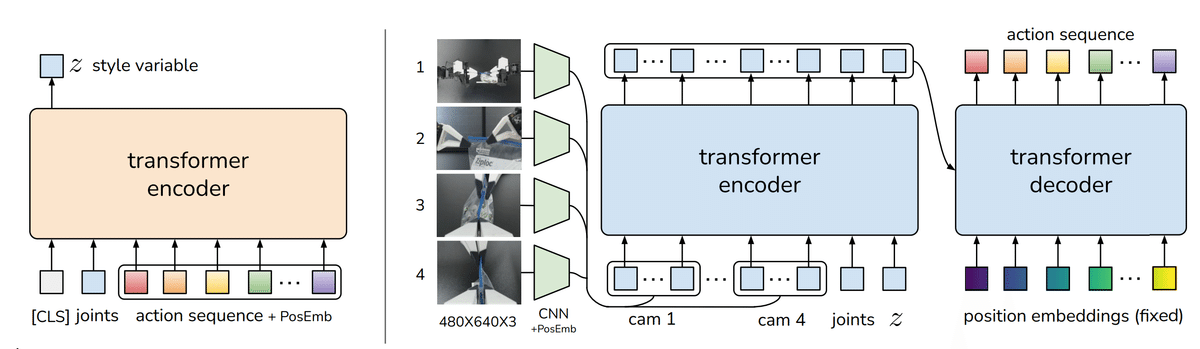
ACT Policyの構造
Transformerを使ったConditional Variational AutoencoderとChankingを提案
ACTはTransformerを使ったCVAE(Conditional Variational Autoencoder)として構成される。ロボットの各関節の角度をアクションとよび、その一定期間の履歴をアクションシーケンスまたはChankと呼ぶ。ACTはこのアクションシーケンスを入力し、1ステップ先のアクションシーケンスを出力する予測生成モデルだ。アクションシーケンスをまとめて生成することをChankingと呼んでいる。CVAEのエンコーダー(図1. 左側)にアクションシーケンスを与え正規分布に従う潜在表現をZを出力する。デコーダー(図1. 右側)はZを入力として次のタイムステップから始まるアクションシーケンスの予測値を出力する。ZはStyle variableと呼ばれている。推論時はCVAEのデコーダーのみを利用して、Zの値は0に固定される。続いてこのモデルが前述の課題をどう解いているのかを説明する。
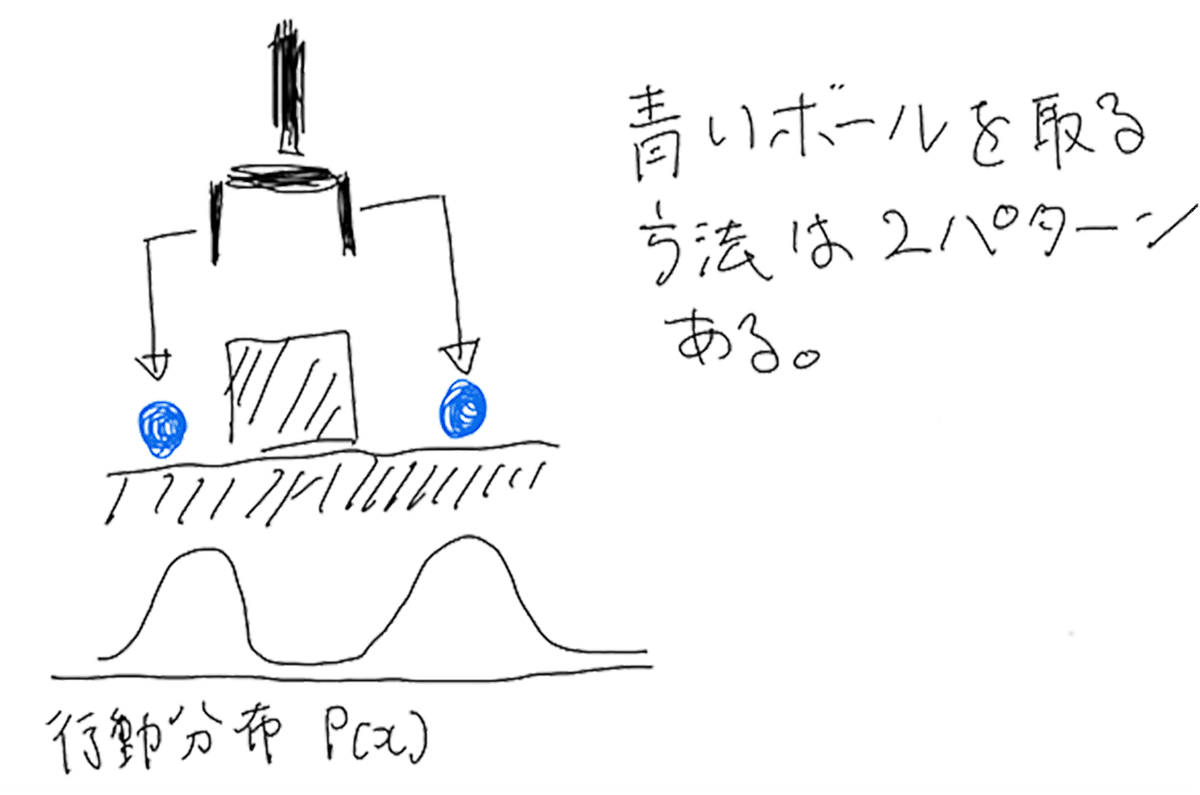
ポイント1. 学習データの多峰性をモデル化
CVAEの特徴を使って多峰性のある行動の確率分布をモデル化する
模倣学習は人間のデモンストレーションをもとに現在の状態から次の行動を予測する確率分布を学習する。この確率分布は最善の行動を選ぶために単峰性を持つことが好ましい。だが人間によるデモンストレーションは状態に対して一貫性がなく、その分布は多峰性を持つことになる。(図2. )そのため単純なBehaivior Cloningでは確率分布を表現しきれずタスクに失敗する原因となる。
そこでACTはCVAEの構造を取り、多峰性を「スタイル」として学習することで課題を解決していると考えられる。論文中に直接の記載はないが実験結果からZの重要性が示唆されている。
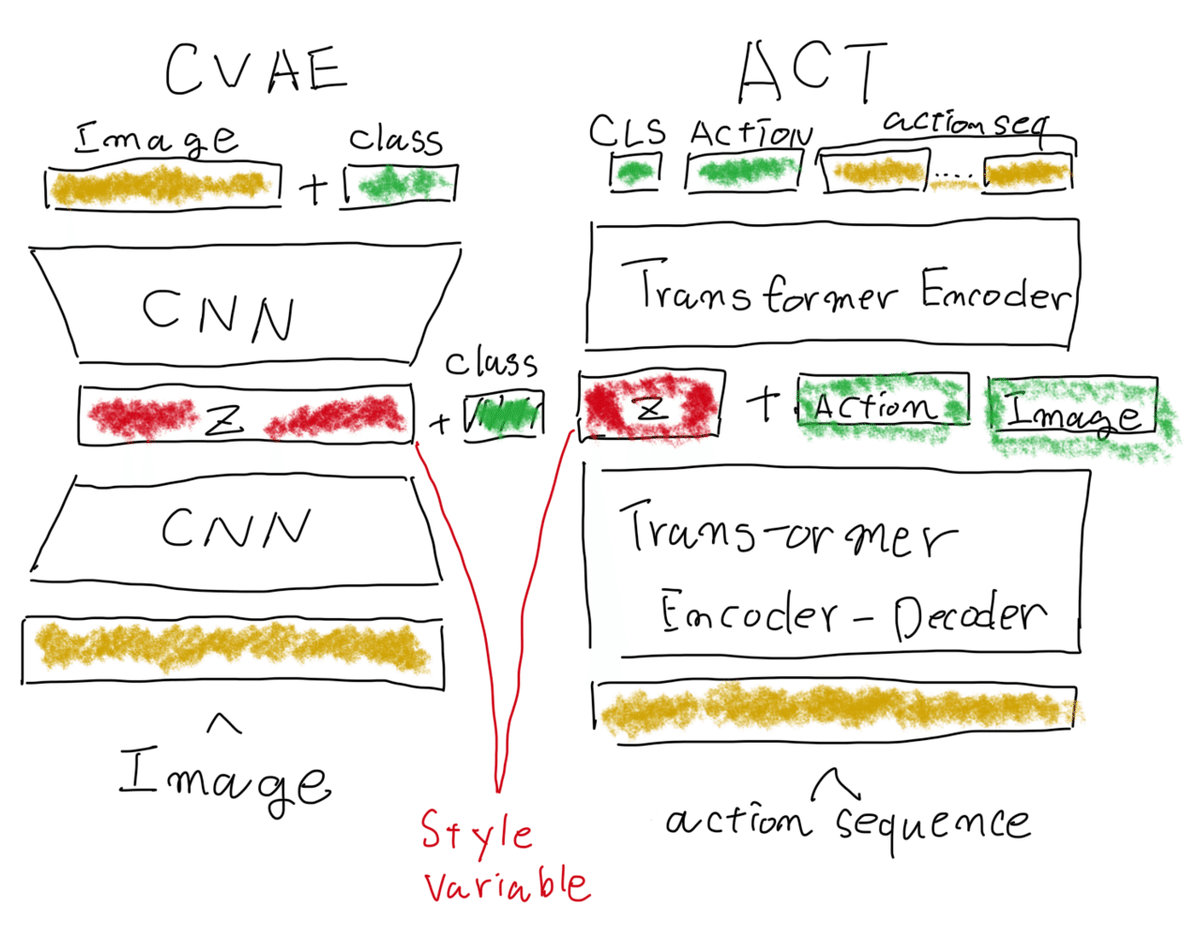
CVAEによる画像生成では学習させる画像のクラスを固定した上で潜在変数を変え、画像の種類は変えずにスタイルを変更することができる。例えば芝犬、プードルなのクラスを与え潜在変数Zの値を変更することで指定されたクラスの中でスタイル(小さい芝犬や座っている芝犬など)を変更することができる。
ACTの場合は現在の状態を与えることでその状態に沿ったアクションシーケンスを出力するが、潜在変数Zの値を固定して生成している。この潜在変数がうまく確率分布のモードを切り替える(複数ある峰を選択している)働きをしていると推測できる。
ポイント2. Chunkingによって非マルコフ過程に対応する
将来のアクションをまとめて推論することで誤差の影響を低減、作業の文脈に沿った動きを実現する。
非マルコフ過程と誤差の蓄積についてはChunkingとTemporal Ensembleと呼ばれる手法で解決を行なっている。Chunkingは観測された現在の状態からAction Chunkと呼ばれる将来のステップkにわたるアクションの塊をまとめて推論する手法だ(図. 5)。
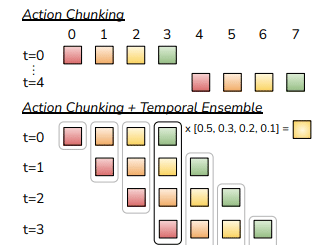
ここでkステップごとにkステップ分のアクションを決定した場合(図5. 上側参)、チャンクの境目で観測された状態量がk-1に期待した観測と大きくずれた場合、次のチャンクで取るアクションが大きく変わりロボットの大きな動きの変化につながってしまう。これを避けるため、実際には各ステップごとにkステップ毎にオーバーラップさせながらアクションを出力し、次のアクションの加重平均をとっている。(図5. 下側Temporal Ensemble)。
4.実験結果
実験条件
双腕マニピュレーターを使い2つのシミュレーションタスク、6つの実機タスクで評価を行なっている。各タスクは不定形の物体を扱ったものや、操作対象物が透明など認識がしずらいもの、形状が変化するもの、さらにタスクを実施する際に物体を固定して操作を止めなければいけないものなど、視覚の認識や非マルコフ性のあるタスクを設定している。
各タスクの実行時間は8-14秒の長さであり、50Hzで400-700ステップに相当する。タスク毎に50回デモンストレーションをおこない、10-20分程度のデータを集めている。

他の模倣学習手法と比較実験を行い、ACT Policyの有効性を検証している。
・BC-ConvMLP
単純なCNNを用いたBehaivior Cloningアルゴリズム。観測画像からアクションをCNNを用いて直接出力する
・BeT
TransformerベースのアクションだがChunkingはしておらず、観測画像の履歴から1アクションを求める。また画像エンコーダについては方策と分離しており最適化されていない。アクションは離散化された値になっている。(関節角を直接求めるのではなく決められたアクションにカテゴライズする)
・RT-1
同じくTransformerベースの方策、過去の観測情報の履歴から1アクションを計算する。アクションは離散化された値になっている。(関節角を直接求めるのではなく決められたアクションにカテゴライズする)
・VINN
観測された画像をk-NNで検索し、アクションを返す手法
実行結果
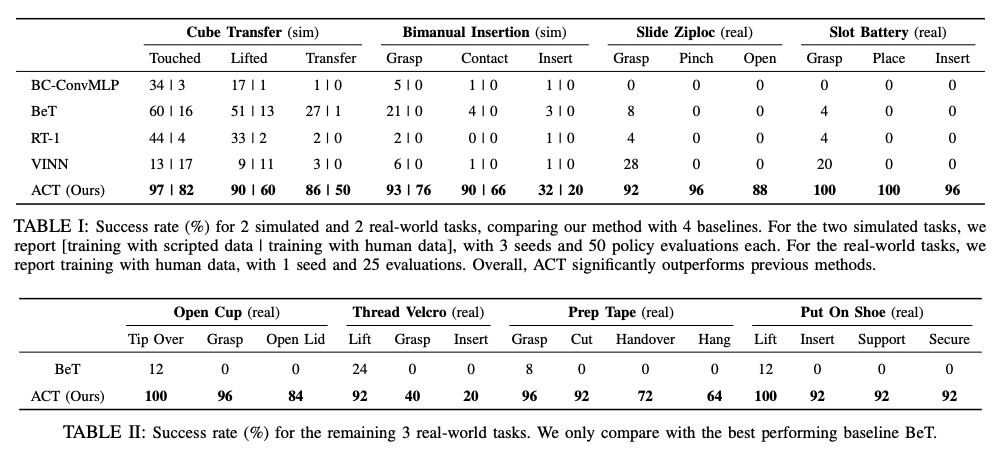
ACTポリシーでの試行結果は以下の表のようになっており、実験で比較した他の手法に比べてタスク成功率が格段に上がっている。(図7)そもそも他の手法のタスク成功率が極端に低いが、論文中では非マルコフ的な動作が含まれるタスクのため、他の手法では対応しきれていない可能性が示唆されている。
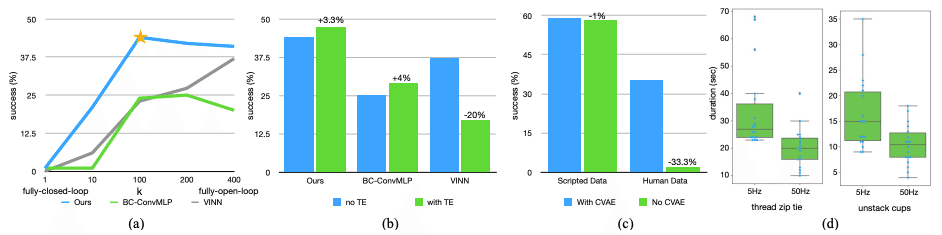
また図8の(B)ではTempolary Enmsemblingのあり/なしで性能比較を実施しており。Emnsemblingnの効果が確認できる。さらに(C)では学習時のLossからCVAEの目的関数(Zの分布と正規分布のKL距離)を取り除き、L1損失のみで学習させた場合の比較を載せている。プログラムで集めたデータ(Scripted Data)では差がないが、人間によるデモンストレーションではL1損失(生成誤差)のみで学習した場合は成功率が下がっている。これにより、CVAEが多峰性を持ったデータに対して対応できていることが確認できる。
まとめ
大量の試行が必要な強化学習に比べて、模倣学習は比較的容易にロボットにタスクを覚え込ませることができる。最近のAIを用いたロボットの開発では大量データから模倣学習により動作を作ることもあり、ロボットに複雑なタスクを学習させる有力な手法の一つになりつつある。
一方で大量データをどうやって集めるのか、集めたデータのばらつきや非マルコフ性を持つ実タスク、Compounding Errorなどの課題がある。ALOHAプロジェクトでは低価格なロボットとTransformerを用いたCVAEモデルによってこの課題にアプローチしている。特に提案されたACTについて、CVAEの性質をうまく使い多峰性のデータに対して対応を行なっている点が面白く感じた。