

#python


100日後にプロになるワシ28日目(Python)
前回の話。
スコアが合格点に足りなかった。
はい。
というわけなので今回は別のやり方で精度を上げて挑戦します
前回はビニング(値をまとめて分類する方法)を行なったので
今回は多項式・相互作用特徴量を使います。
多項式・相互作用特徴量については5記事くらい調べたけど理解不能だったため割愛
とりあえず「ビニングの強力なやつ」という認識
補足
基本的に、情報量が多ければ多いほど機械学習の精度
100日後にプロになるワシ27日目(Python)
お久しぶりです。
前回のお話。
テストデータ間違えた笑
今回はちゃんとしたデータで挑戦!
まずはテストデータをインポート(ちゃんとデータサイズを確認!)
次にカテゴリデータを数量データに変換!(男女を0,1に!)
bin化!!(数量の偏りがあるデータはザックリグルーピング!)
モデルは前回作ったのでそれで学習!
補足
学習自体は1行で終わる。
機械学習は前処理9割っていうけどほんま

100日後にプロになるワシ26日目(Python)
機械学習最後まで学習させて
AUC(Area Under the Curve)の値も92を超えた!!
AUC
AUCは指標の名前通りROC 曲線下の面積(積分)となります。この面積の範囲がは0から1 となります。ランダム分類器はのAUC値は0.5です。AUC値は0.5以上になれば分類器の効果がランダム分類器より良いです。AUC値は0.5以下になったら評価指標を逆にしてAUC値は0.5以上の分類器
100日後にプロになるワシ25日目(Python)
今日はロジスティック回帰を使った学習と
評価まで行った
# テストデータと学習データへ分割from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# ロジスティック回帰モデルのimportfrom s

100日後にプロになるワシ24日目(Python)
今日から始まりました
【第2回_Beginner限定コンペ】健診データによる肝疾患判定
前回の疾患有無ケースとほぼ同じ。
ただ、前回のAUCは93とかいくらしく。前回の86とかは軽く超えないといけない。単純になぞるだけじゃうまく行かなそうだ。
ちなみに、このコンペ。ランキングシステムがあって。9月末まで集計される。現状1位が93.555。93%で正解を当てられる。パナイ
ちなみに92以上
100日後にプロになるワシ23日目(Python)
昨日、機械学習を要約終わらせたが、まだその結果がどれだけ正しいかを分析してなかった。
今日はその分析と改善。
そして最後まで走りきりました!!
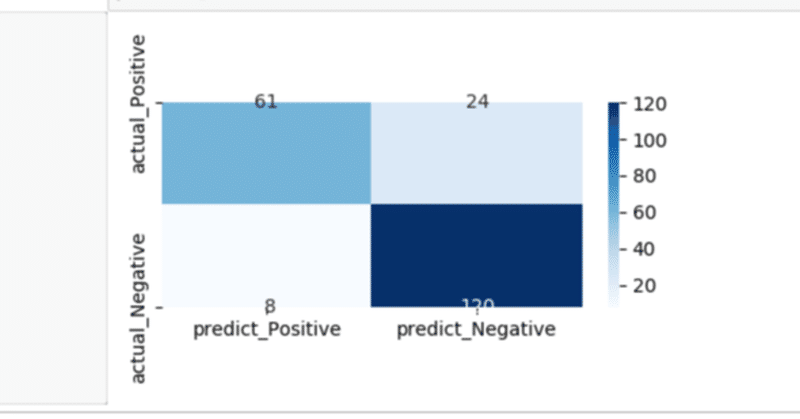
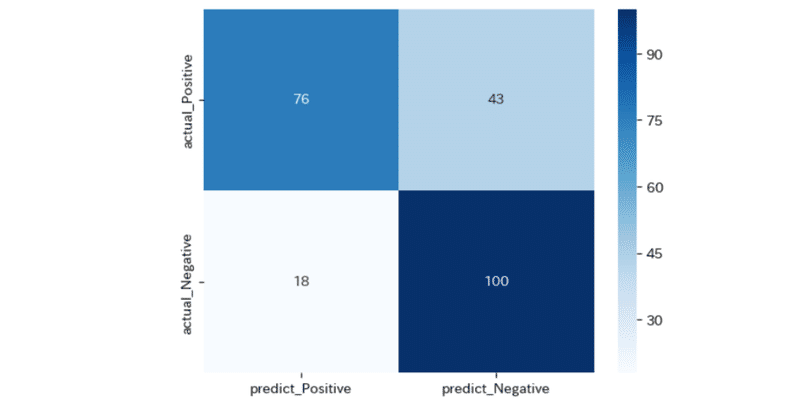
混同行列の計算今回は疾患があるかどうかの2択なので、予測した結果の疾患があるなし。と実際のデータの疾患のあるなしを比べた表を作成する
これを混同行列といいます。
from sklearn.metrics import confusion_matri
100日後にプロになるワシ23日目(Python)
昨日はデータの分析をしました。
今日はデータの分析の続きとようやく機械学習までできました!
目的「健康経営のための疾患リスク予測」
つまり患者のカルテのデータから疾患があるかどうかを予測するプログラムを作成する。
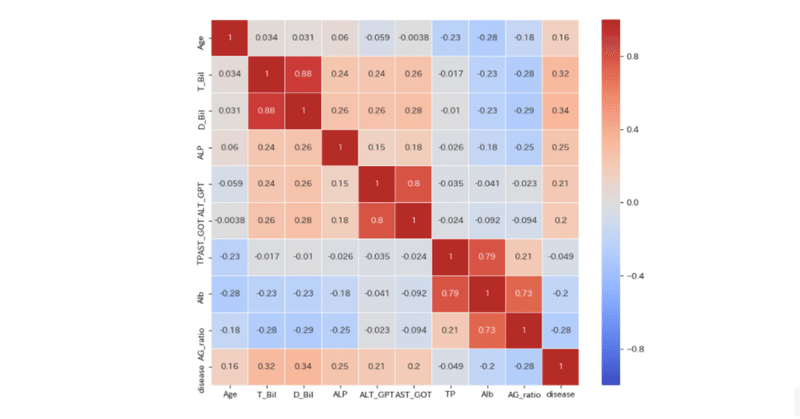
相関を確認する今まで(前回の引っ越しの回数予想)は自分の経験や間に基づく関係性を調べていました。
例えば引っ越し数との関係性が高いのは土日かどうかとか、2月とか3月などの繁忙期かど
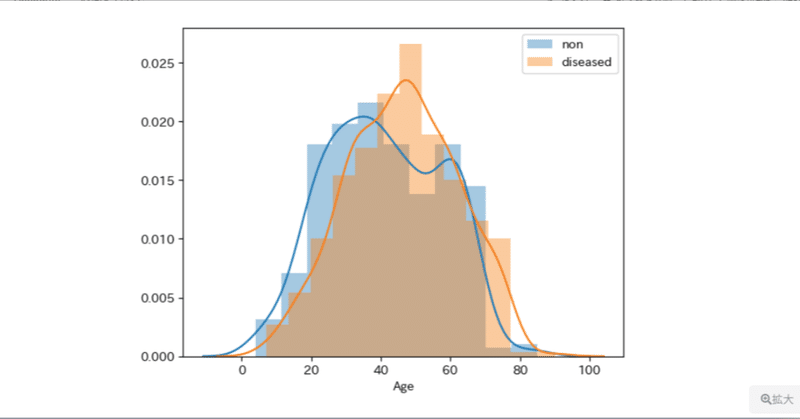
100日後にプロになるワシ22日目(Python)
昨日から「健康経営のための疾患リスク予測」が始まった。
この課題の目的は体のデータから疾患リスクを予想すること。
今日はデータの分析と分類をした。
統計データ今回は統計量を1発で調べられる関数decribeを使う
df.decribe() # dfは今回のdataframe Age Gender T_Bil D_Bil

100日後にプロになるワシ21日目(python)
急遽方向転換します。
昨日までは賃貸予測の学習してましたが
「健康経営のための疾患リスク予測」をします。
今僕がやってるSIGNATEで特別なコンペがやっているらしくそれに参加したいのでそちらの学習を進めることにしました。
SIGNATEでは称号システムがあるのですが、登録するだけではBiginnerのままなんですよね。
で、どうやって昇格すればいいのかわからなかったんですが、
今回Big

100日後にプロになるワシ20日目(Python)
前回。引っ越し数を予測する機械学習モデルを作成するも、結果ダメダメだったので、また別の機械学習の勉強を始めることにしました。
今回は「賃貸物件の家賃推定」
データはこんな感じ↓
カラム名 説明id 物件ID家賃 家賃(目的変数)所在地 住所アクセス 最寄りの路線等間取り 間取り築年数 築年数方角 方角面積 面積所在階 物件自体の階数と物件がある建物の総階数バス・トイレ バス・トイレの建てつけ等
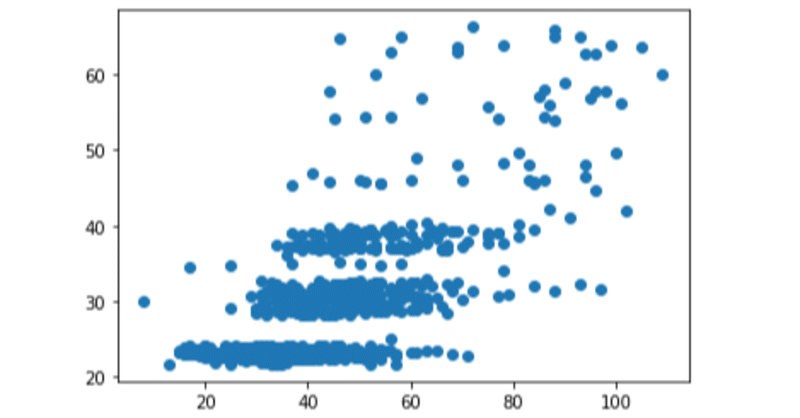
100日後にプロになるワシ19日目(python)
前回の続き。
結局時系列データにしないといけなかったので
datetimeを変形して週のデータに変更。
weekNumとして列に追加した。
ただ、1年間は52週あるのでfor文で対応
んで、
データがweekNumだけfloat型なのが気に入らないので型変換
ここでようやくデータ準備OK!!
学習用データと答えデータに分ける
今回は未来予測なので多分線形回帰がモデルとしてあってる。
と信

100日後にプロになるワシ18日目(Python)
今日のまとめやらかした!
けど一応時系列的にやっていく
まずは昨日の続きから
月で計算するよりも週で計測するといい感じなると思ったので
第何週ではどれだけの数引っ越しされたのかを算出しようとした
こんな感じで第0週と引っ越し回数の頻度対照表を作成
1年で54週あるのでそれをループして作成し。
横に連結させる
こんな感じ。
んでそれにラベルをつけて・・・
なかなかそれっぽい
これで

100日でプロになるワシ17日目(python)
昨日に引き続きデータ作成。
昨日は曜日ごとの引っ越し回数を抽出したのでそれをまとめます
weekの列が曜日を表しています↑
月曜から日曜日までの引っ越し回数との関係を抽出↑
連結して↑
ラベルを付与↑
曜日との関係データとしてこれで一旦OK
次は月別!と思ったんですが、3年分くらいデータがあるので
年の初めからの週をカウントしようかと思います
1年は52週!↑
諸事情あって今日は

100日後にプロになるワシ16日目(Python)
今回は機械学習をさせるための学習データと解答データを作成する
説明変数と目的変数機械学習では学習データを説明変数。解答データを目的変数という。
今回は全データを半分半分にして前半を説明変数。
後半を目的変数として扱う。
前回作成したデータを使う
データを半々で分ける
特徴量について特徴量とは簡単にいうと答えを導くための学習のとっかかりです。
今回で言えば引っ越し回数に影響しそうな数値の