
【2024年2月更新】 Filemakerで蔵書管理アプリ制作(その4)書影を取得する

2024.2.29追記
国立国会図書館サーチの仕様変更に対応しました。
前回に引き続きの蔵書管理アプリを作った話、今回は書影の取り込みについてです。本文は全て無料ですが、一番下の有料部分でデータをダウンロードできるようにしています。また、マガジンで購入していただいた場合は全てのデータをダウンロードできるようにしております。
国会図書館サーチは書影も提供している
前回まで、各種データを取得するために利用していた国会図書館サーチは書影の提供もしています。
前回まで利用していたURLとは違い、書影は専用のリクエストURLです。該当部分を引用します。
(2)リクエスト形式
リクエストは以下の形式の URL である。
https://ndlsearch.ndl.go.jp/thumbnail/[isbn/JP-e コード].jpg
(3)ISBN/JP-e コードの指定
書影を取得するには、リクエスト URL の末尾に取得対象の ISBN/JP-e コードを指定する。1 度のアクセスで指定できる ISBN/JP-e コードは 1 つである。
また、ISBN の指定は 13 桁(ISBN-13 形式)である(10 桁(ISBN-10 形式)での 指定は行えない。)。ただし、ISBN はハイフンで区切らずに入力する。JP-e コードは20 桁の英数字で指定する。
(4)データの返戻件数
本システムで保存・公開している書影は、1 つの ISBN/JP-e コードにつき 1 件のみである。そのため、返戻するデータも常に 1 件のみとなる。
(5)返戻形式
指定された ISBN/JP-e コードで、本システムが保存・公開中の書影データを検索し、その結果を返戻する。公開中の書影が取得できた場合は、その画像を返し、取得できな かった場合は、エラーとして HTTP ステータスコード「404 not found」を返す。
なお、指定の ISBN/JP-e コードにて完全一致で検索した結果を返すため、指定した ISBN/JP-e コード自体が存在しない値(形式が不正な場合や未指定の場合を含む。)の 場合も、ISBN/JP-e コード自体は存在するが、本システムで保存・公開中の書影がない 場合も、同等のエラー(404 not found)が返される。
説明は少し長いですが、内容は非常にシンプルです。13桁ISBNさえわかれば、URLの固定部分を””で囲って、&でつなげてやるだけです。計算フィールドで作ります。ここで「書影URL」「ISBN」はフィールド名です。jpg形式の画像ファイルが直接取得できます。
書影URL = "https://ndlcsarch.ndl.go.jp/thumbnail/" & ISBN &".jpg"
ただ表示させるだけならwebビューアー
URLを計算フィールドで作りましたので、webビューアーでアドレスをそのフィールドに指定してやれば、表示されます。これであれば、書影用のフィールドを作らずともwebビューアーのURL指定部分に上の計算式を入れてやれば機能します。
ただし、webビューアーを使う場合、ファイル自体は軽くなりますが、その都度ページを読み込むことになるのでレスポンスは遅く、通信環境に依存することになります。何冊分もストックされた時に、レコードを移動するごとに読み込むので、ちょっと負荷がかかります。

実際の表示はこうなります。

ISBNを入力した時点でURLが生成され、ビューアーでアクセスされるので、前回作った「読み込み」ボタンでタイトルを読み込むより先に書影が読み込まれます。
アプリのデータ内に書影を取り込む
登録した書籍1件を表示するごとにサイトにアクセスするのではなく、書影データを取り込んでしまうことで、ネット環境が無い状態でも書影が表示できるようになります。
「書影」という名前でオブジェクトフィールドを作り、そこにURLから挿入するスクリプトを使用して書影を入れていきます。


実際の表示はこうなります。webビューアーがHTMLを混み込んで表示させるのに対して、こちらはjpgを取り込んで表示させるため、位置とサイズが表示サイズに合わせて調整されます。

スクリプトは1行なので、前回まで作った各項目を自動入力するスクリプトに追加してやれば、各項目と書影の取り込みまで自動化するスクリプトができます。
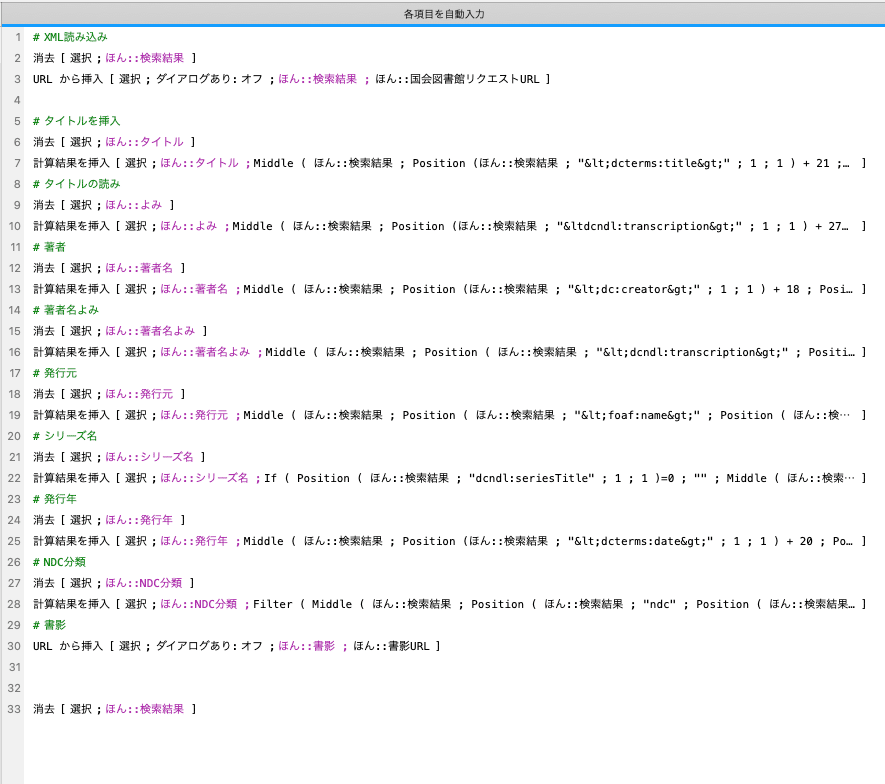
このスクリプトを、バーコードリーダーを起動するスクリプトの中に入れることで、バーコードを読むだけで書影と各項目を取得できるスクリプトになります。

ここで提供される画像はおよそ200〜300px四方で、そこまで大きくはありません。参考までに、手元の400タイトル弱をほぼ全て取り込んだ状態でファイルサイズが8MBです。
全ての書影があるわけではない
該当するISBNの書影を持っていない場合、エラーが返ってきます。参考までに、Loop関数を使って手元の390タイトルの書影取得を試みたところ、取得できたのは92タイトルでした。細かい分析はまだ行っていませんが、書影提供自体が後発の機能だからかもしれません。
現在手元にある蔵書目録は全部で380タイトルありますが、取得できなかった書影は楽天ブックスやopenBD(版元ドットコム)を使用して補完してます。
楽天ブックスは販売サイトゆえの細かい情報取得ができますが、自作する場合はサービス登録し、アプリIDなるものを取得する必要があります。
書影を取得できたのは
国会図書館 92/380
openBD(版元ドットコム) 294/380
楽天Books 251/380
この3ついずれでも取得できなかったのは46/380タイトルでした。感覚的には、取得できるものはopenBDと楽天ブックスでほぼ取得できる感じですが、商業ベースの場合、絶版や旧版の扱いが定かではないのと、サービス終了の可能性もゼロではないので国会図書館が確実だと思います。
2024年2月29日追記
国会図書館サーチの仕様変更を受けて、再度検証しました。こちらに記事としてまとめておりますので、ご覧ください。
今回も、作成したFilemakerアプリをこの下の有料部分でダウンロードできるようにしておきます。手元の本で遊んでもらえると嬉しいです。

この記事が気に入ったらチップで応援してみませんか?