Karasu DPO

概要
既存のデータセットを日本語に翻訳し、そのプロンプトに対する複数のLLMの応答を評価して、選好データセットを作成しました。
Huggingfaceでモデルを公開します:lightblue/Karasu-DPO-7B
実験では、メモリ削減のためにQLoRAとNF4量子化を使用し、DPOを実施しました。
日本語力の評価にはArena-Hard-Autoを使用し、ベースラインの50.0から学習後に66.2へとモデルの性能が向上しました。
学習に関するコードは、https://github.com/lightblue-tech/karasu_dpo_202501で公開しています。
データセット作成
学習には、LMSYS-Chat-1MやOASST2などの既存のデータセットを日本語に翻訳したものを使用しました。使用したデータセットは以下の表の通りです。

まず、各データセットのプロンプトをGPT-4o miniを使って日本語に翻訳し、さらに改善を行いました。具体的には、元の英語の質問データセットを日本語に翻訳し、その翻訳結果を確認して品質を向上させました。こうして質の高い日本語のデータセットが完成した後、Qwen2.5-7B-InstructとGPT-4o miniを用いて回答を作成しました。この際、翻訳のときと同様に、回答の精度を高めるためにシステムメッセージを設定し、回答内容を確認しています(システムメッセージの例は下図参照)。次に、これらの回答データをGPT-4o miniで評価し、選好データセットを作成しました。回答Aと回答Bを比較するようにLLMに指示し、順番によるバイアスを排除するために、QwenとGPTによる回答をそれぞれAとBの位置を入れ替えて2回評価を行いました。両方で高く評価された場合のみを選好データセットとして採用しています。



その結果、以下のような形式のデータセットが作成されます。使用したデータセットは、response-dataset-plus-qwen-judgedとして公開しています。学習用データセットは23098件、評価用データセットは234件です。

学習方法
この日本語データセットを使用することで、LLMの日本語チャット能力を向上させることができるという仮説を立てました。既に一定の性能を持つLLMに対してこのデータを用いて学習を行うことで、さらなる性能向上を目指しました。ベースモデルとしては、アリババクラウドのQwen2.5-7B-Instructを使用しました。
選好チューニングについて
選好チューニングとは、プロンプトに対して好ましくない応答(rejected)と好ましい応答(chosen)のペアを使って、LLMを人間の好みに合わせて最適化する手法です。選好チューニングは、指示チューニングと比べてデータセットの作成コストが低く、負のフィードバックを与えることができるという利点があります。指示チューニングには指示と理想的な応答を人手で作成する際に高い人的コストがかかりますが、選好チューニングの際には、応答自体は複数のLLMで生成し、応答の優劣の判定のみに集中することで指示チューニングより人的コストが低くなる傾向があります。また、負のフィードバックを与えることで、好ましくない応答の生成を抑制できます。この手法は、ハルシネーションや安全性の問題にも有効とされています。例えば、事前に知らない知識に関する応答に対して負のフィードバックを与えることで、偽の応答を効率的に抑えることができます。
選好チューニングの代表的な手法の一つにはRLHF(reinforcement learning from human feedback)があります。RLHFでは、LLMが生成した応答に対して、人間の好みに基づくスコアを報酬モデルを使って推定し、その報酬を最大化するように強化学習を行います。
DPOについて
DPO(direct preference optimization)は、RLHFと同等の学習を効率的かつ効果的に行う手法です。DPOでは、RLHFで必要だった報酬モデルを構築する必要がなく、RLHFと同様の訓練を下記の損失関数を勾配法による最適化を用いて直接行えます。単純な勾配法で最適化を行うため、RLHFの高い計算コストや学習の安定性などの問題点を解決することができ、非常に注目を集めています。
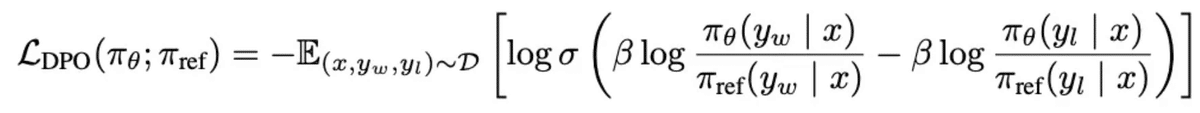

学習
実験は以下の設定で行いました。ただし、メモリ使用量を削減するために、量子化とLoRAを組み合わせたQLoRAを使用し、NF4量子化を採用してチューニングを行いました。また、DPOにはTRLのDPOTrainerを使用しています。
GPU: A100 1枚
learning_rate: 5e-6
train_batch_size: 4
eval_batch_size: 2
seed: 42
gradient_accumulation_steps: 4
lr_scheduler_type: cosine
num_train_epochs: 1
Dtype: bfloat16
optim: paged_adamw_8bit
この学習の結果、次のようなLossカーブとなり、最終的なLossの値は0.226になりました。

評価
Arena-Hard-Auto
DPO学習を実施した後、日本語力を評価します。この評価には、LLMを評価者として使用する方法であるLLM-as-a-judgeを採用し、Lightblueによって日本語向けに調整したArena-Hard-Autoという指標を使用します。既存の評価ベンチマークとしてJapanese MT-Benchなどがありますが、これらは既に多くのモデルで高いスコアが記録されており、モデル間の微細な性能さを十分に識別することが難しい状況です。そのため、より精緻にモデルの性能を評価できる新たなベンチマークの必要性を感じました。今回の評価では、ベースラインとしてQwen2.5-7B-Instructを選択し、このモデルのスコアを50.0と設定しました。DPO学習後のモデルがベースラインからどれだけ性能向上したかを明確に比較するために、この基準を用いました。その結果、DPO学習を経たモデルのスコアは50.0から66.2へと向上し、大幅な性能向上が確認されました。この成果は、DPO学習が日本語能力の向上に非常に有効であることを示しており、今後の日本語用大規模言語モデルの発展への応用可能性を強く示唆しています。
結論
今回は、既存の英語データセットを日本語に翻訳・改善することで構築した日本語データセットを使用し、DPOを実施しました。学習後のモデルは、Arena-Hard-Autoにおいてベースラインの50.0から66.2へと大幅に性能を向上させることに成功しました。今後の課題としては、さらに多様な評価指標の導入や他分野への応用検証を進めることで、モデルの総合的な性能向上と実用性の確立を目指していきます。