
【ついに9割!】共通テスト2025をChatGPTに解かせてみた

さて、今年も共通テストの季節がやってまいりました。
弊社では2023, 2024と大学受験 vs 生成AIをテーマに実験をしてきました。
今年はなんと、ついにAIが9割を超える得点をとり、いよいよAIのレベルの高さを認めざるを得ない結果となりました。
本記事ではAIによる回答結果の概観をご紹介します。
昨年度の記事はこちら↓
実験方法
解かせた科目は以下の6教科8科目です。
英語(リーディング・リスニング)
国語
数学(数学I,数学A・数学II,数学B,数学C)
社会(歴史総合,世界史探究・歴史総合,日本史探究)
理科基礎(地学基礎・生物基礎)
情報(情報1)
※ 英語リスニングは音声の公開がないため、スクリプトを直接入力に使用しています。
※ 国語の縦書き文章はうまく読み取れない場合が多いため、事前に外部ツールで文字起こししたデータを併用しました
モデル選定
今回は速度・精度の観点からOpenAI社のo1モデルを使用しました。
知識カットオフは2023年10月で、ブラウジング機能を持たないモデルのため、LLMモデル本体の知識での勝負となります。
また、コードインタープリター(pythonの実行ツール)もないモデルのため、計算もLLM本体に委ねられます。
具体的な手順
問題のスクリーンショットを張り付け。この時、画像以外の入力はしません。(国語のみ文字起こし結果を併用)
スクリーンショットを送信し、回答を出力させる。もし問題に回答しない場合、「問題に回答して」や「選択肢○○に当てはまる答えは何?」などを入力します。
スクリーンショットの認識が大きく誤っている場合は、該当箇所を抜き取り、再度入力。

実験結果
得点率は衝撃の91.3%を記録しました。
(913 / 1000点満点)
これは例年の共通試験のボーダーを参考にすると東大合格レベルの得点といえます。
昨年度と比較すると、全科目で点数がアップしました。特に、国語と数学の点数の伸びが大きく、数学1Aに至っては倍以上の成長を遂げました。

得点が伸びた要因
① 図表の読み取りができるようになった
一番大きいのはマルチモーダル化です。
昨年は手も足もでなかった図表の読み取りやイラストの問題に対応できるようになり、大きく点数を伸ばす要因となりました。
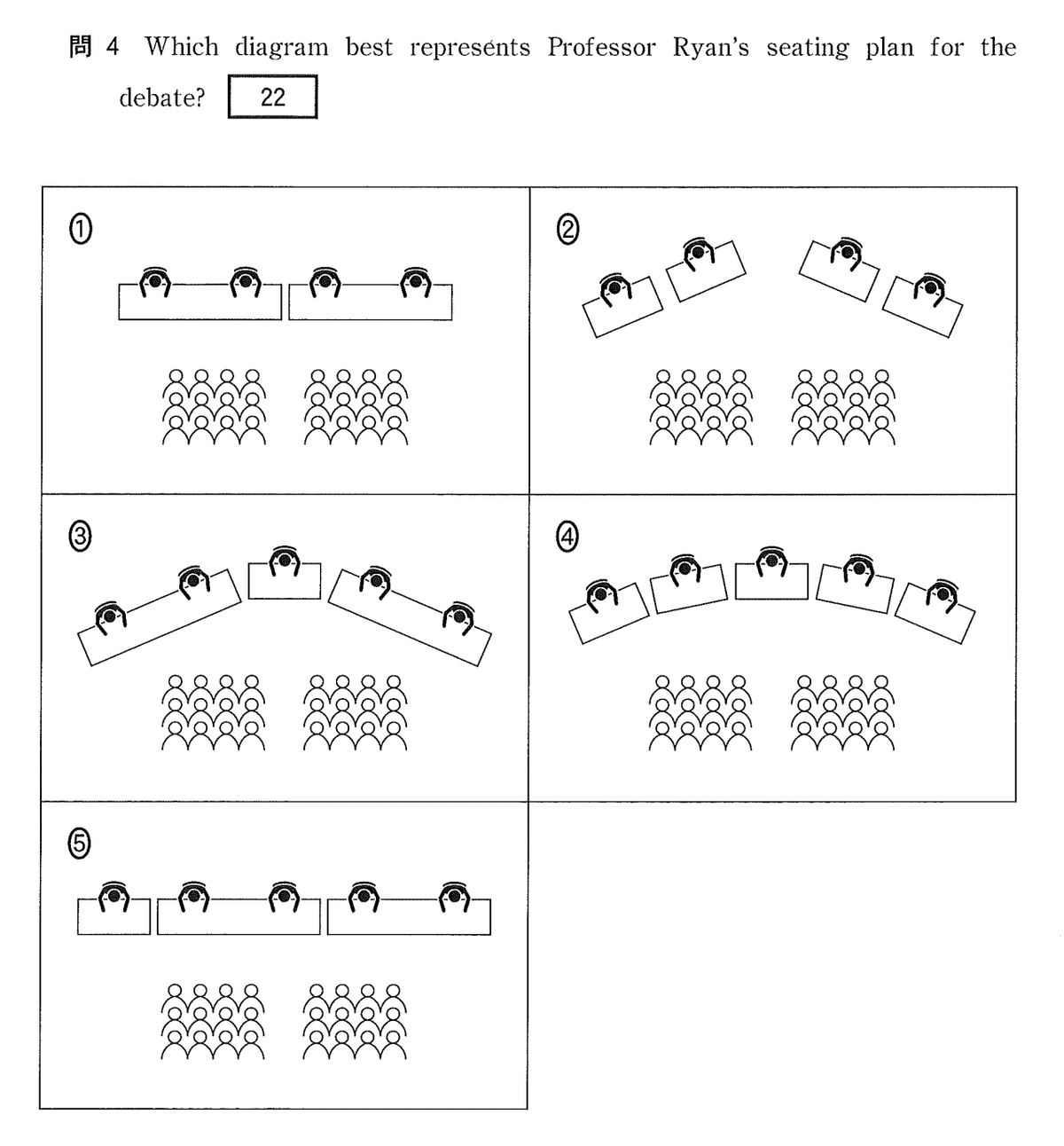
② 数理計算能力が向上した
昨年課題であった数学の計算について、圧倒的な成長を遂げています。
o1モデルはなんと現在、東大の数学でほぼ満点を取れるレベルまで計算能力が進化しています。

③ 言語モデル特有のミスが減った
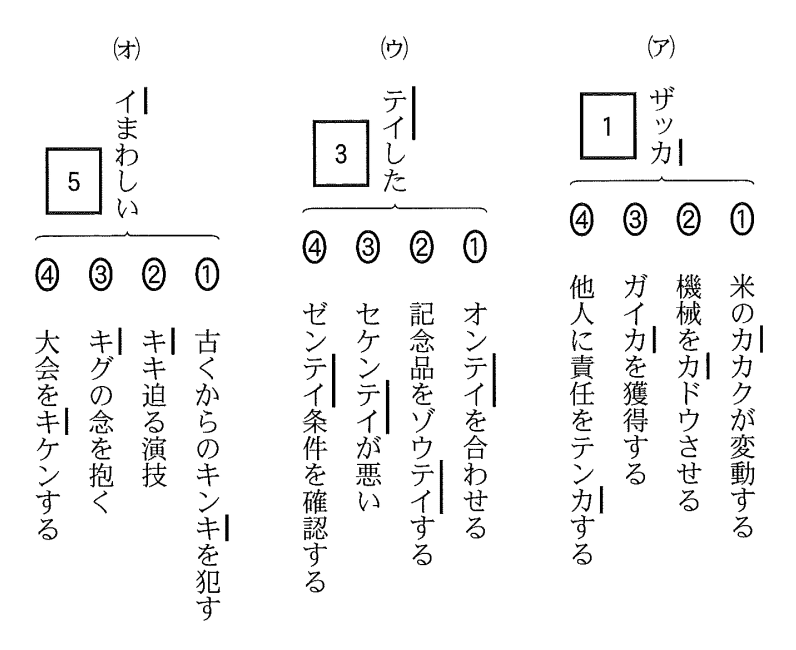
過去特徴的だったのが、現代文の第1問、漢字の問題を落としていたことです。
共通テストの漢字は選択肢から同じものを選択するという形式なのですが、言語モデルに体系的な知識がないため、漢字と読み仮名を結びつけるのが難しいようで、ミスが頻発していました。
今年は漢字問題は全問正解。ここをとっても精度が高まっていることがわかります。
点数を落とした問題
① 英語
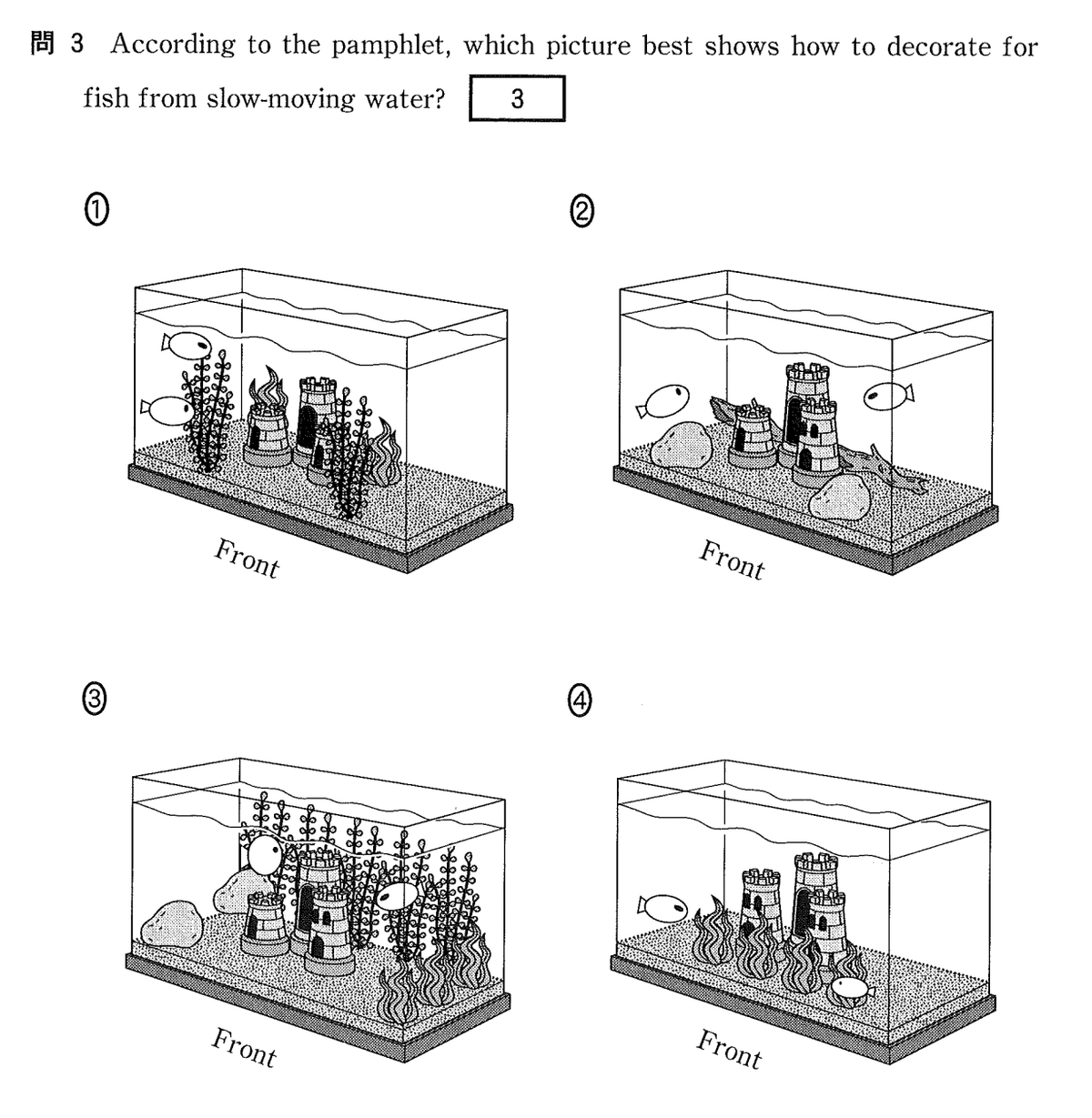
満点を取るのではないかと思われた英語リーディングですが、1問だけミスがあり、満点を逃しました。
その原因はイラスト問題にありました。大問1で、以下のような細かな違いしかないイラストの選択問題が出題されました。
この問題ではイラストの理解がうまくいかず、正答できませんでした。o1 proモデルを用いても同様のミスが発生しました。
② 数学1A vs 2BC
他と比べると伸び悩んだ数学1Aですが、今年は空間図形の問題が出題されました。
空間上の点を想像し、作図が求められるような問題であり、正しく点Pの位置をイメージすることができず、誤答が発生しました。
また、データの読み取り問題においてもグラフを正しく読み取れず、誤答となりました。
数学2BCにおいても、ミスの原因は極大と極小の混同やグラフの読み取り失敗であり、昨年多発した計算ミスはありませんでした。
③ 日本史 vs 世界史
昨年同様、日本史が低い傾向が続き、知識問題でのミスも見られました。
これは学習データの少なさに起因するのではないかと考えらます。世界史は英語文献も含めてデータが豊富であるのに対し、日本史は国内のデータが主です。
また、日本史は世界史に比べて範囲が狭い分、難しいことが問われる傾向にあることも、この結果の一因ではないかと考えられます。
④ o1 proを使ったらもっと良くなるのでは?
このような疑問を持たれる方も多いかと思いますが、「意外とそうでもない」というのが答えとなります。元々のミスが図表の読み取りや知識の部分が主であったためです。
英語や数学ではo1と同じく図表の読み取りミスが目立ち、pro modeで強化された思考の部分においては共通テストの範囲では大きな差分が見られませんでした。
まとめ
今回の得点は、AIの知能タスクにおける速度と正確性の進化を裏付ける結果となりました。
ただ、まだ10%はミスをするというのも事実であり、その傾向も今回浮き彫りとなりました。
実は、今年も東大受験企画が始動しており、今回の結果と併せて東大にチャレンジします。
ついにAIが東大合格となるのか、乞うご期待です。
最後に宣伝!
弊社では、「本当に使われるAIシステム」にこだわり、AIシステムの受託開発やコンサルティングを行っています。
AI活用でお困りの企業様、協業可能な企業様、ぜひご連絡をいただけますと幸いです。
また、AIの可能性を極限まで引き出す挑戦を一緒にしてくださる仲間も募集中です。
AIに興味のある方、まずはカジュアルにお話ししましょう!
最後まで読んでいただきありがとうございました!