
検索エンジンを自作する【みすてむずアドカレ】

みすてむず いず みすきーしすてむず Advent Calendar 2024
8日目の記事です!
みすてむずはIT関係の人が集うコミュニティ(SNS)で、この記事はその中で開催されたアドカレの記事です。
はじめに
こんにちは。これんじです。普段はTypescriptなどで何かを作ってます。
みすてむずに登録したのは1年ほど前で、ちょうど去年にアドカレの話を眺めていたと思います。
当時は予定通りに書ける自信がなかったので参加はしませんでしたが、来年は参加すると決めていました。
何を書くか悩みましたが、今回はWeb検索エンジンを作ることについて書くことにしました。
検索エンジン自作は前からやりたいと思っていたのですが、アドカレができたと聞いてこれやるか!と思ったので挑戦してみることにしました。
そして今回の記事でできたサイトは成果物として、記事と同時に一般公開します!
ですが、調子乗ってアドカレの最初のほうの日を取ってしまったので期間が1ヶ月ほどしかありません。
1ヶ月でサイトと記事の公開、果たして間に合うのでしょうか。検索エンジン作成マラソン、スタートです。
急いで書いたので読みづらいかもしれません🙇♂️
構成を錬る
今回はKoroo Searchという名の新たな検索エンジンを自作します。

今回作るるのはWebサイトのデータを集めるクローラーと、検索を行う本体であるWebサイトです。
技術スタックはNode、Typescript、pnpmなどを使い、pnpm workspacesでモノリポにします。
クローリングは対象ページに直接fetch()してもいいですが、今回はCSRなサイトにも対応したかったのでヘッドレスのChromeをNode.jsで操作できるライブラリのPuppeteerを使います。
PuppeteerをTypescriptで使う方法としてts-nodeというのが見つかりましたが、ESM/CJS関連のエラーでうまく動かなかったのでtsxというライブラリを使ってTypescriptを実行します。
(ここでのtsxはReactとかのやつではなく、Typescript Executeの略らしいです)
クローラーを作る
まずは検索対象となるサイトのデータを集めるために、クローラーを作っていきます。クローラーの挙動としては、
「キュー」を上から順にクロールしていく
ページのタイトル・説明・内容を収集する
※ noindexタグがあった場合は収集せずnoIndex: trueとしてDBに追加ページからのリンクを収集し、キューの最後に追加する
という感じのシンプルな仕組みです。
Robots.txtをパースせよ!
クローリングするにあたり、クロールされることを望まないサイトはクロールしないようにする対応が必要になります。
クロールしていいかの意思表示をするファイルとして、robots.txtというファイルがあります。サイト運営者はこれをサイトのルートに置くことでクローラーに意思を示しています。
これはは最初にルールを適用するクローラー名と、それに適用するルールが書いてある感じの書式です。
# こんな感じ
User-agent: * # 全てのUA
Disallow: /member/ # これで /member/ 以下のページ全て拒否となる
Allow: /member/terms/ # 深い階層Allowが優先
User-agent: Googlebot
Disallow: /no-googlebot/robots.txtをパースするライブラリなんていくらでもあるやろ!と思っていたのですが、いざnpmで探してみると多くはLast publishが数年前とかで、今メンテナンスされてるものは見つけられなかったです。
なので、今回はrobots.txtのパーサーを自作することにしました。
具体的な処理としては、
1行ずつ順番に
"User-agent"から始まる行があり、それが自分のことを指していたらフラグを立てる
フラグが立っている状態ではDisallowタグやAllowの内容を配列に追加する
という感じでDisallowとAllowのパスの配列を作って、`RobotsTxt`クラスでパースされた配列を見てクロールして大丈夫かを判断するようにしています。
(robots.isAllowed(url)みたいに確認できる!)
幸いそこまで難しい書式ではなかったのですごい大変な苦行だったりはしませんでした。
(ここまでの経過日数:20日ほど?)
クローラーを動かす
クローラーができたら実際にそれを動かしてデータを集めていきます。
最初は無料のVPSを使って動かそうと思って以下の2つを試しました。
Google Compute Engine の無料枠(e2-micro)
Oracle Cloud Infrastructure の無料枠
GCE (Google) の無料枠
まず最初に試したのがGCE (Google Cloud)で、こちらは2 vCPU、メモリ1GBのマシン(北アメリカリージョン)が無料で使えます。
ただ、これでしばらくクローラーを動かしているとCPU・メモリ使用率がマックスになり、Chromeの処理やDBへの通信がタイムアウトするようになってしまいました。
どうやらe2-microでChromeを動かすのは少しきつかったようです。GCEは諦めて他のサーバーを探しました。
とはいえGCEの無料枠は機会があったらまた何かで使いたいです。
(TCPプロキシとかで使おうかな?)
OCI (Oracle Cloud) の無料枠
次に試したのがOCI(Oracle Cloud)の無料枠で、無料で最大メモリ24GBのARMインスタンスが作れるというすごいところです。
試した結果は、メモリには余裕がありましたがCPU使用率がパンク気味で、時間が経つと同じように処理が遅くなったりして厳しかったです。
自分のPC
結局、サーバーでクローラーを動かすのをやめて家のPCで動かすことにしました。(24時間は動かせないけど仕方ない)
代わりに、DBのホスティングなどはOCIのインスタンスに任せることにしました。
ファイルがダウンロードされてしまう問題
クローラーを稼働したときに、クロールするURLが何らかのダウンロードページだった場合、クローラーを動かしているサーバーにファイルがダウンロードされてしまうという問題が見つかりました。
(見覚えのないファイルがあったので驚いた)
これだとクロール対象サイトにもしマルウェアなんかが仕込まれているとサーバーにダウンロードされてしまうということなので、セキュリティ的にまずいんじゃないかと思います。
(実行させる機能はないので多分環境は無事だと思われる)
対策として、こんな感じの実装を行いました。
const page = await browser.newPage();
const client = await page.createCDPSession();
await client.send('Page.setDownloadBehavior', {
behavior: 'deny'
});
const response = await page.goto(url); // 設定終わってからサイトにアクセスこれでChromeにダウンロード拒否することを表す信号?を送るみたいなことができるようです。
Puppeteerでダウンロードしない方法、調べても全然出てこなかったのでChatGPTに聞きました。やりたい人多そうなのに何故
クロール結果
クロール後の結果として351275ページ、10565サイトのデータが集まりました。
結構な量のデータが集まったんじゃないのかなと思いましたが、これで検索としての機能を果たせるのかは少し疑問です。
(ちなみに、Googleは2008年の情報で1兆以上のページを発見しているようです。天と地どころかマントルから月ぐらいの差があります。えぐい)
Webサイトを作る
検索エンジンの本体となるWebサイトを作ります。
サイトは前述の通りNuxtを使って作ります。
検索の仕組み
具体的な検索の方法は何も決まっていなかったのでChatGPTに聞いてみたところ、「SQLのILIKEで全文検索してから、Fuse.jsという検索ライブラリで結果を絞り込む」という方法を提案してくれたのでそれで作ります。
また検索を高速化するためにインデックスを作ったほうがいいとのことなので、PGroongaを使ってインデックスを作りました。
(最初はpg_trgmのGINインデックスでしたが、遅かったので日本語に強いと聞くPGroongaにしました)
結果の並び順はFuse.jsのスコア+外部リンクの数を両方加味して決めています。
ロゴデザイン

「Koroo Search」のロゴをFigmaで自作しました。「oo」の部分を目👀に見立てています。
またトップページでは👀がマウスカーソルを向くようにしています。
サイトに最初に入ったときに瞬きをしてから検索ボックスが表示されてるアニメーションをつけたのがお気に入りです。
フロントエンドを作る
Webサイトのフロントエンドを作ります。
最初の構成通りTailwind CSSでスタイリングしました。勢いで開発したのでメンテナンスしずらいスパゲッティコードができてしまいましたが、単なる記事の題材でアップデートとかいらなそうなのでまあ良しとします。
今更ですが、検索結果の表示にあたりクローラー側でサイトのファビコンも取得しておくべきだったと後悔しました。
今回はicon.horseというサイトからファビコンを出してくれるAPIを使ってフロントエンドから取得することにしました。
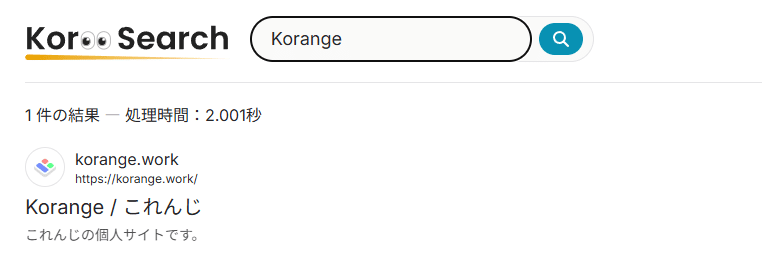
サイトができる前にBentoのプロフィールへのリダイレクト設定をしていたからだと思われる
(ここまでの経過日数:32日ほど)
試してみる
できた検索エンジンの使い勝手を実際に検索して確かめてみます。
「記事」で検索
Webでよく使われそうな言葉なのでやりました。「記事一覧ページ」などがヒットしています。
こういった一覧ページのようなサブページではなく本当に「記事」を書いたページがヒットしてほしかったですが、一応「検索」することはできているのでまあ良しとします。

「会社」で検索
会社概要や企業ブログなどのページが多くヒットしました。
これも本来は「会社」の意味などがヒットしてほしいですが、データ数が少なすぎるので難しかったですかね
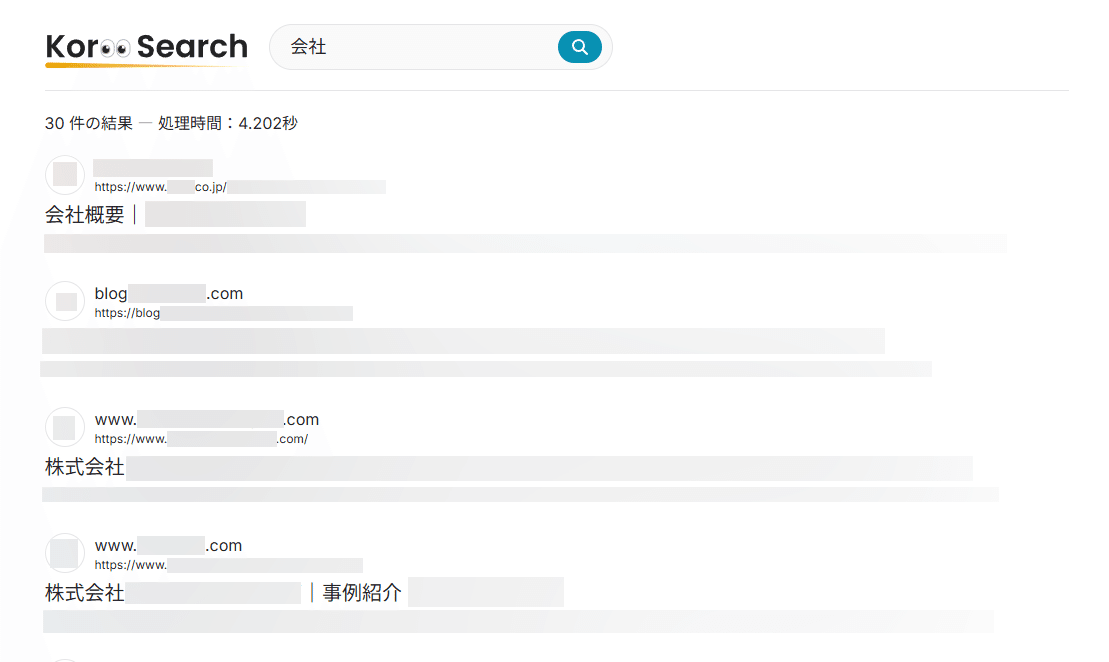
ここまでは割とちゃんと動いていますね。(実用性はともかく)
2つのワードでの検索
2つのワードでの検索もやってみます。
(検索ワード:「茨城 釣り」)

uum… あまりワードにあった結果とは言えないものが出てきました。
サイトの中身を見ると「茨城」の気象予報が含まれていて、フッターに「釣り」の単語が1つだけ含まれていました。
このような結果の理由としてはデータ量が少なすぎる(茨城の釣りの情報がクロールされていない)のだと思われます。
また他のワードでも検索してみましたが、地名を含む会社名や、人名に含まれる漢字などでかなりクエリに合わない結果が出てくる比率が高かったです。
やっぱり通常の調べ物としての用途には使い物にならないようです。
もっとクロールしたり検索を改善する余地があるかもしれませんが、投稿日までの日数的に厳しそうなのでこれでOKとします。
(一応Webからサイトを「検索」することはできているから:yoshi:?)
ホスティング
最後にサイトをインターネットにホスティングします!
なおこれを書いているのは記事公開前日の12/07です。やばいです。
ホスティングにはNuxt Hubというサービスを使おうと思っていたのですが、試してみたらサーバーを起動できなかったです。
原因としては、このプロジェクトはpnpm+モノリポ構成でPrismaClientを「db」という1つのパッケージとして持っているので、ただ単にビルドディレクトリを設定するだけじゃ動かないっぽいです。
そもそもNuxt Hubがnpmを使っているのか、どういったコマンドでホスティングしているのかもよくわからなかったので、今回はクローラーのホスティングで使おうとしていたOCIのインスタンスを使ってホスティングしました。
そして…
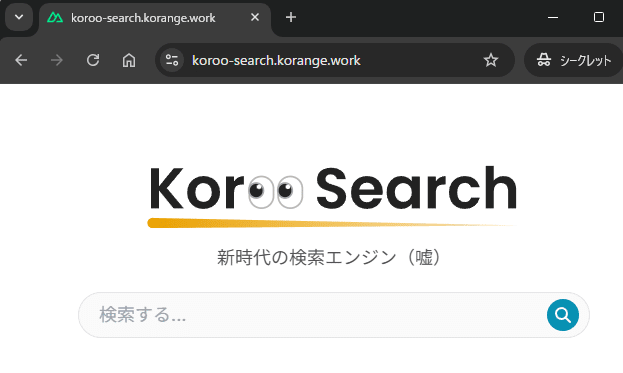
Web上からアクセスできるようになりました。
作った検索エンジンがWeb上で誰でも使えるようになったので、検索エンジン「Koroo Search」はこれにて完成とします!🎉
おわりに
ということで検索エンジン、無事に完成することができました。(ギリギリ)
とても普段使いできるようなものではありませんが、一応動くものができたので良しとします。
またPostgres、PrismaやTypescriptなど、今年覚えた技術の集大成(?)的なものができたのはよかったです。
あとSQL(クエリ言語)を初めて使いました。ほぼChatGPT任せで自分で書いてないけど、なんとなく書き方がわかりました。
最後に、今回作ったサイトはここで期間限定?公開中です!
(インスタンスを他で使う予定が立ったら公開をやめると思います)
見てくれてありがとうございました。では。