<学習シリーズ>Pytorchの転置畳み込み(ConvTranspose2d)の確認

1.概要
本記事は”学習シリーズ”として自分の勉強備忘録用になります。
Pytorch内のメソッドとして畳み込み演算(Conv2d)があり、画像処理で物体検出などに使用されます。今回は画像生成モデルのGANで使用される転置畳み込みについて紹介します。
本記事の内容は下記参考にしました。
2.ConvTranspose2dの説明
2-1.転置畳み込みとは?
転置畳み込みとは特殊な畳み込みで画像サイズを拡大する処理です。通常の畳み込みでは出力画像のサイズは入力と同じかそれ以下になりますが、転置畳み込みでは出力画像のサイズが入力画像より大きくなります。
使用例としてGAN(生成器)のように1次元のベクトルから転置畳み込みで出力を拡大することで画像を生成するような場面で使用します。

DCGAN (Deep Convolutional GAN):畳み込みニューラルネットワークによる敵対的生成 | NegativeMindException
2-2.転置畳み込みの動作概要
転置畳み込みの大まかな動作としては下記の通りです。
入力画像のピクセル間(各数値の間)に指定したストライドやパディングの値に応じて数値(0)を埋めて、処理用画像※を作成する(※Defaultでは処理用画像サイズ≠出力画像であることに注意)。
処理用画像を通常の畳み込み演算することで出力画像を作成する。
詳細に関しては次章で説明しますが参考例を下図に示します。入力(2×2)を転置畳み込みすることで出力(3×3)に拡大できます。
2-3.ConvTranspose2dのパラメータ・計算式
Pytorchで転置畳み込みを実装する場合は"ConvTranspose2d"メソッドを使用します。各種パラメータは以下の通りです。
[ConvTranspose2dメソッド]
torch.nn.ConvTranspose2d(in_channels, out_channels, kernel_size,
stride=1, padding=0, output_padding=0,
groups=1, bias=True, dilation=1,
padding_mode='zeros', device=None, dtype=None)【ConvTranspose2d】
●in_channels (int):入力画像のチャネル数
●out_channels (int):出力画像のチャネル数
●kernel_size (int or tuple):畳み込み演算のカーネルサイズ
●stride (int or tuple, optional):ストライド Default: 1
●padding (int or tuple, optional):パディングの幅を決めるための係数(パディング幅=dilation * (kernel_size - 1) - padding). Default: 0
●output_padding (int or tuple, optional):出力の形状に対して、片側の幅・高さ方向にパディングを追加(通常のパディングは両側). Default: 0
●groups (int, optional):Number of blocked connections from input channels to output channels. Default: 1
●bias (bool, optional):Trueならバイアス値(学習用パラメータ)を追加 Default: True
●dilation (int or tuple, optional):カーネル間のスペースサイズを指定(拡張畳み込み) Default: 1
【計算式】
N:データ数
$${C_{in}}$$:入力値画像のチャネル数、$${H_{in}}$$:入力値画像のHeight、$${W_{in}}$$:入力値画像のWidth
$${C_{in}}$$:出力値画像のチャネル数、$${H_{in}}$$:出力値画像のHeight、$${W_{in}}$$:出力値画像のWidth
$$
処理用画像にかかるパディング=dilation×(kernel size-1)-padding
$$
$$
H_{out}=(H_{in}-1)×stride-2×padding+dilation×(kernel size-1)+output_padding+1
$$
$$
W_{out}=(W_{in}-1)×stride-2×padding+dilation×(kernel size-1)+output_padding+1
$$
3.動作概念の確認
動作検証をしますが固定するパラメータの初期条件は下記の通りです。また参考として通常の畳み込みと転置畳み込みの動作比較を記載しました。
固定値:dilation=1、output_padding=0, bias=False(※値=0)
$$
処理用画像にかかるパディング=dilation×(kernel size-1)-padding=(kernel size-1)-padding
$$
3-1.Stride
Strideの動作は下記の通りです。
畳み込み(Conv2d):カーネル(フィルター)の移動幅
転置畳み込み(ConvTranspose2d):入力値の間を0で埋めるセル数であり$${セル数=Stride-1}$$で計算される。
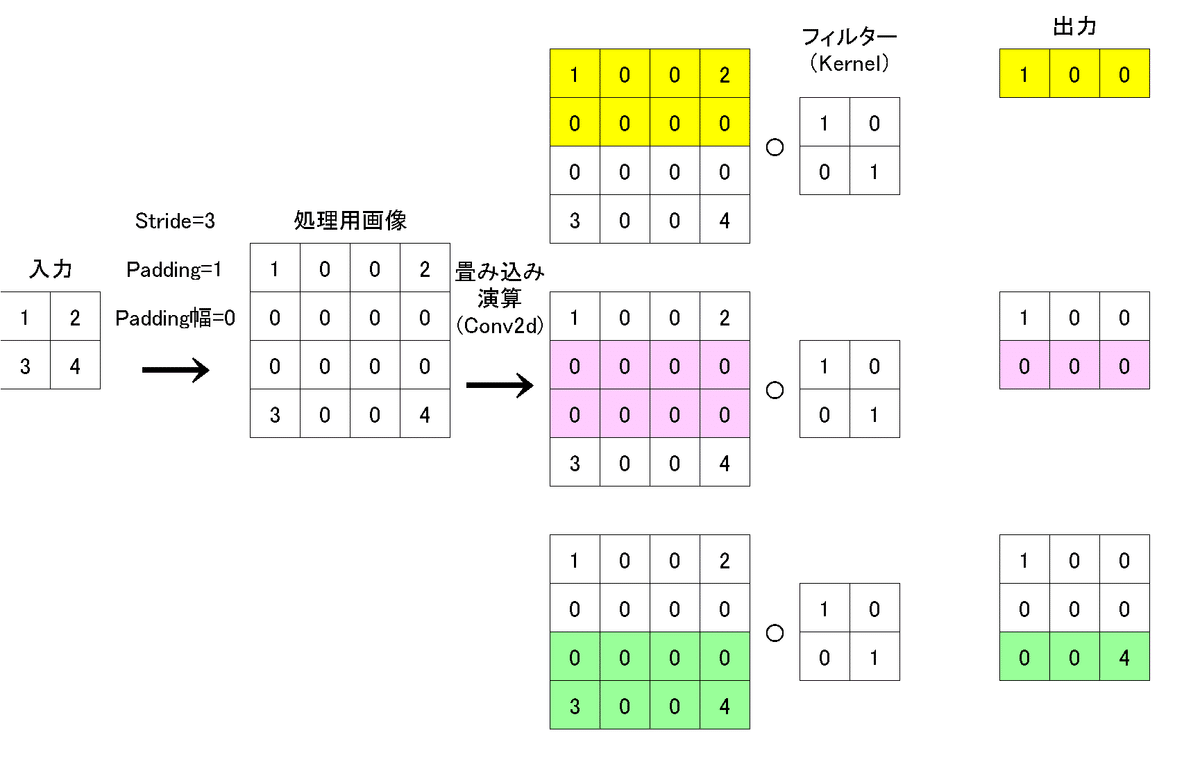
下記の例として転地畳み込みのstride=2にすると$${隙間埋めのセル数=stride-1=1}$$より下図の通りとなる。

stride=3だと下記の通りです。

3-2.Padding
Paddingの動作は下記の通りです。
畳み込み(Conv2d):入力画像の周辺(両側の幅・高さ方向)に指定した数値を埋める処理(一般的なのは0を埋めるゼロパディング)
転置畳み込み(ConvTranspose2d):前節で説明したstride(転地畳み込み)処理後の値にゼロパディングをする。そのパディング幅は下記計算式で算出される。
$$
処理用画像にかかるパディング=dilation×(kernel size-1)-padding=(kernel size-1)-padding
$$
padding=0, kernel_size=2の時$${パディング幅=1×(2-1)-0=1}$$より、下図の通り幅1のゼロパディングが入ります。

3-3.output_padding
output_paddingは畳み込みには無く、転地畳み込み用のメソッドです。処理としては前節のstride, padding処理後に片側の幅・高さ方向のみにゼロパディングを追加します。

4.コード検証
本章では実際にコードを記載して動作検証します。なお出力サイズの計算に関して正方形を使用するためHeightのみ記載しました。
記載のない引数Default:dilation=1、output_padding=0, bias=Falseです。
4-1.strideの検証1(st=2, pad=1)
入力画像(N=1,C=1,H=2,W=2)、カーネル(2,2)、stride=2, padding=1とした時の結果は下記の通りです。
この条件だと入力と出力のサイズは同じになります。
$$
H_{out} \\
=(H_{in}-1)×stride-2×padding+dilation×(kernel size-1)+output_padding+1 \\
=(2-1)×2-2×1+1×(2-1)+0+1 \\
=2
$$
[IN]
import torch
import torch.nn as nn
tensor = torch.tensor([[[[1, 2],
[3, 4 ]]]]).float()
conv_trans = nn.ConvTranspose2d(1, 1, kernel_size=2,
stride=2, padding=1, bias=False)
print(conv_trans)
with torch.no_grad():
conv_trans.weight = nn.Parameter(torch.tensor([[[[1, 0],
[0, 1]]]]).float()) #Kernelの初期値を修正
conv_trans(tensor) #転置畳み込み
[OUT]
ConvTranspose2d(1, 1, kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), bias=False)
tensor([[[[1., 0.],
[0., 4.]]]], grad_fn=<SlowConvTranspose2DBackward>)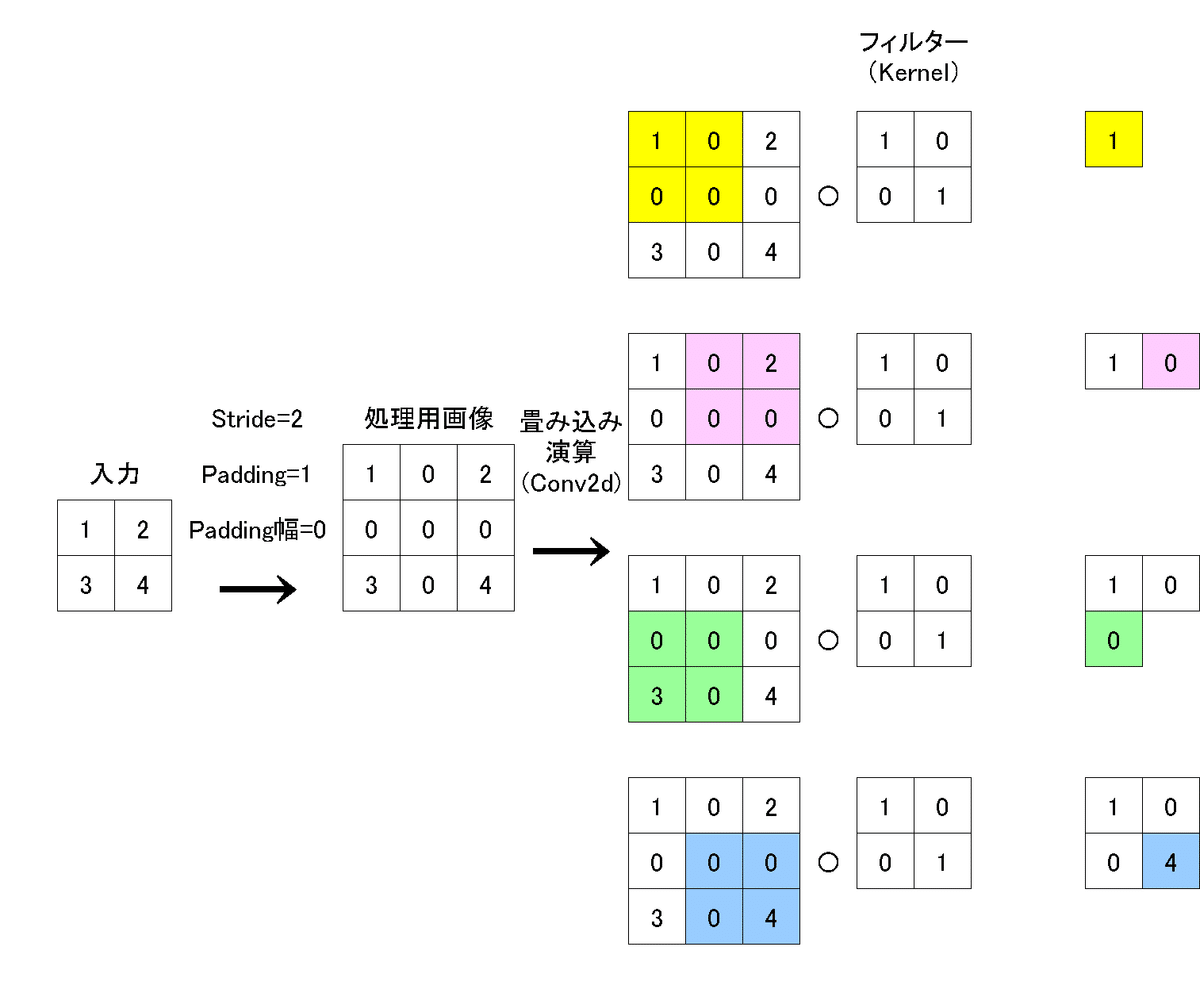
4-2.strideの検証2(st=3, pad=1)
入力画像(N=1,C=1,H=2,W=2)、カーネル(2,2)、stride=3, padding=1とした時の結果は下記の通りです。
この条件だと出力のサイズは拡大されました。
$$
H_{out} \\
=(H_{in}-1)×stride-2×padding+dilation×(kernel size-1)+output_padding+1 \\
=(2-1)×3-2×1+1×(2-1)+0+1 \\
=3
$$
[IN]
import torch
import torch.nn as nn
tensor = torch.tensor([[[[1, 2],
[3, 4 ]]]]).float()
conv_trans = nn.ConvTranspose2d(1, 1, kernel_size=2,
stride=3, padding=1, bias=False)
print(conv_trans)
with torch.no_grad():
conv_trans.weight = nn.Parameter(torch.tensor([[[[1, 0],
[0, 1]]]]).float()) #Kernelの初期値を修正
conv_trans(tensor) #転置畳み込み
[OUT]
ConvTranspose2d(1, 1, kernel_size=(2, 2), stride=(3, 3), padding=(1, 1), bias=False)
tensor([[[[1., 0., 0.],
[0., 0., 0.],
[0., 0., 4.]]]], grad_fn=<SlowConvTranspose2DBackward>)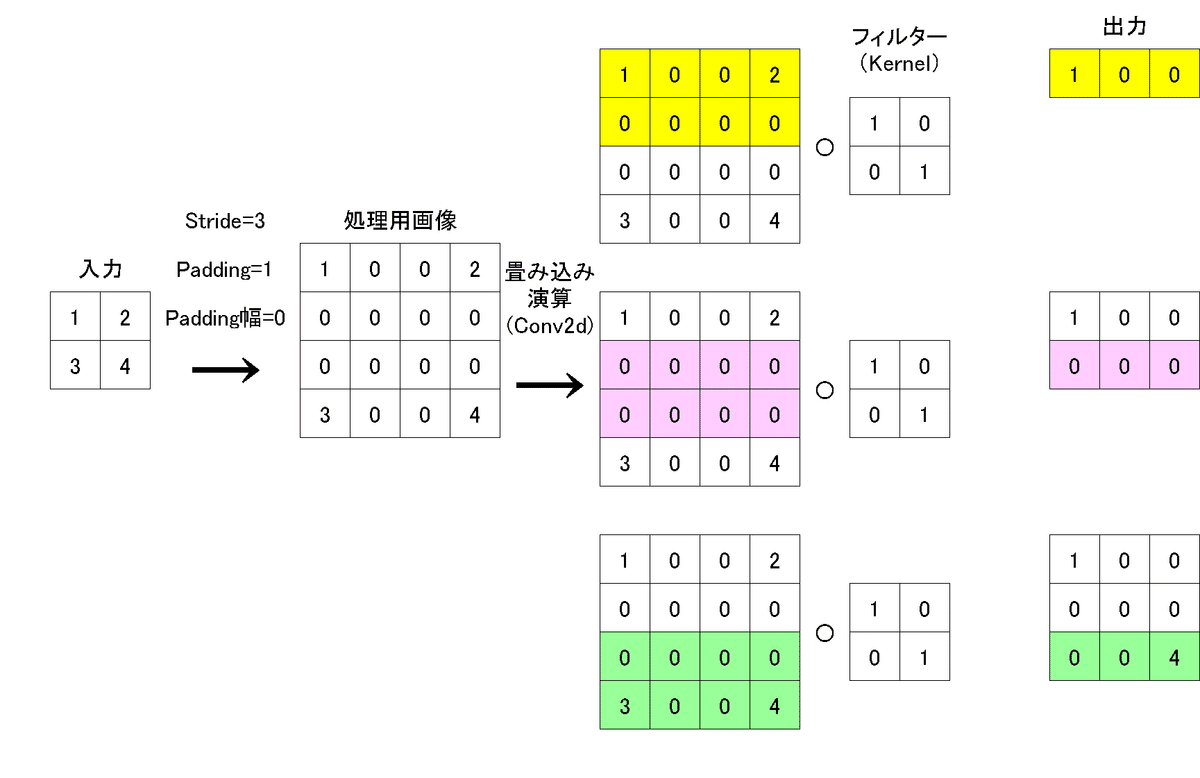
4-3.Paddingの検証(st=2, pad=0)
入力画像(N=1,C=1,H=2,W=2)、カーネル(2,2)、stride=2, padding=0とした時の結果は下記の通りです。padding=1だと”入力と出力のサイズは同じ”でしたが、padding=0にすると出力のサイズが拡大しました。
$$
H_{out} \\
=(H_{in}-1)×stride-2×padding+dilation×(kernel size-1)+output_padding+1 \\
=(2-1)×2-2×0+1×(2-1)+0+1 \\
=4
$$
[IN]
import torch
import torch.nn as nn
tensor = torch.tensor([[[[1, 2],
[3, 4 ]]]]).float()
conv_trans = nn.ConvTranspose2d(1, 1, kernel_size=2,
stride=2, padding=0, bias=False)
print(conv_trans)
with torch.no_grad():
conv_trans.weight = nn.Parameter(torch.tensor([[[[1, 0],
[0, 1]]]]).float()) #Kernelの初期値を修正
conv_trans(tensor) #転置畳み込み
[OUT]
ConvTranspose2d(1, 1, kernel_size=(2, 2), stride=(2, 2), bias=False)
tensor([[[[1., 0., 2., 0.],
[0., 1., 0., 2.],
[3., 0., 4., 0.],
[0., 3., 0., 4.]]]], grad_fn=<SlowConvTranspose2DBackward>)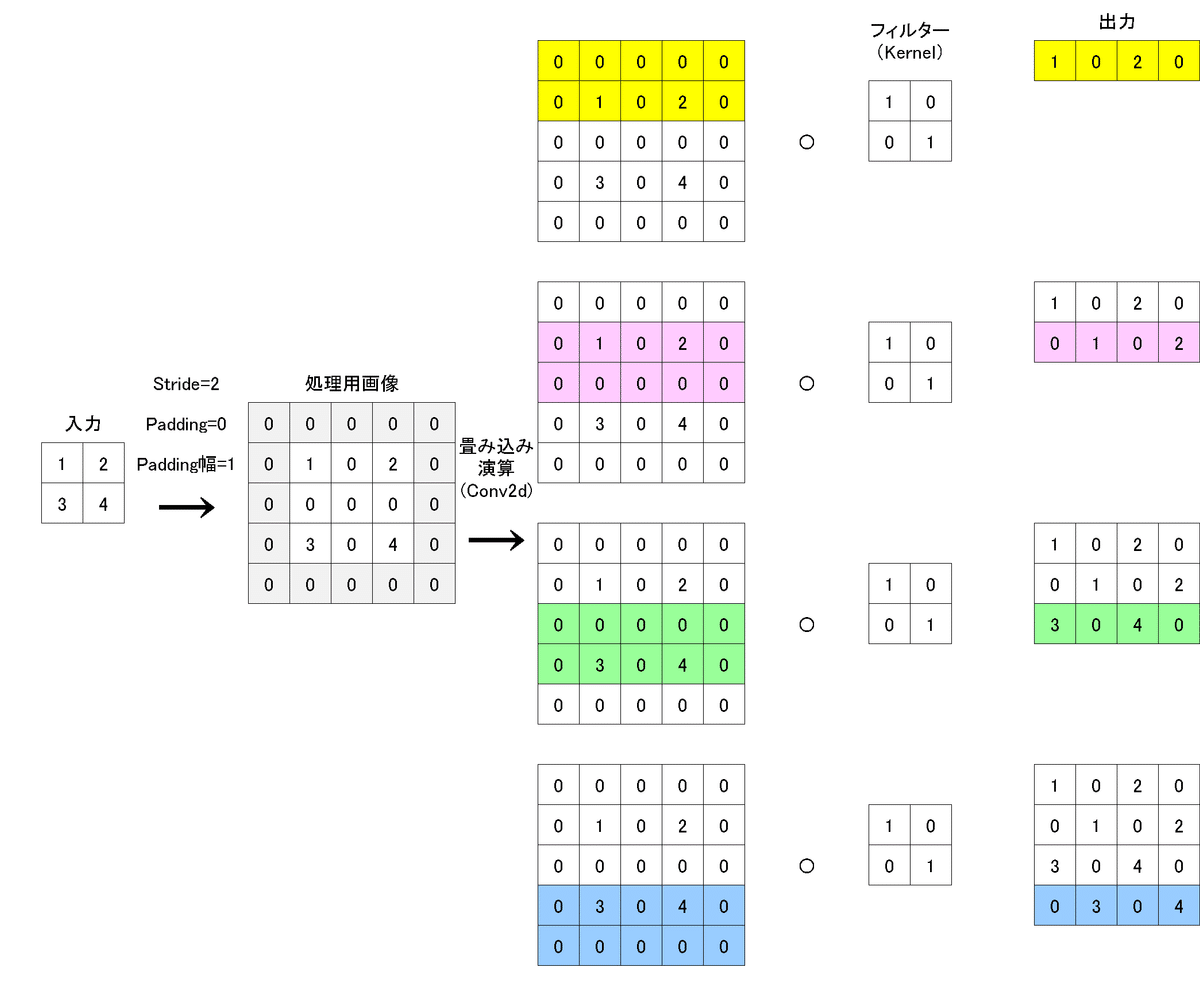
4-4.output_paddingの検証1(st=2, pad=1, out_p=1)
入力画像(N=1,C=1,H=2,W=2)、カーネル(2,2)、stride=2, padding=1, output
_padding=1とした時の結果は下記の通りです。
output_padding=0(default)だと”入力と出力のサイズは同じ”でしたが、1にするとサイズが一つ大きくなるため出力サイズも1大きくなりました。
$$
H_{out} \\
=(H_{in}-1)×stride-2×padding+dilation×(kernel size-1)+output_padding+1 \\
=(2-1)×2-2×1+1×(2-1)+1+1 \\
=3
$$
[IN]
import torch
import torch.nn as nn
tensor = torch.tensor([[[[1, 2],
[3, 4 ]]]]).float()
conv_trans = nn.ConvTranspose2d(1, 1, kernel_size=2,
stride=2, padding=1, bias=False,
output_padding=1)
print(conv_trans)
with torch.no_grad():
conv_trans.weight = nn.Parameter(torch.tensor([[[[1, 0],
[0, 1]]]]).float()) #Kernelの初期値を修正
conv_trans(tensor) #転置畳み込み
[OUT]
ConvTranspose2d(1, 1, kernel_size=(2, 2), stride=(2, 2), padding=(1, 1), output_padding=(1, 1), bias=False)
tensor([[[[1., 0., 2.],
[0., 4., 0.],
[3., 0., 4.]]]], grad_fn=<SlowConvTranspose2DBackward>)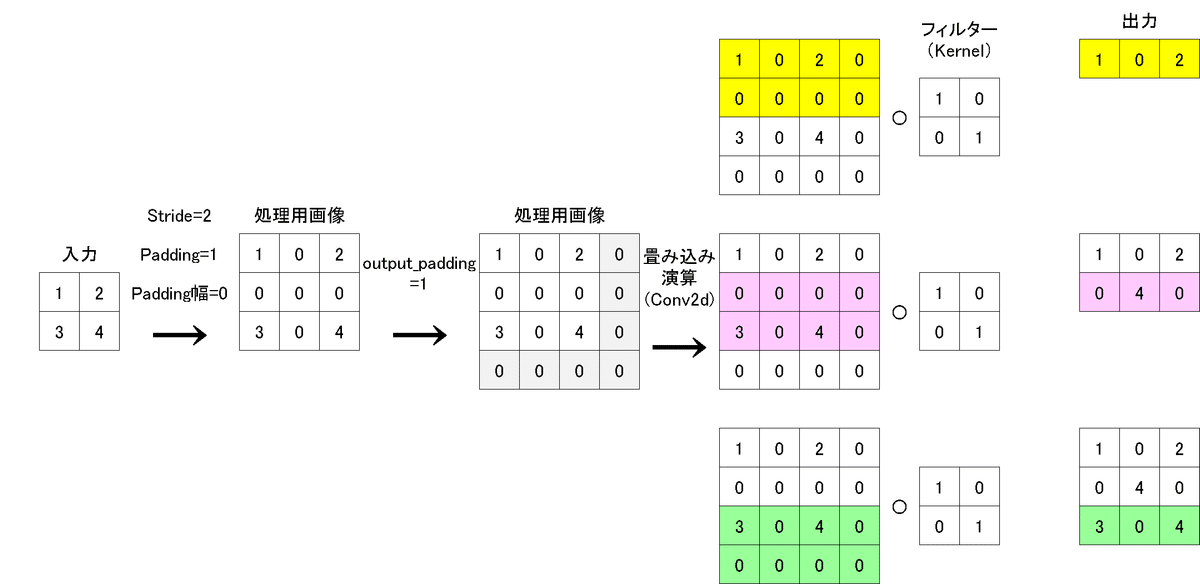
参考資料
DCGAN (Deep Convolutional GAN):畳み込みニューラルネットワークによる敵対的生成 | NegativeMindException
あとがき
ここからGANを勉強したいけど2022年8月のStable DiffusionからGANとは別のモデルが流行ってきたので、とりあえず基礎部分だけでも押さえておきたい。