
Python(機械学習編):Pandas

概要
pandasは主にCSVやExcelなどの表データを加工するライブラリです。
今回はサンプルとして時系列データを使用しており下記参照しました。
1. 仮想通貨の終値・SQ 一覧 - bitFlyer:仮想通貨の日時データ
2. 仮想通貨(暗号通貨)4本値CSVゲッター from Cryptowatch:BTC1min
なお本記事ではDataFrameを並列表示するため下記クラスを使用します。
[IN]
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return ''.join(template.format(a._repr_html_()) for a in self.args)1.基本操作1
1-1.Pandas配列:Series型/DataFrame型
Pandasは2つの型がありSeries型とDataFrame型(df)となります。各型の操作は基本的に同じため以後dfをメインに説明します。
データ作成はデータはリストやNumpy配列を渡して作成します。DataFrameの場合はカラム名と合わせて辞書型でも作成可能です。
【Series:1次元配列】
Indexを含む1次元配列でありIndex(行名)からデータ取得可能です
【DataFrame:2次元配列(行列)】
行列型データでありIndexとColumn(列名)を指定してデータ抽出が可能です
[In]
import pandas as pd
import numpy as np
series = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
# series = pd.Series(np.array([1, 2, 3]), index=['A', 'B', 'C']) #Numpyで作成->結果は上記と同じ
# series = pd.Series([1, 2, 3], index=['A', 'B', 'C']) #リストで作成->結果は上記と同じ
[Out]
A 1
B 2
C 3[In]
df = pd.DataFrame({
'C1': [1, 2, 3],
'C2': [4, 5, 6],
'C3': [7, 8, 9]
}, index=['A', 'B', 'C']) #下記と同じ出力
df = pd.DataFrame(data=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['A', 'B', 'C'], columns=['C1', 'C2', 'C3'])df = pd.DataFrame(data=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['A', 'B', 'C'], columns=['C1', 'C2', 'C3'])
display(df) #Jupyterならprint()ではなくdisplay()で綺麗に表示可能
[Out]
C1 C2 C3
A 1 2 3
B 4 5 6
C 7 8 91-2.データの表示法:df.head(), df.tail()
dfは大量データを扱うため部分的に確認する時は、データの上から指定行数表示させるのはdf.head()、下からはdf.tail()となります(デフォルト=5)。
[In]
df = pd.DataFrame(data=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['A', 'B', 'C'], columns=['C1', 'C2', 'C3'])
df.head(2)
df.tail(2)
[Out]
左:df.head(2) 、右:df.tail(2)
1-3.配列の情報取得:dtype, shape, ndim, size
配列の基礎情報を取得します。なお別章では統計情報取得も紹介します。
【データ情報取得】
●dtype:配列内のデータ型 ※Seriesのみ->DataFrameはエラー
●shape:データ配列の形状
●ndim:配列の次元数
●size:配列全体のパラメータ数
●index:インデックス名
●columns:カラム名※DataFrameのみ->Seriesはエラー
[In] Series型
series = pd.Series([1, 2, 3], index=['A', 'B', 'C'])
print(series.dtype) #データ型
print(series.shape) #形状
print(series.ndim) #次元
print(series.size) #要素数
print(series.index) #インデックス情報
[Out]
int64
(3,)
1
3
Index(['A', 'B', 'C'], dtype='object')[In]
df = pd.DataFrame(data=[[1, 2, 3], [4, 5, 6], [7, 8, 9]], index=['A', 'B', 'C'], columns=['C1', 'C2', 'C3'])
print(df.shape) #形状
print(df.ndim) #次元
print(df.size) #要素数
print(df.index) #インデックス名
print(df.columns) #カラム名
[Out]
(3, 3)
2
9
Index(['A', 'B', 'C'], dtype='object')
Index(['C1', 'C2', 'C3'], dtype='object')1ー4.データ型の変換:df.astype(型)
データ型を変更する場合はastype()メソッドを使用します。詳細は下記記事が分かりやすいです。
[In]
series.astype(float)
[Out]
A 1
B 2
C 3
dtype: float64[In]
df.astype(float)
[Out]
C1 C2 C3
A 1 2 3
B 4 5 6
C 7 8 91-5.Numpy配列変換:df.values/df.to_numpy()
Pandas->Numpy型変換する時はdf.valuesまたはdf.to_numpy()を使用します。推奨はdf.to_numpy()です(What’s New in 0.24.0)。
[In]
df.values #Numpy取得※古いAPIのため下記推奨
df.to_numpy() #Numpy型に変換
print(type(df_numpy), df_numpy)
[Out]出力はどちらも同じ
<class 'numpy.ndarray'>
array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]], dtype=int64)2.基本操作2:データの読み込み/出力
2-1.ファイルの読み込み:pd.read_xxx(path)
2-1-1.テーブルデータ(CSV/Excel)の読み込み
Pandasはテーブルデータをpd.read_xxx(filepath)で取得できます(選択肢は自動補完でご確認ください)
[pandas.read_csv]
pandas.read_csv(filepath_or_buffer, *, sep=_NoDefault.no_default, delimiter=None,
header='infer', names=_NoDefault.no_default, index_col=None,
usecols=None, squeeze=None, prefix=_NoDefault.no_default,
mangle_dupe_cols=True, dtype=None, engine=None, converters=None,
true_values=None, false_values=None, skipinitialspace=False,
skiprows=None, skipfooter=0, nrows=None, na_values=None,
keep_default_na=True, na_filter=True, verbose=False,
skip_blank_lines=True, parse_dates=None, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True,
iterator=False, chunksize=None, compression='infer', thousands=None,
decimal='.', lineterminator=None, quotechar='"', quoting=0,
doublequote=True, escapechar=None, comment=None, encoding=None,
encoding_errors='strict', dialect=None, error_bad_lines=None,
warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False,
low_memory=True, memory_map=False, float_precision=None, storage_options=None)【参考:CSVファイル取得時のポイント】
●元データがきれいな場合はカラムが自動で設置される。
●日付データはdatetime型で読む方がよいためdate_parserで指定
●index_colで指定カラムをIndexに指定できる。
●文字化けしたらencoding=に'utf-8', 'shift-jis', 'cp932'のどれか入れればOK
[In]
df = pd.read_csv('Prices_2021_08_20211003_bitFlyer.csv', date_parser=[0]) #date_parserで指定列:0列目をdatetime型で読み込む
print(df.shape)
df.index.values #Indexの表示
display(df)
[Out]
(31, 29)
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30], dtype=int64)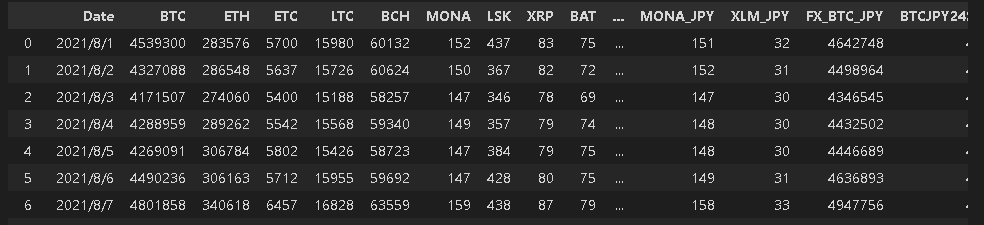
下記ではIndexを指定して読み込みました。
[In]
[Out]
(31, 29)
DatetimeIndex(['2021-08-01', '2021-08-02', '2021-08-03', '2021-08-04','2021-08-05', '2021-08-06', '2021-08-07', '2021-08-08','2021-08-09', '2021-08-10', '2021-08-11', '2021-08-12','2021-08-13', '2021-08-14', '2021-08-15', '2021-08-16',
'2021-08-17', '2021-08-18', '2021-08-19', '2021-08-20','2021-08-21', '2021-08-22', '2021-08-23', '2021-08-24','2021-08-25', '2021-08-26', '2021-08-27', '2021-08-28','2021-08-29', '2021-08-30', '2021-08-31'],
dtype='datetime64[ns]', name='Date', freq=None)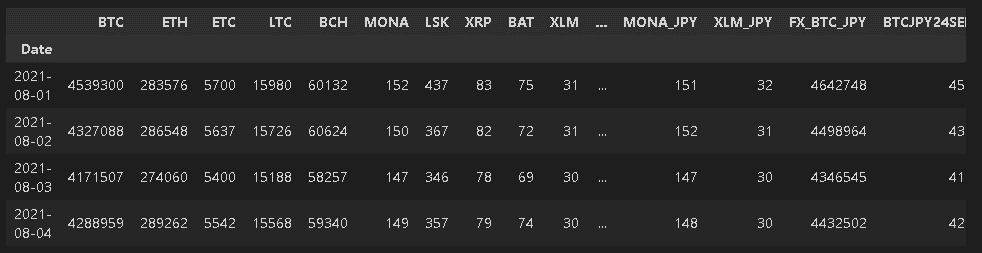
【参考資料】
2-1-2.Pickleファイルの読み込み:read_pickle()
Pickleファイルの読み込みは"read_pickle"を使用します。適用例として大量のデータがあるCSVを読み込むと数分かかることがあります。この場合一度Pickleで保存しておくと、読み出しを高速化できます。
[API]
pandas.read_pickle(filepath_or_buffer, compression='infer', storage_options=None)2-1-3.Webサイトの<table>取得:read_html()
Webサイト内にある<table>タグのデータをDataFrameで取得する手法としてpd.read_html(<url>)があります。ポイントとしては指定URLからtableタブをスクレイピングするためtableタブの数だけDataFrameを取得して、リストにまとめたものを出力します。
[IN]
url = 'https://coinmarketcap.com/ja/'
datas = pd.read_html(url)
print(type(datas), len(datas))
for data in datas:
display(data)
[OUT]
<class 'list'> 1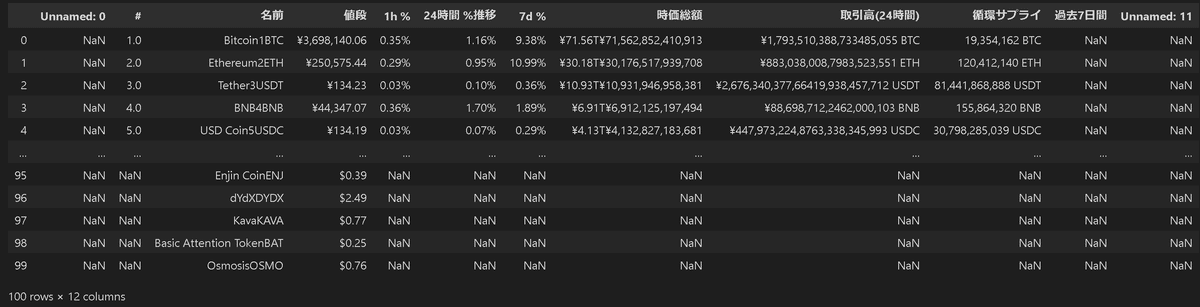
2-2.データの保存:to_xxx(path)
作成したDataFrameはdf.to_XXX(filepath)で出力可能です。
2-2-1.テーブル形式(Excel・CSV)で出力
[IN]
df.to_csv('./outputfile.csv') #CSV用
df.to_excel('./outputfile.xlsx') #Excel用
df.to_excel('./outputfile.xlsx', index=False, header=False) #Excel用, index、ヘッダーを除去CSVでは良く文字化けすることがあるため引数の"encoding"に”shift-jis”を設定したり、エラーが消えない場合は"errors='ingnore'"を設定する
[IN ※サンプル]
df.to_csv('./outputfile.csv', encoding='shift-jis')
df.to_csv('./outputfile.csv', encoding='shift-jis', errors='ignore')2-2-2.Pickleで出力:pd.to_pickle()
データをPickleファイルで出力するには"pd.to_pickle()"を使用します。大容量データを毎回CSVファイルから読み出す時間がもったいない場合などは、一度pickleファイルで保存して"read_pickle()"とすることで高速化できます。
[API]
DataFrame.to_pickle(path, compression='infer', protocol=5, storage_options=None)2-2-3.HTMLで出力:pd.to_html()
DataFrameに保存されている画像のURLからファイルをダウンロードせずにJupyterに画像出力する場合などに使用できます。
[IN]
import pandas as pd
from IPython.display import HTML
# NOTE: https://www.irasutoya.com/2021/01/onepiece.html から画像を参照
onepiece = {
"モンキー・D・ルフィ" : "https://1.bp.blogspot.com/-uxIsaN0S5lQ/X-FcrvAAInI/AAAAAAABdD4/6uw_qNUh9dQrG0aUzIExybt84yTEmXOPwCNcBGAsYHQ/s200/onepiece01_luffy.png",
"ロロノア・ゾロ" : "https://1.bp.blogspot.com/-rzRcgoXDqEg/YAOTCKoCpPI/AAAAAAABdOI/5Bl3_zhOxm07TUGzW8_83cXMOT9yy1VJwCNcBGAsYHQ/s200/onepiece02_zoro_bandana.png",
"ナミ" : "https://1.bp.blogspot.com/-2ut_UQv3iss/X-Fcs_0oAII/AAAAAAABdD8/jrCZTd_xK-Y6CP1KwOtT_LpEpjp-1nvxgCNcBGAsYHQ/s200/onepiece03_nami.png",
"そげキング(ウソップ)" : "https://1.bp.blogspot.com/-mZpzgXC1Sxk/YAOTCAKwWTI/AAAAAAABdOM/5B4hXli0KLU5N-BySHgjVbhZscKLSE-bQCNcBGAsYHQ/s200/onepiece04_usopp_sogeking.png",
}
def path_to_image_html(path):
return f'<img src="{path}"/>'
df = pd.DataFrame({"Name": onepiece.keys(),
"Image": onepiece.values()})
display(df)
pd.set_option('display.max_colwidth', None) # カラムの幅を広げる
#出力された HTML を IPython.display のHTMLモジュールで HTML を Jupyter 上で表示
HTML(df.to_html(escape=False , #escape=False にすることでエスケープせずに HTML を出力
formatters=dict(Image=path_to_image_html))) #formattersでは、特定のカラムに関数を適用して変換
[OUT]

3.基本操作3:データ抽出/ソート
下記以降でメソッドを紹介します。基本的にdf.method()で処理したデータは上書きされないため処理した値を使用する場合は var=df.method()で変数に上書きするか、引数がある場合は(inplace=True)を使用します。
3-1.データ抽出1:スライス
Series/DataFrameはスライスで抽出します。方法は大きく分けて3つです。
【Series/DataFrame型の抽出方法】
●直接指定:df[column]で列取得。Series[Index]だと行方向の指定データ取得
●df.loc:Indexやcolumnの名称を使用して指定->わかりやすいけど面倒
●df.iloc:Indexやcolumnの位置を数字で指定->楽だけど見にくい
【Index指定なし】
[In]
import pandas as pd
filepath = 'Prices_2021_08_20211003_bitFlyer.csv'
df = pd.read_csv(filepath)
#列方向をスライス
df['BTC'] #BTCの列だけをSeries型で取得
df[['BTC']] #BTCの列だけをDataFrame型で取得
#行方向をスライス
df[2:3] #2行目のみ取得:df[2]はエラー
df[4:6] #行方向にスライス
#df.loc
df.loc[2] #Index情報から行方向に取得
df.loc[4:5] #Index情報から行方向に取得
df.loc[:, 'BTC'] #BTCの列だけをSeries型で取得
df.loc[4, ['BTC', 'ETH']] #指定Indexから指定カラムの情報をSeriesで取得
#df.iloc
df.iloc[[2]] #df.iloc[[2], :]でもOK
df.iloc[4:6, [0]] #0-1行目かつ0列データ(BTC)をDataFrameで取得
df.iloc[:, [1]] #1列目のデータ
df.iloc[:, [1,2]]
df.iloc[6:8, 1:3]
print(df.index.values)
[Out]
[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29 30]
※df.iloc[6:8, 1:3]のみ表示
BTC ETH
6 4801858 340618
7 4842996 334013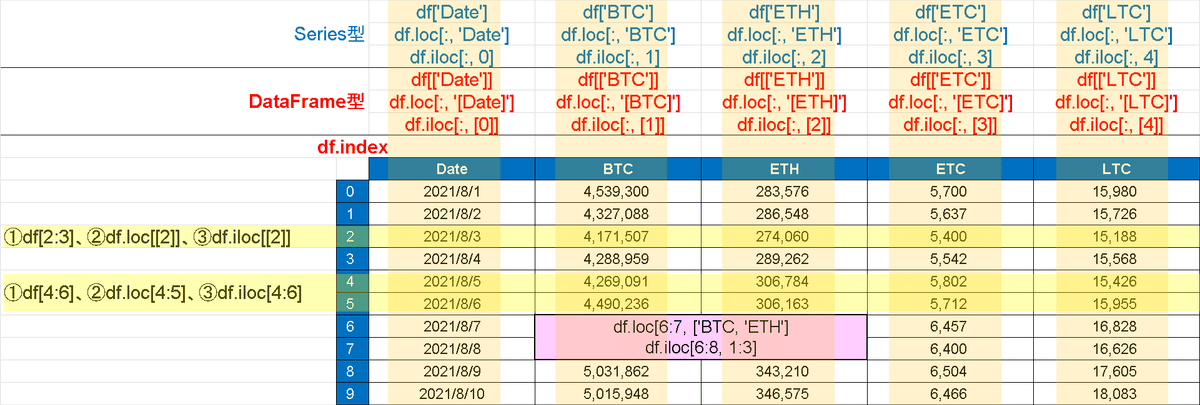
【Index指定あり】
基本的には同じですがlocはIndex名の記載が必要となります。
[In]
import pandas as pd
filepath = 'Prices_2021_08_20211003_bitFlyer.csv'
df2 = pd.read_csv(filepath, index_col='Date', parse_dates=True)
#列方向をスライス
df2['BTC'] #BTCの列だけをSeries型で取得
df2[['BTC']] #BTCの列だけをDataFrame型で取得
#行方向をスライス
df2[2:3] #2行目のみ取得:df2[2]はエラー
df2[4:6] #行方向にスライス
#df2.loc
df2.loc['2021-08-03'] #Index情報から行方向に取得
df2.loc['2021-08-05': '2021-08-06'] #Index情報から行方向に取得
df2.loc[:, 'BTC'] #BTCの列だけをSeries型で取得
df2.loc['2021-08-05', ['BTC', 'ETH']] #指定Indexから指定カラムの情報をSeriesで取得
df2.loc['2021-08-07':'2021-08-08', ['BTC', 'ETH']]
#df2.iloc
df2.iloc[[2]] #df2.iloc[[2], :]でもOK
df2.iloc[4:6, [0]] #0-1行目かつ0列データ(BTC)をDataFrameで取得
df2.iloc[:, [1]] #1列目のデータ
df2.iloc[:, [1,2]]
df2.iloc[6:8, 1:3]
print(df2.index)
[Out] dfの表示は無し
DatetimeIndex(['2021-08-01', '2021-08-02', '2021-08-03', '2021-08-04','2021-08-05', '2021-08-06', '2021-08-07', '2021-08-08','2021-08-09', '2021-08-10', '2021-08-11', '2021-08-12','2021-08-13', '2021-08-14', '2021-08-15', '2021-08-16',
'2021-08-17', '2021-08-18', '2021-08-19', '2021-08-20','2021-08-21', '2021-08-22', '2021-08-23', '2021-08-24','2021-08-25', '2021-08-26', '2021-08-27', '2021-08-28','2021-08-29', '2021-08-30', '2021-08-31'],
dtype='datetime64[ns]', name='Date', freq=None)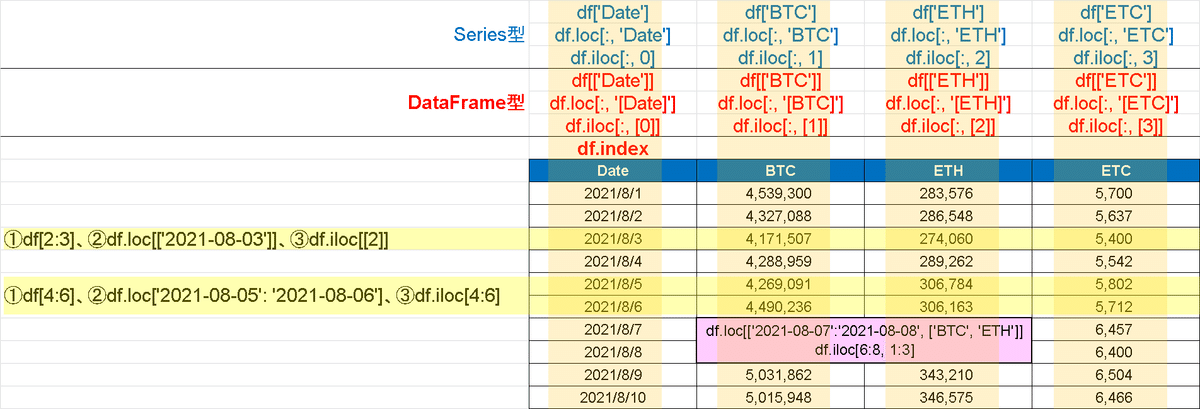
3-2.ソート(Index順):df.sort_index()
Indexの値でソートする場合はdf.sort_index()を使用します。
[In]
df.sort_index() #Indexの昇順ソート
df.sort_index(ascending=False) #降順ソート
[Out]
下図はdf.sort_index(ascending=False)
3-3.ソート(カラム):df.sort_values(by=column)
データの並び替えはdf.sort_values()で可能です。
[In]
df.sort_values(by='BTC') #昇順ソート
df.sort_values(by='BTC', ascending=False) #降順ソート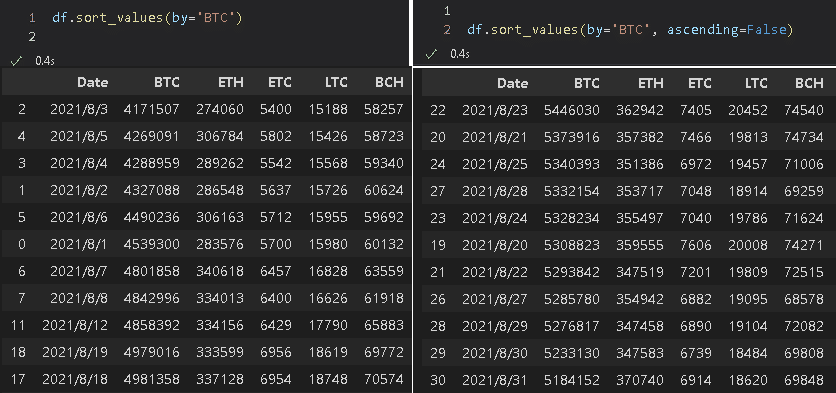
4.基本操作4:カラムの追加・削除
4-1.カラムの追加:df['newcolumn']=data
df[追加カラム名]=配列データを渡すことでカラムデータを追加できます。なお渡すデータ数はdfに合わせる必要があります。
[In]
df = pd.DataFrame({
'C1': ['A', 'A', 'B'],
'C2': ['cup', 'cup', 'cup'],
'C3': [4, 4, 3.5]
})
display(df)
df['C4'] = [1,2,3] #C4カラムを追加
df['C5'] = df['C3'] * 2 #C5カラムを追加
display(df)
[Out]
C1 C2 C3
0 A cup 4
1 A cup 4
2 B cup 4
C1 C2 C3 C4 C5
0 A cup 4 1 8
1 A cup 4 2 8
2 B cup 4 3 74-2.カラムの削除:drop()
DataFrameから不要な列を削除します。
[In]
df = df.drop(columns=['C3', 'C4', 'C5']) #C4,C5カラムを削除
df
[Out]
C1 C2
0 A cup
1 A cup
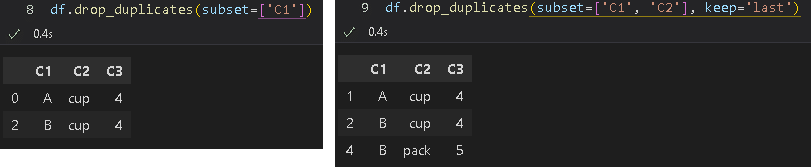
2 B cup4-3.重複データの削除:df.drop_duplicates()
重複したデータを除く処理はdf.drop_duplicates()です。動作の理解が難しいため実際の条件抽出は別のメソッドを使用した方がよいと思います。
[In]
df = pd.DataFrame({
'C1': ['A', 'A', 'B', 'B', 'B'],
'C2': ['cup', 'cup', 'cup', 'pack', 'pack'],
'C3': [4, 4, 3.5, 15, 5]
})
df
df.drop_duplicates()
df.drop_duplicates(subset=['C1'])
df.drop_duplicates(subset=['C1', 'C2'], keep='last')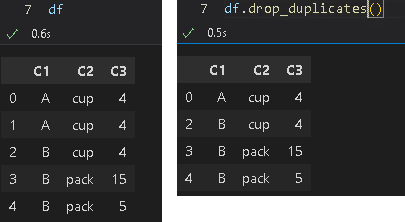
5.基本操作5:Indexの調整
5-1.Index番号の振り直し:reset_index()
index番号はdf.reset_index()とします。そのままだと元々あったindex情報がデータ内に含まれるためdrop=Trueとします。
(index情報をセットするのであれば不要です。Index番号でスライスする場合はresetしておかないと処理できない)
[In]
df = df.reset_index(drop=True) #元々あったindex番号をデータ内に含ませない5-2.Index情報を指定の値に変更:set_index()
df.set_index(column)で指定の値をindexに設定できます。(使ったことは無いですが)リストで渡すとマルチカラムに可能です。
[In]
df = df.set_index(['Date'])
df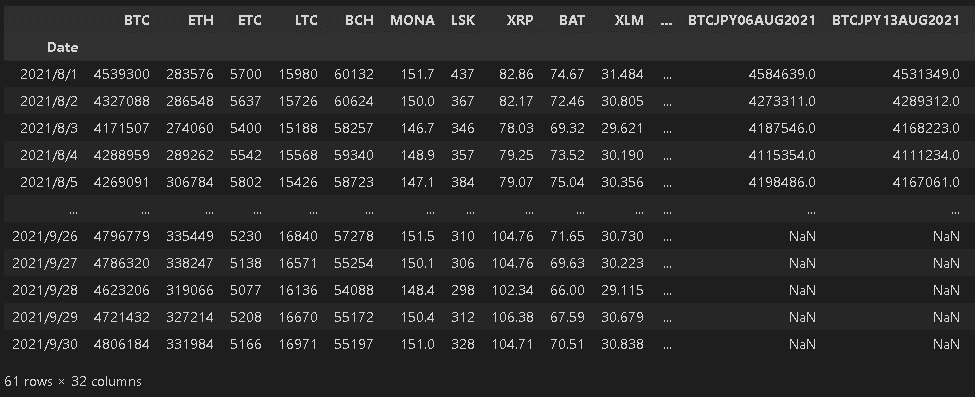
6.データ確認1:統計情報
6-1.各種統計情報(Series型)
統計情報および指定値のインデックス番号を取得します。
合計:sum, 平均:mean, 分散:var, 標準偏差:std, 最大:max, 最小:min
最大値index:argmax, 最小値index:argmin
[In]
df_BTC = df['BTC']
print('sum:', df_BTC.sum(), 'avg:', df_BTC.mean(),'var:', df_BTC.var(), 'std:', df_BTC.std() ) #合計・平均・分散・標準偏差
print('max:', df_BTC.max(), 'min:', df_BTC.min()) #最大値, 最小値
print('argmax:', df_BTC.argmax(),'argmin:', df_BTC.argmin()) #最大値のindex番号, 最小値のindex番号[Out]
sum: 154647700 avg: 4988635.483870967 var: 130442363299.45805 std: 361168.0540959541
max: 5446030 min: 4171507
argmax: 22 argmin: 26-2.統計情報の一括取得:df.describe()
DataFrame型において各カラムのデータ数、max/min、標準偏差、四分位数を一括で取得できるメソッドとしてdf.describe()があります。
[In]
df.describe() #各種統計量を確認
[Out]
下図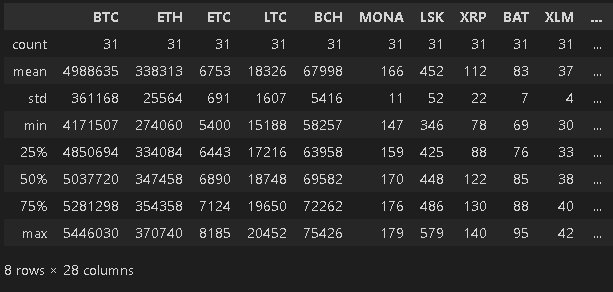
6-3.データ間の相関係数:df.corr()
各カラム間の相関係数はdf.corr()を使用します。相関係数×ヒートマップでどのパラメータ同士が強く結びついているかの可視化も可能です。
[In]
df.corr() #相関係数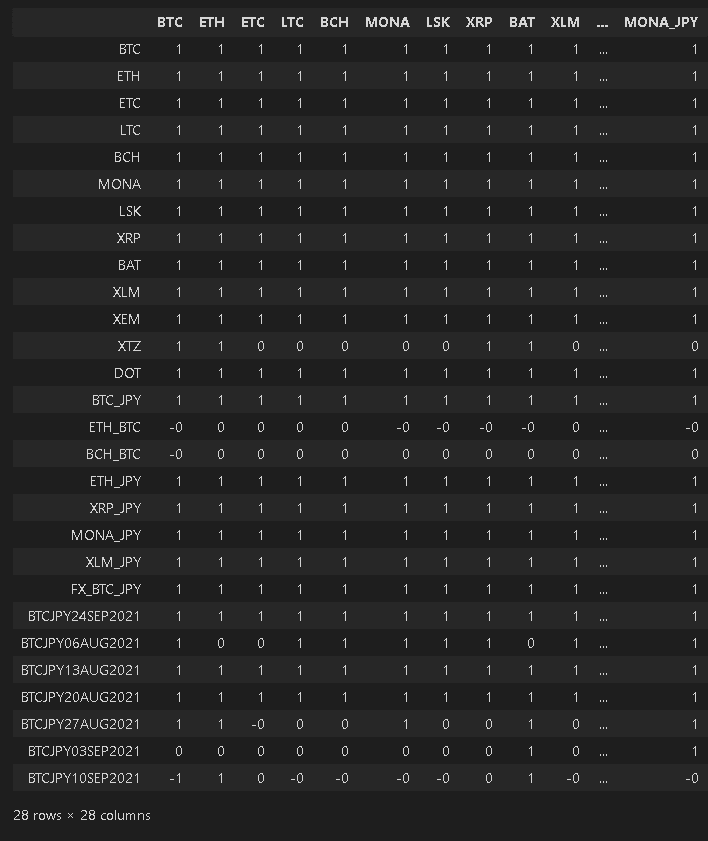
7.データ確認2:欠損値・重複データ
7-1.欠損値の合計数:df.isnull().sum()
データの欠損値の数を確認するにはdf.isnull().sum()とします。
[In]
df.isnull().sum() #欠損値の数を確認
[Out:下表]
Date 0
BTC 0
ETH 0
ETC 0
LTC 0
以下省略7-2.ユニークデータの確認1:df.nunique()
各データの中に重複しないデータが何個あるかを示すのがdf.nunique()となります。全データがユニークな場合は「出力=データ数となります」
[In]
df.nunique() #ユニーク(他の値と同じでない)な値の総数を確認
[Out]
Date 31
BTC 31
ETH 31
ETC 31
LTC 31
BCH 31
MONA 31
LSK 297-3.ユニークデータの確認2:Series.value_counts()
Series型で各データが何個ずつあるかを示すのがvalue_couns()となります。
[In]
print(df['BTC'].value_counts()) #データの中にユニークな値が何個ずつあるか確認
print('Max:', df['BTC'].max(),'Min:', df['BTC'].min(), 'Mean:', df['BTC'].mean(), 'std:', df['BTC'].std())
[Out]
4699264 1
5220280 1
5237068 1
5099070 1
4288959 1
..
5676975 1
4327088 1
5038116 1
5232672 1
5228482 1
Name: BTC, Length: 61, dtype: int64
Max: 5676975 Min: 4171507 Mean: 5022712.4754098365 std: 335300.889079873458.欠損値処理
上記dfはデータがきれいなため説明用dfを作成しました(1日データ想定)。作成したdfで下記のような不要データを処理していきます。
●欠損値:データが何も入っていない。処理はそのまま削除したり、平均値や中央値の値を埋めたりします。
●目的外データ:例えばプラントの運転中の統計データが欲しい時、停炉中のデータ(値0)は不要なため省きます。
【サンプルデータ】
[In]
import numpy as np
import datetime
#numpyで適当なデータ作成
np.random.seed(0) #乱数値を固定
data1 = np.ones(24)*10 + np.random.randn(24)
data2 = np.ones(24)*50 + np.random.randn(24)
data3 = np.ones(24)*100 + np.random.randn(24)
#データに0と欠損値を作成する。
def addnanzero(data):
for i in np.random.choice(24, 4): #0~24までの整数値をランダムで4つ取得する
data[i] = np.nan #Noneデータを入れる
for i in np.random.choice(24, 4): #0~24までの整数値をランダムで4つ取得する
data[i] = 0 #0を入れる
return data
data1, data2, data3 = addnanzero(data1), addnanzero(data2), addnanzero(data3)
_df_s = pd.DataFrame([data1, data2, data3]) #DataFrame作成
df_s = _df_s.T #行列を入れ替える(転置)
#カラム名称を追加
df_s.columns = ['データA', 'データB', 'データC']
df_s
[Out]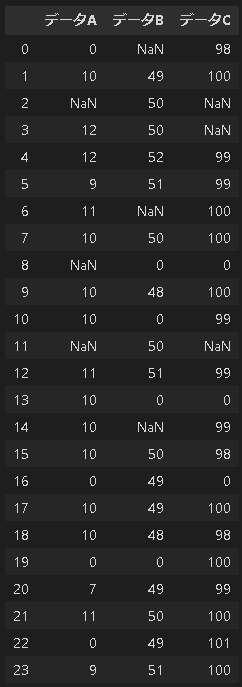
8-1.欠損値の除去:df.dropna()
欠損値NaNが入っているデータを削除します。
[In]
df_s.dropna() #行方向に確認して欠損値のある行を削除
df_s.dropna(axis=1) #列方向に確認して欠損値のある列を削除
df_s.dropna(subset=['データB']) #指定したカラムの欠損値を削除
df_s[df_s['データB'].isnull() == False] #指定したカラムの欠損値をTrue/Falseで取得後にFalse(欠損値なし)を取得
df_s.dropna(thresh=2) #行方向の欠損値の数がthresh(閾値)以上のデータを削除
8-2.欠損値の補填:df.fillna(), df.interpolate()
欠損値だらけだと上記でデータがなくなるため下記処理で補填します。
[In]
df_s.fillna(df_s.mean()) #各値の平均値で補填
df_s.fillna(df_s.median()) #各値の中央値で補填
df_s.fillna(df_s.mode()) #各値の最頻値で補填※カテゴリカルデータ向け,下記未記載
df_s.fillna(777) #欠損値に指定値を入れる
df_s.fillna(method='ffill') #欠損値のひとつ前の値で埋める※下記未記載
df_s.fillna(method='bfill') #欠損値の次の値で埋める※下記未記載
df_s.interpolate(axis=0, limit_direction="both") #欠損値(NaN)を列方向の前後のデータの欠損値で埋める
[Out]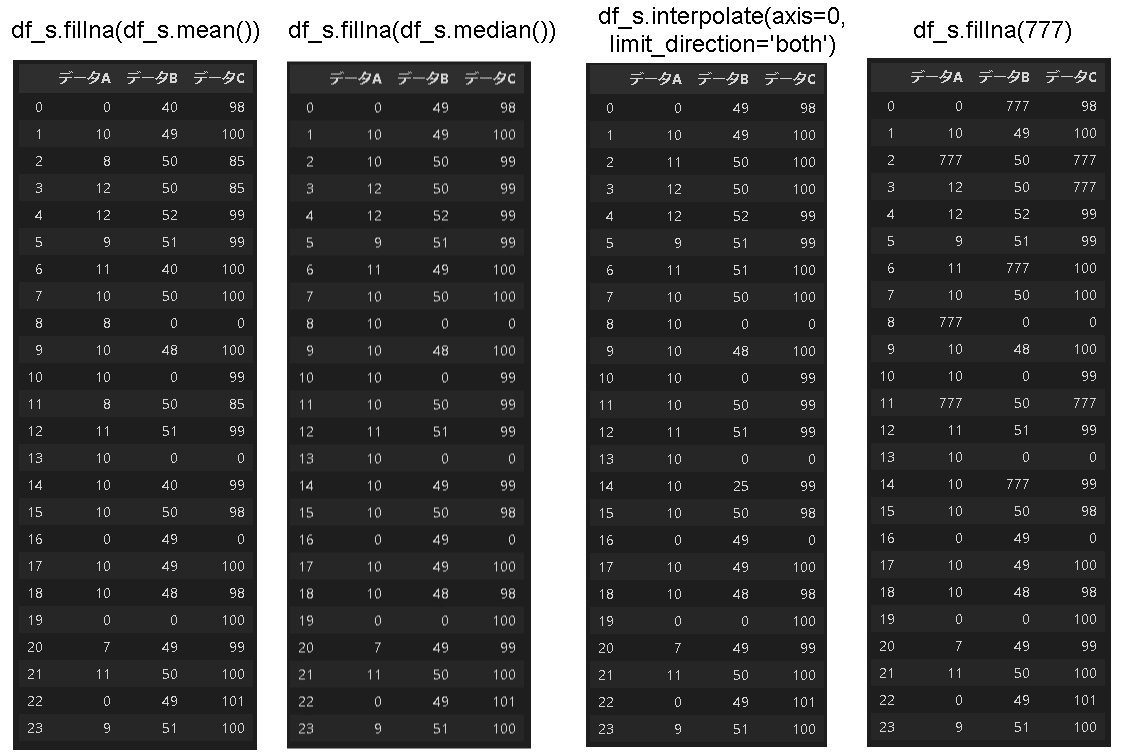
9.データの条件抽出
特定条件のデータが欲しい時は条件を指定して抽出します。
9-1.シンプルな抽出
df[条件式]により指定した値の行だけ取得したり、その他の値をNaNにしてデータを抽出することが可能である。
【参考】
●dfに比較演算子を渡すとBool型が取得できます(maskデータ取得)。それを再度dfに渡すとTrueの箇所だけ値が抽出されます。
●複数条件は条件式を()で括り論理和(or)は|、論理積(and)は&を使用します。
[In]
pd.set_option('max_rows', 100)
df[df>5000000] #条件に合うデータ以外はすべてNaNで返す
df['BTC']>5000000 #指定条件に対してSeries型でBool値を返す
df[df['BTC']>5000000] #Bool値のTrueのみ表示(Falseの値は除去)
df[(df['BTC'] >5000000) & (df['ETC'] > 7000)] #and条件
【Out】次節参照9-2.queryメソッド
条件が複雑になる(例:カラム同士の比較)ならquery()が使用可能
[In]
df.query('BTC > 5000000') #column 条件
df.query('BTC > 5000000 and ETC > 7000') #and条件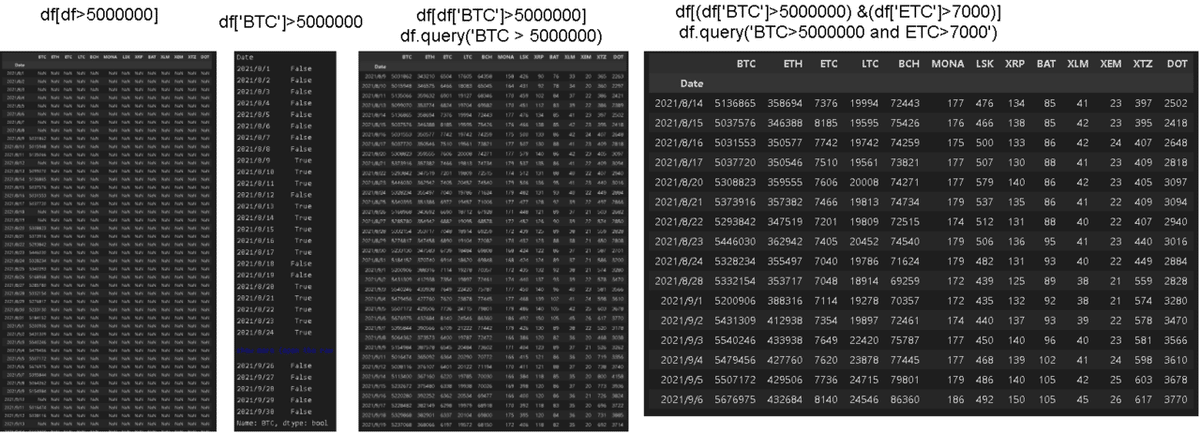
9-3.df.where/df.mask メソッド
df.whereは条件値に対してbool値ではなく、データ値とNaNで返してくれます。Trueになる値を数値で返すのがwhere, 逆の動作(TrueにNanを与える)のがmaskです。
[In]
df.where(df['BTC']>5000000).head(10) #BTCカラムの値が5M以下の行はNaNで出力
df.where(df['BTC']>5000000, 'Low').head(10) #BTCカラムの値が5M以下の行にLowを代入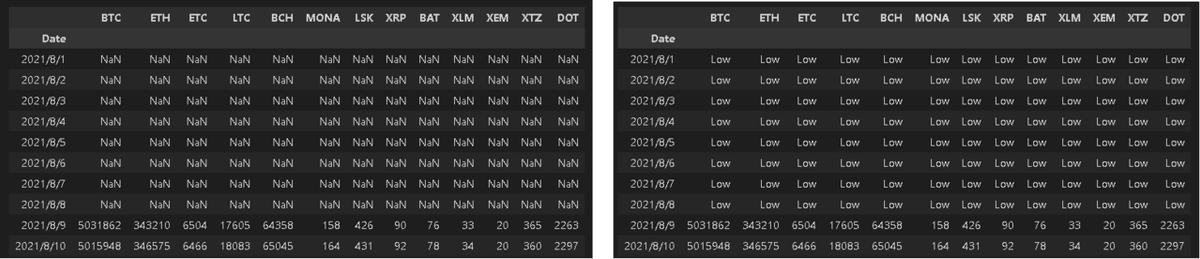
9-4.Bool型同士の和集合・積集合
条件抽出したBoolデータを持つDataFrame(Series)型の和集合・積集合は足し算、掛け算で抽出できる。
[IN]
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return "\n".join(template.format(arg._repr_html_())
for arg in self.args)
a = pd.DataFrame([True, True, False, False], columns=['A'])
b = pd.DataFrame([True, False, True, False], columns=['B'])
c = a['A']+b['B'] #aとbの和集合
c = pd.DataFrame(c) #SeriesをDataFrameに変換
c.columns = ['A+B(和集合〈or〉)']
d= a['A']*b['B'] #aとbの積集合
d = pd.DataFrame(d) #SeriesをDataFrameに変換
d.columns = ['A*B(積集合〈and〉)']
display(HorizontalDisplay(a, b, c, d)) #複数表示
[OUT]
10.データ結合:pd.concat()/ pd.merge()
データが正しいとして、時系列データ同士をpd.concat([df1,df2])で結合します。今回はbtcデータの8月・9月を結合しました。
pd.merge()でも結合できますが苦手なので用語だけで・・・
[In]
df_Aug = pd.read_csv('Prices_2021_08_20211003_bitFlyer.csv', date_parser=[0]) #2021年8月データ
df_Sep = pd.read_csv('Prices_2021_09_20211003_bitFlyer.csv', date_parser=[0]) #2021年8月データ
df = pd.concat([df_Aug, df_Sep], axis=0) #axis=0は行方向に追加(np.vstack)、axis=1は列方向に追加(np.hstack)、
display(df.head(), df.tail()) #引数無しだと5つ表示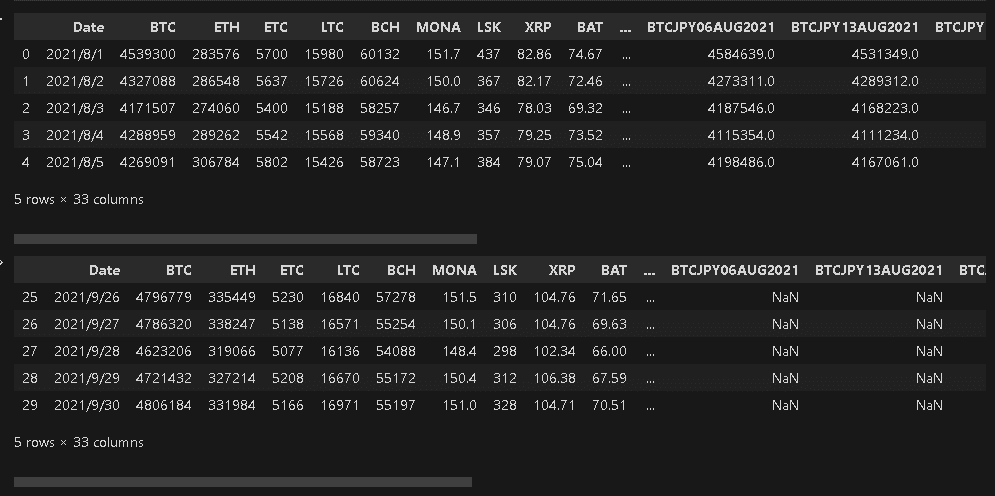
DataFrameのカラムとインデックス情報は下記で取得できます。下記のとおり同じカラムに対して行方向にデータを結合しており、元データのIndex情報もそのまま保持しております(Indexが連番ではない)。
[In]
print(df.index)
print(df.columns)
[Out]
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16,
17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 0, 1, 2,
3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19,
20, 21, 22, 23, 24, 25, 26, 27, 28, 29],
dtype='int64')
Index(['Date', 'BTC', 'ETH', 'ETC', 'LTC', 'BCH', 'MONA', 'LSK', 'XRP', 'BAT',
'XLM', 'XEM', 'XTZ', 'DOT', 'BTC_JPY', 'ETH_BTC', 'BCH_BTC', 'ETH_JPY',
'XRP_JPY', 'MONA_JPY', 'XLM_JPY', 'FX_BTC_JPY', 'BTCJPY24SEP2021',
'BTCJPY06AUG2021', 'BTCJPY13AUG2021', 'BTCJPY20AUG2021',
'BTCJPY27AUG2021', 'BTCJPY03SEP2021', 'BTCJPY10SEP2021',
'BTCJPY17SEP2021', 'BTCJPY31DEC2021', 'BTCJPY01OCT2021',
'BTCJPY08OCT2021'],
dtype='object')11.関数の適用
データに複雑な計算をしたい場合は関数で処理できます。
11-1.関数処理:apply()
やや複雑な処理をしたい場合は処理する関数をapplyに入れます。簡易の処理ならlambda関数を使用します(例:str->intに変換など)。
(下記例はBTC価格が5M以上の場合はHith, 未満はLowのデータを作る。)
[In]
# df['BTC'].apply(lambda x: x*exchange_rate) #df['BTC'] * exchange_rateのapply版
def highlowcheker(x):
if x >=5000000:
x = 'High'
else:
x = 'Low'
return x
df['BTC_HighLow'] = df['BTC'].apply(highlowcheker) #applyに処理する関数を記載:関数の()は不要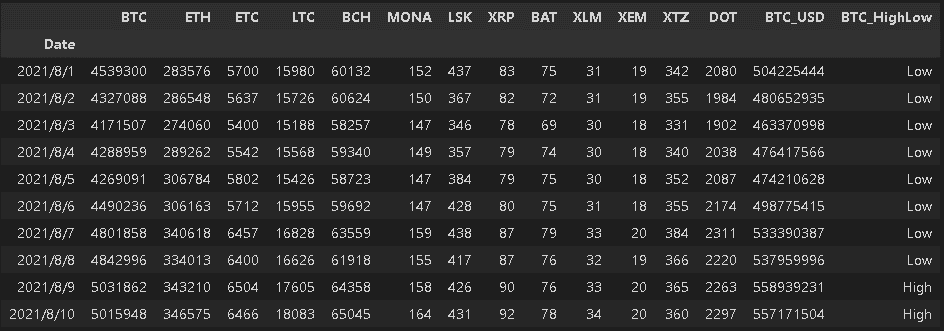
11-2.関数処理:map()_辞書を使用した変換
High/Lowのようなカテゴリカルデータは機械学習では処理できません(数値しか受け付けない)。これらを数値への変換にmapを使用します。
[In]
dict_highlow = {'High':1, 'Low':0} #カテゴリカルデータ変換用の辞書
df['BTC_HLnum'] = df['BTC_HighLow'].map(dict_highlow) #辞書内のKeyをvalueで置き換え
df.head(2)
12.Option設定(桁数や行列表示数)
12-1.Optionでの調整
Option設定で体裁を見やすくできます。
【Option調整前】floatは全桁数表示となり、行列も途中で見切れます。
[In]
datalist = [i+0.0001 for i in range(49)]
df_float = pd.DataFrame([datalist]) #リストを[]で囲うと配列5行1列->1行5列に変わる(見やすいようにしているだけ)
df_float 0 1 2 3 4 5 6 7 8 9 ... 39 40 41 42 43 44 45 46 47 48
0 0.0001 1.0001 2.0001 3.0001 4.0001 5.0001 6.0001 7.0001 8.0001 9.0001 ... 39.0001 40.0001 41.0001 42.0001 43.0001 44.0001 45.0001 46.0001 47.0001 48.0001【Option調整後】「Options and settings」できれいに表示できます。
[In]
# pandasで小数点以下2以下を表示させないように設定
pd.set_option('display.precision',2)
# データフレームですべての項目を表示
pd.set_option("max_rows",100)
pd.set_option("max_columns",100)
datalist = [i+0.0001 for i in range(49)]
df_float = pd.DataFrame([datalist]) #リストを[]で囲うと配列5行1列->1行5列に変わる(見やすいようにしているだけ)
df_float
12-2.Option設定のreset/小数点表記の設定
設定のresetおよび整数または指数を表示する方法は下記のとおり
#表示のreset(; は行数を減らすためにつけているだけ)
pd.reset_option('display.precision'); pd.reset_option("max_rows"); pd.reset_option("max_columns")
#指数表記を小数表記にする。
pd.options.display.float_format = '{:2e}'.format
#小数表記を指数表記にする。
pd.options.display.float_format = '{:.2f}'.format12-3.背景設定:df.style.background_gradient()
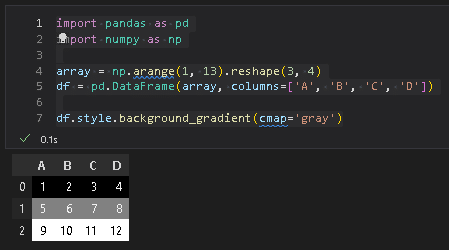
DataFrameの値に背景をつける場合は”df.style.background_gradient()”を使用します。色はcmapで調整し、'gray'や'Blues'などを指定可能です。
13.可視化
可視化ライブラリとしてmatplotlibがありますが覚えるのがかなり難しいです。簡単なプロットはDataFrameから直接プロット可能です。
サンプルは価格データであり、indexがただの連番と、日付(Date)に設定した2種類を作成しました。これは出力するプロットのx軸がindexに影響することを確認するためです。
[IN]
import pandas as pd
import numpy as np
filepath = 'Prices_2021_08_20211003_bitFlyer.csv'
df = pd.read_csv(filepath)
df_dateidx = df.set_index('Date') # dateをindexに設定
print(df.columns)
display(df.head())
display(df_dateidx.head())[OUT]
Index(['Date', 'BTC', 'ETH', 'ETC', 'LTC', 'BCH', 'MONA', 'LSK', 'XRP', 'BAT',
'XLM', 'XEM', 'XTZ', 'DOT', 'BTC_JPY', 'ETH_BTC', 'BCH_BTC', 'ETH_JPY',
'XRP_JPY', 'MONA_JPY', 'XLM_JPY', 'FX_BTC_JPY', 'BTCJPY24SEP2021',
'BTCJPY06AUG2021', 'BTCJPY13AUG2021', 'BTCJPY20AUG2021',
'BTCJPY27AUG2021', 'BTCJPY03SEP2021', 'BTCJPY10SEP2021'],
dtype='object')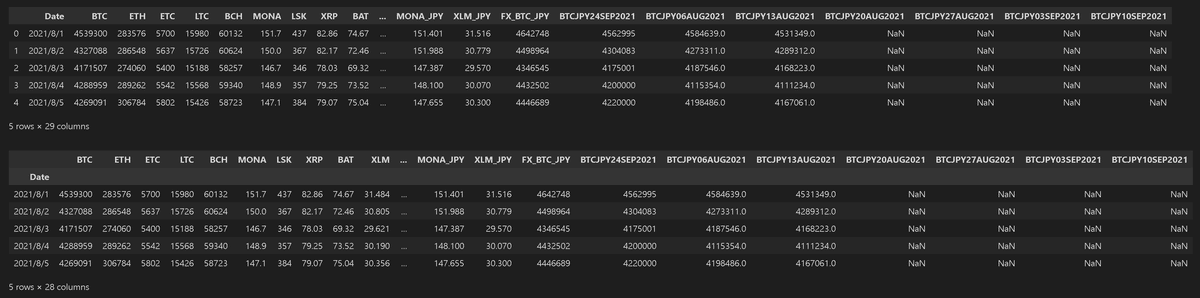
13-1.プロット図:df.plot()
プロット図はdf.plot()(またはSeries.plot())で出力でき、複数のメソッドを持つためdf.plot.<API>で下記のように多様な図を作成できます。
‘line’ : line plot (default)
‘bar’ : vertical bar plot
‘barh’ : horizontal bar plot
‘hist’ : histogram
‘box’ : boxplot
‘kde’ : Kernel Density Estimation plot
‘density’ : same as ‘kde’
‘area’ : area plot
‘pie’ : pie plot
‘scatter’ : scatter plot (DataFrame only)
‘hexbin’ : hexbin plot (DataFrame only)
13-1-1.折れ線グラフ:df.plot()
折れ線グラフはdf.plot()で出力できます(正確にはdf.plot.line()だが簡略化)。参考例として(DataFrame/Series)×(indexが連番/Datetime)=4種を出力しました。見た目は綺麗ではありませんが簡単なEDAには十分使えると思います。
[IN]
df.plot()
df['BTC'].plot()
df_dateidx.plot()
df_dateidx['BTC'].plot()
13-1-2.棒グラフ:df.plot.bar()
棒グラフは"df.plot.bar()"を使用します。APIが分かりにくいのでとりあえず①全部まとめて出力、②欲しい列を選択して出力 の2種を出力しました。
[IN]
df.plot.bar(x='Date', rot=90, figsize=(20, 10)) # x軸:日付, y軸:全て
df.plot.bar(x='Date', y='BTC', rot=90, figsize=(20, 10)) #x軸:日付, y軸:BTCのみ
[OUT]
13-2.確率分布
13-2-1.ヒストグラム(全データ):df.hist()
全データのヒストグラムを作成するにはdf.hist()を使用します。
[IN]
df.hist(figsize=(20, 10))
[OUT]
13-2-2.ヒストグラム(個別):df.plot.hist()
個別データのヒストグラムを作成するにはdf.plot.hist()を使用します。(2種重ねて出力も可能)
[IN]
df.plot.hist(x='Date', y='BTC', bins=10, figsize=(8, 6)) #x軸:日付, y軸:BTCのみ
df.plot.hist(x='Date', y=['BTC', 'ETH'], bins=10, figsize=(8, 6)) #x軸:日付, y軸:BTC+ETHのみ
[OUT]
13-2-3.確率密度分布(KDE):df.plot.kde()
確率変数の確率密度関数を推定するノンパラメトリック手法であるカーネル密度推定(kernel density estimation)により確率密度分布を出力します。
[IN]
#kde:kernel density estimation(カーネル密度推定)
df.plot.kde(x='Date', y='BTC', figsize=(8, 6)) #x軸:日付, y軸:BTCのみ
df.plot.kde(x='Date', y=['BTC', 'ETH'], figsize=(8, 6)) #x軸:日付, y軸:BTC+ETHのみ
[OUT]
14.集計処理
14-1.グループ別集計:groupby()
DataFrame(テーブルデータ)に対して下記のような処理が可能です。
sum():特定列に所属する値の合計
mean():特定列に所属する値の平均
count():特定列に所属する値の数(カウント)
[API]
DataFrame.groupby(by=None, axis=0, level=None, as_index=True,
sort=True, group_keys=True, observed=False, dropna=True)groupbyで同じカテゴリーデータの統計値を取得できます。またカテゴリカルデータはvalue_counts()とlenを併用すると割合を計算できます。
[IN]
df = pd.DataFrame([['A', 1.0, 10],
['A', 2.0, 20],
['B', 3.0, 30]], columns=['col1', 'col2', 'col3'])
print(df.groupby('col1'))
display(HorizontalDisplay(df, df.groupby('col1').sum(), df.groupby('col1').mean(),
df.groupby('col1').agg(['sum', 'mean'])))
[OUT]
pandas.core.groupby.generic.DataFrameGroupBy object at 0x00000250321E7970>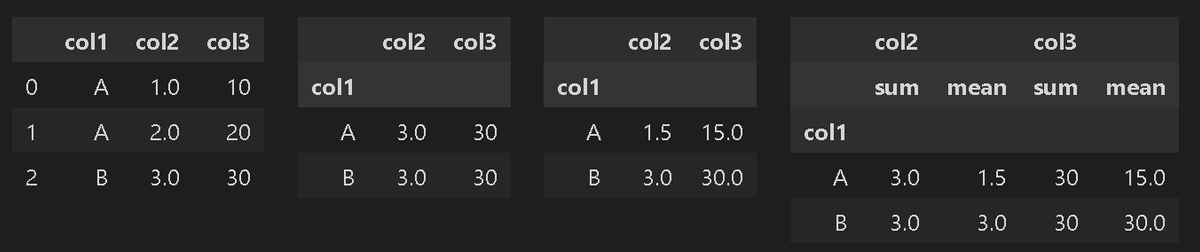
[IN]
display(HorizontalDisplay(df, df.groupby('col1').count(), df.groupby('col1').nunique()))
[OUT]
14-2.ピボットテーブル:pd.pivot_table
データベース(SQL)から取得したレコード(データ)においてデータ集計をするときにピボットテーブルが重要となります。Excelでも多く利用されているため参考記事も多数あると思います(下記は参考例)。
発注品毎の月別の合計額を計算
月のデータが全て同じ行にあるため、月ごとに列になるように集計しなおす
15.時系列データ処理
15-1.時系列データの間隔変化(min->hour):resample
データの時間幅を調整するためにresampleメソッドを使用します。1minデータを処理するために別のcsvデータを使用します。
[In]
df_btc_1min = pd.read_csv('btc_210927-210928.csv',date_parser=[0] ,header=None) #BTCデータ読み込み=>ヘッダーがないため指定
df_btc_1min.columns = ['日時','始値','高値','安値','終値','出来高']#サイト情報からカラムを指定
#理由はわからないけどdatetimeがparseされなかったため日時(文字列)をdatetimeに変換
print(f"df_btc_1min['日時']のデータ型(変換前):{df_btc_1min['日時'].dtype}") #日時カラムのデータ型確認
df_btc_1min['日時'] = df_btc_1min['日時'].astype(np.datetime64)
print(f"df_btc_1min['日時']のデータ型(変換後):{df_btc_1min['日時'].dtype}") #日時カラムのデータ型確認
df_btc_1min = df_btc_1min.set_index(['日時'], drop=True)#Indexをdatetime型に修正
df_btc_1min
[Out]
df_btc_1min['日時']のデータ型(変換前):object
df_btc_1min['日時']のデータ型(変換後):datetime64[ns]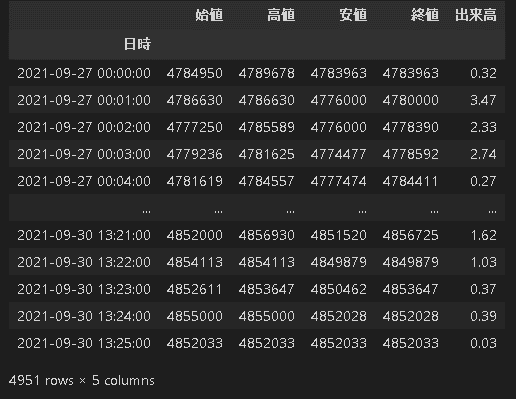
resample().mean()で移動平均値を取得できます。sum()は積算値です。
df_btc_1min.resample('30T').mean() #30分平均
df_btc_1min.resample('h').mean() #1h平均
df_btc_1min.resample('D').mean() #1日平均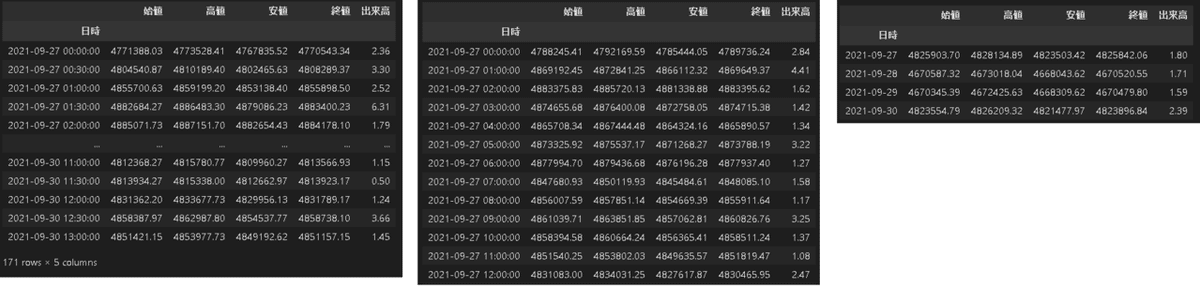
16.機械学習向けの処理
16-1.One-Hotエンコーディング():get_dummies
DataFrame内のカテゴリカルデータに対してダミー変数(One-Hotエンコーディング)を作成する処理としてdf.get_dummies()があります。
[API]
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False,
columns=None, sparse=False, drop_first=False, dtype=None)[IN]
df = pd.DataFrame(['BTC', 'BTC', 'BTC', 'ETH', 'ETH', 'Doge'], columns=['Coin'])
df_dummies = pd.get_dummies(df)
display(HorizontalDisplay(df, df_dummies))
[OUT]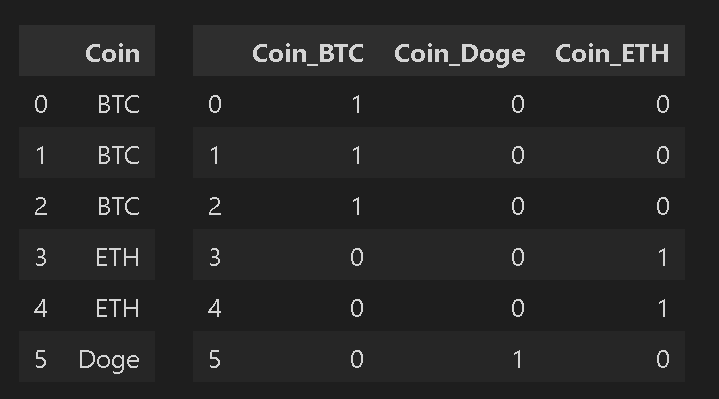
別添1 チートシート
Pandas公式のチートシートは英語のみため下記記事のものを拝借しました。
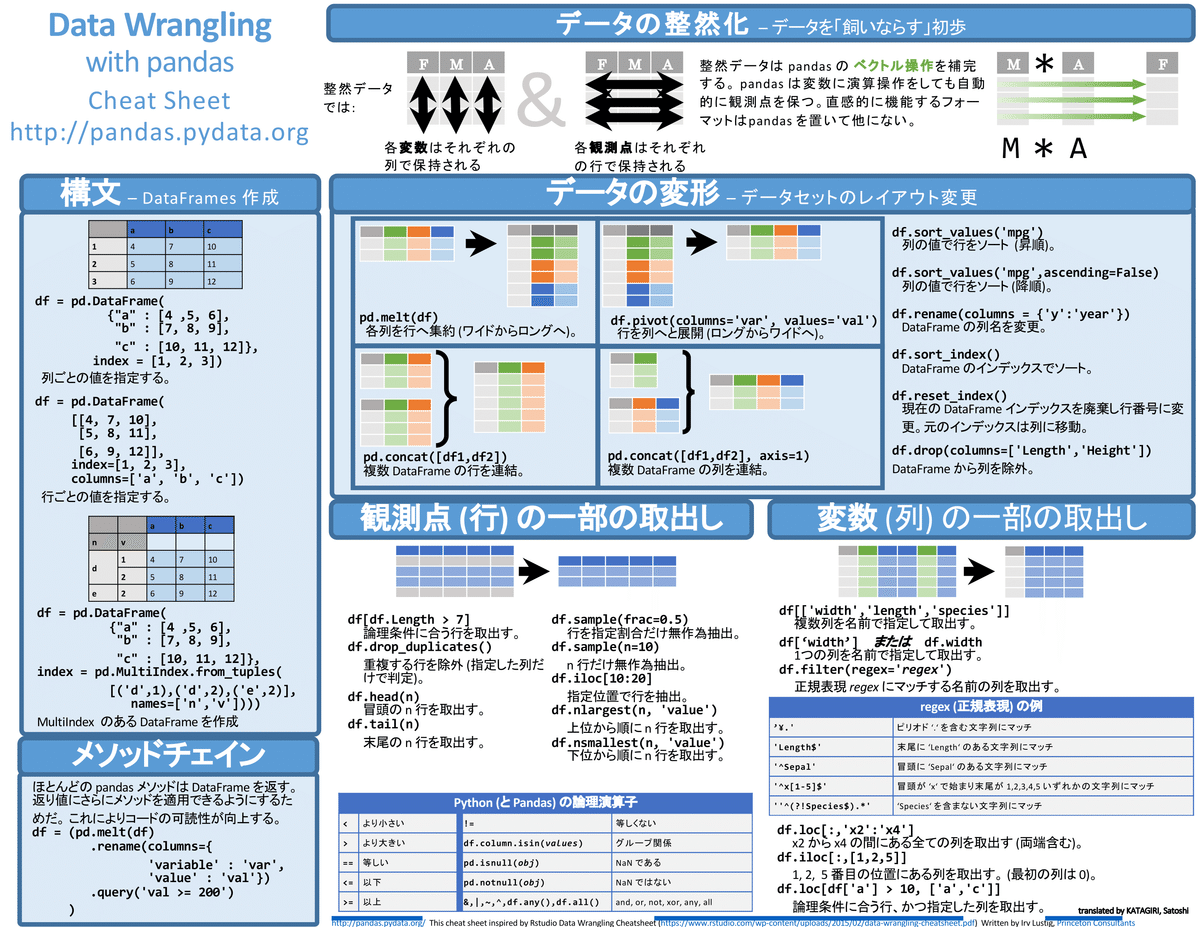
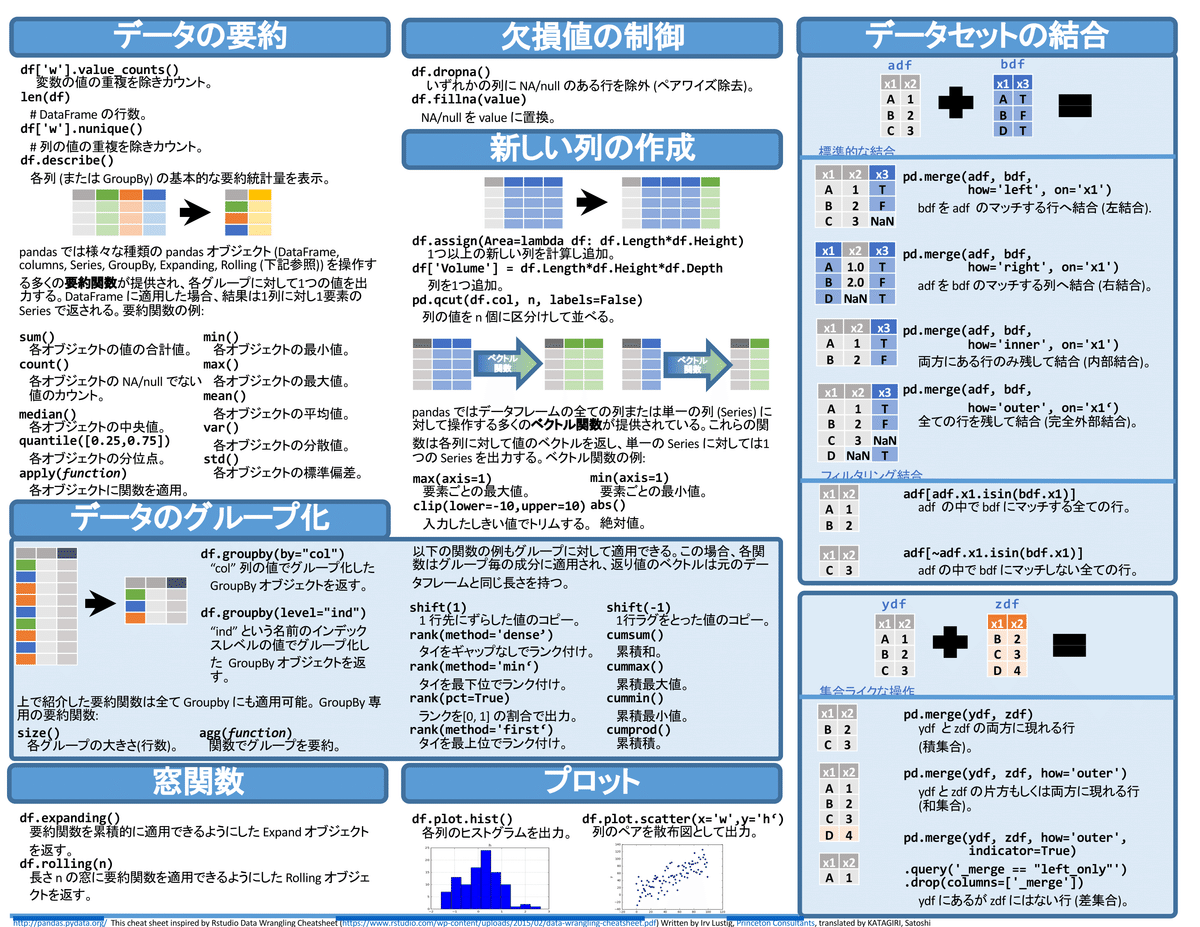
別添2 データ処理のフロー
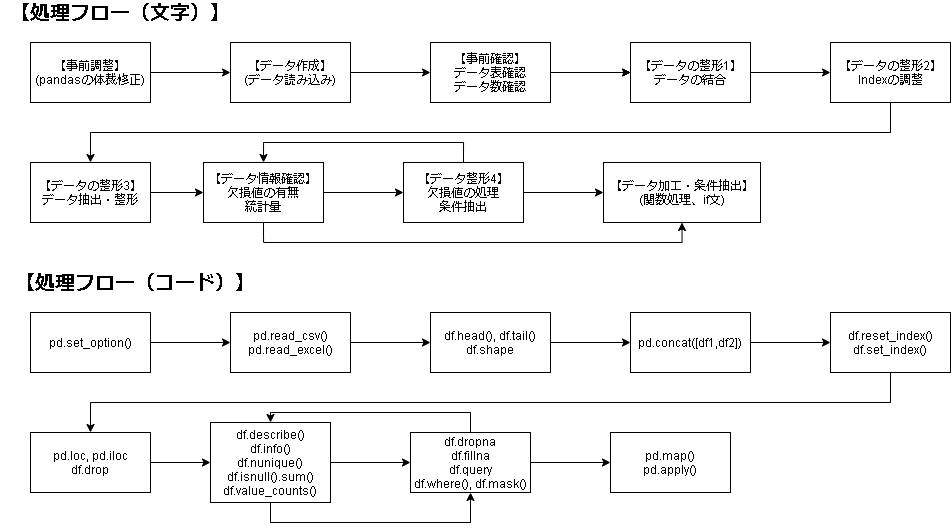
Pandasで時系列データ処理の流れを記載します(やや自己流)。
GoogleCloudのVertex AI概要に参考手順の記載がありますのでご参考までに。
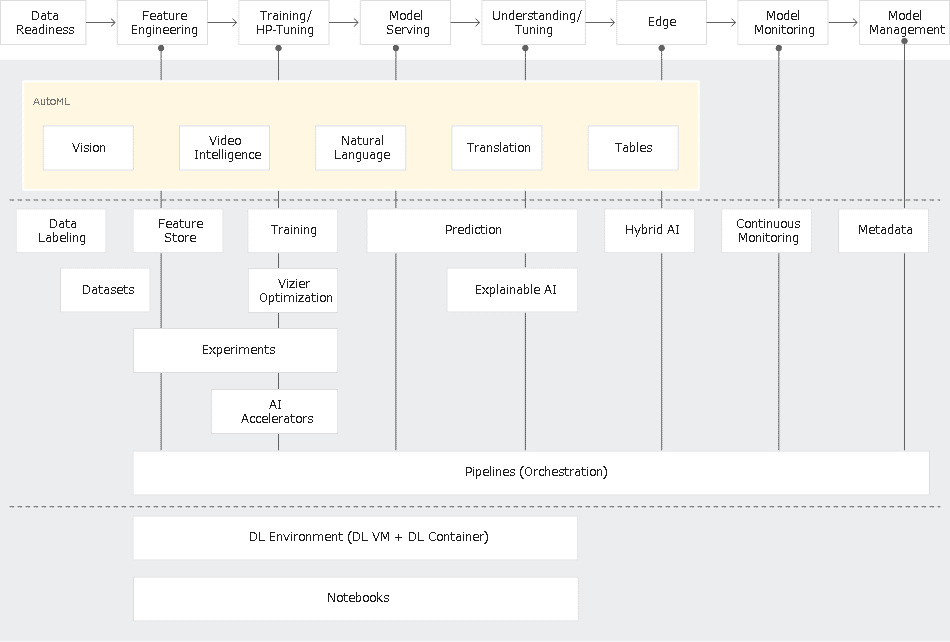
参考として一般的な処理フローは下図を「機械学習品質マネジメントガイドライン 第2版」から拝借しました。
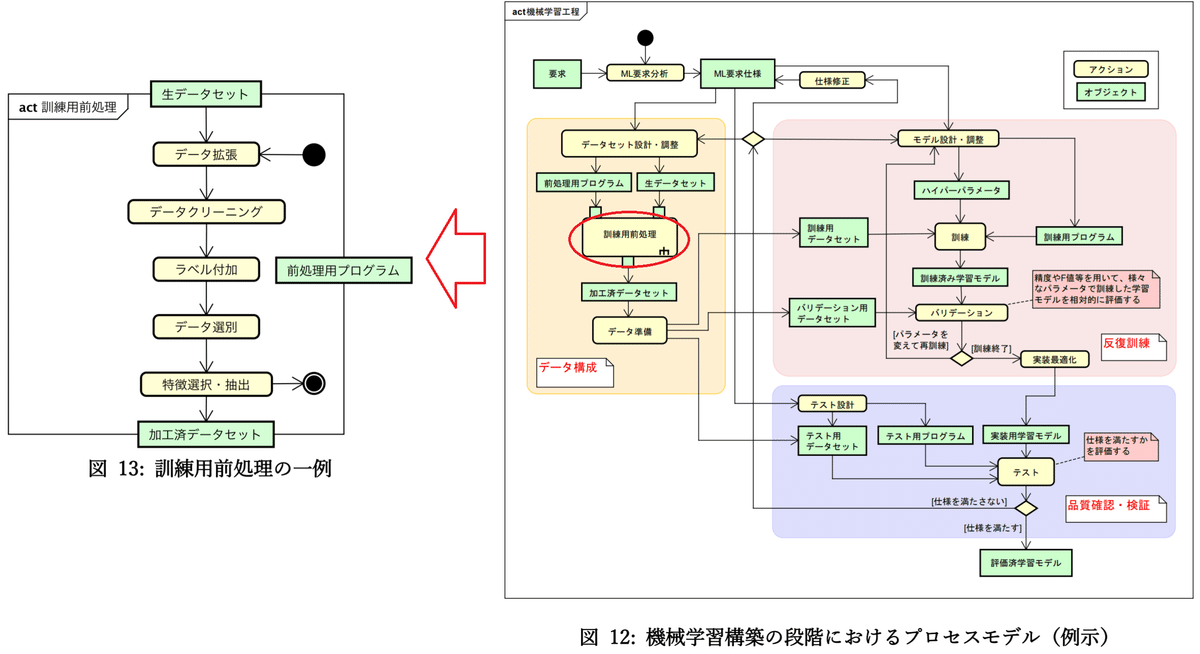
別添3 Pandas以外のデータ処理ライブラリ
Pandasはデータ処理ライブラリとして有名ですが処理が遅かったりもします。Pandas以外のライブラリとしては下記があります。
cuDF(NVIDIA):高速化用
Dask:大量のデータ処理向け
別添4 参考資料
かなり体系的にまとまっているためオススメ。
下記は良く参照して使う。
class HorizontalDisplay:
def __init__(self, *args):
self.args = args
def _repr_html_(self):
template = '<div style="float: left; padding: 10px;">{0}</div>'
return "\n".join(template.format(arg._repr_html_())
for arg in self.args)
# print
display(HorizontalDisplay(df, df))
# output
HorizontalDisplay(df, df)あとがき
コードは動作確認してるけど文章の表現に関しては十分に修正できていないけど、ほしい内容はすべて書いたので自分用に先行公開して、後で微修正していきたいと思います。
自分用とはいえ休日丸1日(~10h)はきつい・・・
更新履歴
2022年2月8日 体裁修正、メソッド追加
2023年4月23日:13章以降追加