
Python基礎19:イテレータ生成(itertools)

1.概要
itertoolsはPythonの標準ライブラリの一つであり効率的なループの実行を支援するための「イテレータ」を作成する機能を提供します。
イテレータとは要素を順番に取り出すことができるオブジェクトのことでありリストやタプルなどが該当します。これらのオブジェクトからデータを順番に取り出して処理を行うとき、itertoolsはその処理をより簡潔に効率的に書くことを可能にします。
2.itertoolsでできること
itertoolsにはさまざまな関数がありそれぞれが特定の種類のイテレータを生成します。以下に主なものをいくつか紹介します。
累積和:要素の累積和を計算する
値のカウント:値を順番に数える
組み合わせ:要素の全ての組み合わせや順列、直積
ループの出力管理:要素を特定の条件でフィルタリングしたり、繰り返したり、順番に取り出したりする
詳細は公式Docs参照のこと
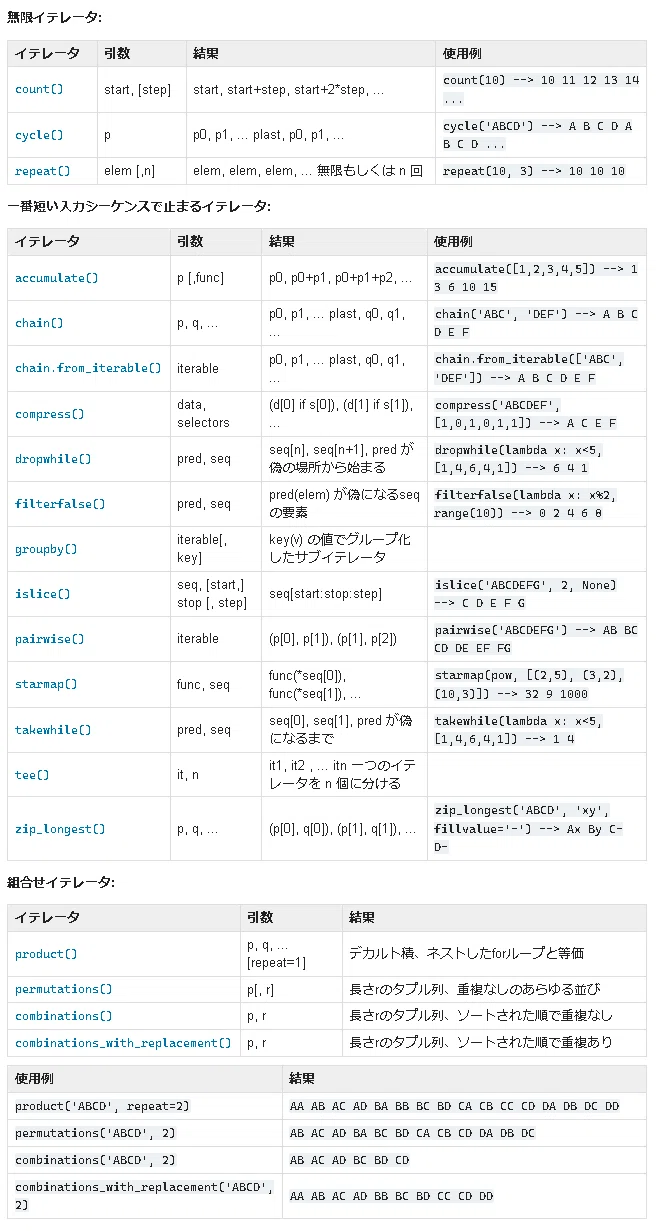
3.無限イテレータ
無限イテレータでは、無限データを生成するイテレータのことです。その特性を活かして特定の操作を永遠に続けるループを作ったり、ある条件が満たされるまで操作を続けるループを作ることができます。
無限イテレータはループを抜ける条件がないとプログラムが永久的に動作するため注意が必要です。
3-1.無限の等差数列を作成:count
countは無限に続く等差数列を生成するためのイテレータを作成します。初期値(start)と公差(step)を指定することができ、指定しない場合は初期値は0、公差は1になります。
[API]
itertools.count(start=0, step=1)下記では、10から始まり2ずつ増える数列を作ります。また無限ループにならないよう、20を超えたらループから抜けるようにしています。
[IN]
from itertools import count
for i in count(start=10, step=2):
if i > 20: # iが20を超えたらループを抜ける
break
print(i)[OUT]
10
12
14
16
18
203-2.イテラブルを無限に繰り返す:cycle
cycleは、引数として与えられたイテラブル(リストや文字列など)を無限に繰り返すイテレータを作成します。
[API]
itertools.cycle(iterable)下記コードは、リスト['A', 'B', 'C']の要素を無限に繰り返し出力し、counterが10以上になったらループから抜けるようにしています。
[IN]
from itertools import cycle
counter = 0
for item in cycle(['A', 'B', 'C']):
if counter >= 10: # counterが10以上になったらループを抜ける
break
print(item)
counter += 1[OUT]
A
B
C
A
B
C
A
B
C
A4.イテレータの形状変更
イテレータの形状を操作して、ほしい形で値を出力していきます。
4-1.イテラブルの連結:chain
chainは複数のイテラブル(リストや文字列など)を引数に取り、その要素を一つのイテレータとして連結します。
[API]
itertools.chain(*iterables)chainは複数のイテラブルを一つのイテレータとして扱いたい場合に便利です。以下に具体的な使用例を示します。
[IN]
from itertools import chain
ls1 = [1, 2, 3]
ls2 = ['A', 'B', 'C']
ls3 = [100, 200, 300]
for i in chain(ls1, ls2, ls3):
print(i)[OUT]
1
2
3
A
B
C
100
200
3004-2.chainの高度版:from_iterable
chain.from_iterableは、引数として一つのイテラブルを受け取りそのイテラブルの要素を連結した新たなイテレータを作成します。
引数のイテラブルの各要素もまたイテラブルである必要があります。
[API]
classmethod chain.from_iterable(iterable)具体例としてchain()だとイテレータ内を直接出力しますが、chain.from_iterable()ではすべてのイテレータを1つのイテレータとして出力します。
[IN]
from itertools import chain
data = [[1, 2, 3], ['A', 'B', 'C']]
for i in chain(data):
print(i)
[OUT]
[1, 2, 3]
['A', 'B', 'C'][IN]
for i in chain.from_iterable(data):
print(i)
[OUT]
1
2
3
A
B
C【コラム:複雑な入れ子構造】
注意点として複雑なchain.from_iterable()関数はすべての要素を一つのイテレータに連結しますが、連結操作は一度だけのため複雑な入れ子構造だとそれらは展開されずにそのまま返されます。
[IN]
nested_data = [[[1,2],
[3,4]],
'A',
'BCD',
(5,6)]
for i in chain.from_iterable(nested_data):
print(i)[OUT]
[1, 2]
[3, 4]
A
B
C
D
5
6より深くネストされたデータ構造をフラットにするためには再帰的な展開が必要です。下記に完全に1次元にする関数を紹介します。
再帰関数を用いてイテラブルかどうか検出し、もしイテラブルなら再度1次元化処理を実施
文字列、バイト列もイテラブルである。文字列を分解したくないため"and not isinstance(item, (str, bytes))"を追加して文字列はイテラブルとして認識させないように処理(下記例では'BCD'を分割せず出力)
[IN]
from typing import Iterable
nested_data = [[[1,2],
[3,4]],
'A',
'BCD',
(5,6)]
def flatten(iterable):
for item in iterable:
if isinstance(item, Iterable) and not isinstance(item, (str, bytes)):
yield from flatten(item)
else:
yield item
for i in flatten(nested_data):
print(i)[OUT]
1
2
3
4
A
BCD
5
65.イテラブルの活用
5-1.要素の繰り返し:repeat
repeatは指定したオブジェクトを指定した回数だけ繰り返すイテレータを作成します。timesを省略すると無限に繰り返します。
[API]
itertools.repeat(object[, times])以下に具体的な使用例を示します。出力の通り、引数に渡したオブジェクトをそのまま繰り返し出力します。
[IN]
from itertools import repeat
for i in repeat('A', 3):
print(i)
digits = [1, 2, 3, 4, 5, 6, 7, 8, 9]
for i in repeat(digits, 2):
print(i)[OUT]
A
A
A
[1, 2, 3, 4, 5, 6, 7, 8, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9]5-2.効率的なスライス:islice
isliceはイテラブルの一部分のみを取り出すためのイテレータを作成します。引数としてイテラブル、開始位置、終了位置、ステップ数を指定することができます。開始位置を省略すると0から始まり、ステップ数を省略すると1になります。
[API]
itertools.islice(iterable, stop)
itertools.islice(iterable, start, stop[, step])下記コードは0から9までの数列から2~8の間の数を2ステップごとに出力します。そのため出力は 2, 4, 6となります。
[IN]
from itertools import islice
#iterable=range(10), start=2, stop=8, step=2
for i in islice(range(11), 2, 8, 2):
print(i)[OUT]
2
4
6【listとisliceの違い】
listとisliceは両方ともイテラブルとして扱えますが特徴と目的が異なります。比較表は下記の通りです。

isliceを使用する例として以下のようなケースがあります。特にメモリの小さいマシンで大量のデータを機械学習させるケースなどでは非常に重要な機能となります。
ファイルやネットワークからの大量のデータを扱う際、全データを一度にメモリにロードするのではなく必要な部分だけを読み込む。
無限に続く数列(自然数全体や無限の乱数値)の一部を取り出す
既存のイテレータから特定の範囲の要素だけを取り出したいとき
5-3.複数イテラブルの同時ループ:zip_longest
zip_longestは複数のイテラブルをまとめて同時にループするためのイテレータを作成します。引数として複数のイテラブルを指定でき、いずれかのイテラブルが終わるとfillvalueで指定した値が使用されます。
[API]
itertools.zip_longest(*iterables, fillvalue=None)下記は[1, 2, 3]と['A', 'B']をまとめてループします。['A', 'B']が短いためその分はfillvalueの'*'が使われ出力は (1, 'A'), (2, 'B'), (3, '*')となります。
[IN]
from itertools import zip_longest
for i in zip_longest([1, 2, 3], ['A', 'B'], fillvalue='*'):
print(i)[OUT]
(1, 'A')
(2, 'B')
(3, '*')5-3-1.zip関数との違い
zipとitertools.zip_longestは共に複数のイテラブル(リスト、タプルなど)の要素を同時にループするために使用します。
ただしzip関数は短いイテラブルに合わせて動作し、引数のイテラブルの中で一番短いものが終わった時点で、zip関数の動作も終了します。
[IN]
data1 = [1, 2, 3]
data2 = ['A', 'B']
for i in zip(data1, data2):
print(i)[OUT]
(1, 'A')
(2, 'B')itertools.zip_longestはzip関数と同様に複数のイテラブルを引数に取りますがその動作は長いイテラブルに合わせます。あるイテラブルが他のイテラブルよりも早く終了した場合、そのイテラブルの代わりにfillvalue(デフォルトはNone)を返します。
[IN]
from itertools import zip_longest
for i in zip_longest(data1, data2):
print(i)[OUT]
(1, 'A')
(2, 'B')
(3, None)6.組合せ
組合せを紹介します。例えば実験候補数や検討数を計算する場合などに利用できます。
6-1.組み合わせ:combinations
combinationsは、イテラブルの要素から指定した個数を取り出す全ての組み合わせを生成するイテレータを作成します。
$$
_nC_r = \frac{n!}{r!(n-r)!}
$$
[API]
itertools.combinations(iterable, r)下記では'ABC'の中から2つの文字を取り出す全ての組み合わせを生成します。そのため出力は AB, AC, BCとなります。
[IN]
from itertools import combinations
for comb in combinations('ABC', 2):
print(''.join(comb))[OUT]
AB
AC
BCリスト(数値)でも同様に出力できます。
[IN]
digits = [1, 2, 3]
for comb in combinations(digits, 2):
print(comb)[OUT]
(1, 2)
(1, 3)
(2, 3)6-2.順列:permutations
permutationsはイテラブルの要素から指定した個数を取り出す全ての順列(並べ方)を生成するイテレータを作成します。
$$
_nP_r = \frac{n!}{(n-r)!}
$$
[API]
itertools.permutations(iterable, r)下記は'ABC'の中から2つの文字を取り出す全ての順列(並べ方)を生成します。そのため出力は AB, AC, BA, BC, CA, CBとなります。
[IN]
from itertools import permutations
for perm in permutations('ABC', 2):
print(''.join(perm))[OUT]
AB
AC
BA
BC
CA
CBリスト(数値)でも同様に出力できます。
[IN]
digits = [1, 2, 3]
for perm in permutations(digits, 2):
print(perm)[OUT]
(1, 2)
(1, 3)
(2, 1)
(2, 3)
(3, 1)
(3, 2)6-3.直積(デカルト積):product
productは複数のイテラブルの直積(デカルト積)を生成するイテレータを作成します。repeatパラメータは同じイテラブルの直積を計算する回数を指定します。
[API]
itertools.product(*iterables, repeat=1)下記は'AB'の2回の直積を生成します。そのため出力は AA, AB, BA, BBとなります。
[IN]
from itertools import product
for prod in product('AB', repeat=2):
print(''.join(prod))[OUT]
AA
AB
BA
BBproductを使用すると選択肢の全パターンを計算することが出来るため、下記のようなパスワード解析にも利用できます。
7.計算
7-1.累積和:accumulate
accumulateはイテラブルの要素の累積結果を生成するイテレータを作成します。デフォルトでは要素の累積和(その時点までの全要素の和)が計算されますがfuncパラメータで異なる関数を指定することも可能です。
[API]
itertools.accumulate(iterable[, func, *, initial=None])まずは簡易コードを作成します。下記の通り要素の合計を出力します。
[IN]
from itertools import accumulate
for acc in accumulate([1, 2, 3, 4, 5]):
print(acc)[OUT]
1
3
6
10
15Python上で"+"の処理ができればよいため文字列でも対応可能です。
[IN]
from itertools import accumulate
for acc in accumulate([1, 2, 3, 4, 5]):
print(acc)
text = 'Hello'
for acc in accumulate(text):
print(acc)[OUT]
H
He
Hel
Hell
Hello【funcを指定:累乗】
operator.mul関数がfuncパラメータに指定することでこの関数は二つの引数を取りその積を返します(数列の累積積)。
[IN]
from itertools import accumulate
import operator
data = [1, 2, 3, 4, 5]
result = list(accumulate(data, func=operator.mul))
print(result)[OUT]
[1, 2, 6, 24, 120]8.分類
8-1.グループ分け:groupby
groupbyはイテラブルの要素をキー関数の戻り値に基づいてグループ化するイテレータを作成します。
キー関数を指定しない場合、要素自体がキーとなります。
[API]itertools.groupby(iterable, key=None)[IN]
from itertools import groupby
data = ['A', 'B', 'B', 'A', 'B', 'C', 'C', 'C', 'B']
for k, g in groupby(sorted(data)):
print(k, list(g))[OUT]
A ['A', 'A']
B ['B', 'B', 'B', 'B']
C ['C', 'C', 'C']len()と組み合わせることで数をカウントすることもできます。
[IN]
for k, g in groupby(sorted(data)):
print(k, len(list(g)))[OUT]
A 2
B 4
C 3参考記事
あとがき
今更再学習しないといけなくなるとは・・・
結構PandasやNumpyでできるものもあるけど、組合せに関しては非常に便利!