【第3回】平均値と中央値-後編

前回の記事に引き続き、都道府県別人口と面積のデータ分析を表計算ソフトを使って行います。
前回の復習
平成27年(2015年)の都道府県別人口と面積のデータを使います。

人口 平均値:270万4144人 中央値(24位):168万8177人
面積 平均値:8042㎢ 中央値(24位):6097㎢
でした。どちらも極端な値を持つデータにより、平均値が中央値と比べて高くなっていました。
今回はこれを詳しく見てみたいと思います。平均値が中央値に比べて高いといいますが、平均値以上の値を持つ都道府県は全部でいくつあるでしょうか。これを表計算ソフトの関数を使って調べてみたいと思います。
順位付け
RANK関数
今回の目標の前にまずはランキングをつくってみたいと思います。ソート機能を使って並び替えたものに対して、上から順に付番をしてもよいのですが、ここではRANK関数を使ってみたいと思います。
Googleスプレッドシートでは、次のように使います。

セルG4に =RANK(F4, F4:F50)を入力します。
F4(北海道の人口)はF4~F50(47都道府県の人口)の中で何位かが出力されます。これは大きい順、つまり「降順」に並べたときの順位です。
上の数式は省略せずに書くと、=RANK(F4, F4:F50, 0)で、最後の0が降順を表します(0のときは省略可能)。小さい順、つまり昇順に順位付けをしたいときは最後の0を1にします。ゴルフのスコアのように小さい方が良い順位にしたい場合がそれに あたりますね。
絶対参照
セルG4の数式 =RANK(F4, F4:F50) をセルG5にコピーしたときに困ったことが起きます。前回の記事で便利だと感じた「相対参照」が原因です。

セルの相対的な位置に合わせて数式で参照されるセルが自動的に変わることにより、コピー後の数式は =RANK(F5, F5:F51) になってしまいます。
RANK関数内の最初のF4(北海道)がF5(青森県)に変わってくれるのはとても助かります。問題は後ろのF5:F51です。これは、青森県の人口の入ったセルから沖縄県の人口の入ったセルの1つ下のセルまでを指しており、1つずれています。ここは、数式が自動的に変わらないで欲しく、F4:F50のままにしたいわけです。
そこで、数式をどこにコピーしても参照するセルを変えないようにする参照方式である絶対参照を利用します。行番号と列番号の前に$(ドル)をつけてセル番地を記述したものです。

つまり、
セルG4 =RANK(F4, $F$4:$F$50)
↓ コピー
セルG5 =RANK(F5, $F$4:$F$50)
ということです。これにより、セルG5の数式は「F5(青森県の人口)はF4~F50(47都道府県の人口)の中で何位か」を出力するものになりました。
これをG6~G50にもコピーすることで47都道府県の人口が多い順のランキングが完成になります。中央の24位は鹿児島県でありことが分かりましたね。

面積についても同じです。セルI4に = RANK(H4, $H$4:$H$50) を入力します。H4:H50を入力後に、WindowsのPCならばキーボードのファンクションキー「F4」を押すと一発で「$H$4:$H$50」に変わってくれます。
これをI5~I50にコピーして完成になります。
ここまでで、スプレッドシートのSUM関数、AVERAGE関数、RANK関数に加え、相対参照・絶対参照の考え方を学びました。それでは最後に今回の記事の目標である「平均以上の都道府県数のカウント」をやってみます。
今回の目標へ
COUNTIF関数
もう少しだけ回り道をします。「ある範囲の中にある特定の条件を満たすセルの数」を数えるCOUNTIF関数について少し慣れておきたいと思います。
まず、このスプレッドシートの列Cに「関東」や「近畿」などの地方区分を入力します。下記サイトの8区分を参考にしました。

それでは、試しに地方区分が「東北」であるような都道府県数をカウントしてセルM9に出力させてみたいと思います。セルM9に次の数式を入力します。
=COUNTIF($C$4:$C$50, L9)
これは、セルC4~C50(47都道府県の地方区分が入っているセル)のうち、L9(東北)と同じ値が入っているセルの個数を出力する関数になります。

これをセルM10にコピーすることを見越して、参照方式を考えましょう。
セルM10では「セルC4~C50(47都道府県の地方区分が入っているセル)のうち、L10(関東)と同じ値が入っているセルの数を求めたい」わけです。従いまして、C4:C50はコピーにより自動的に数式が変化して欲しくないので絶対参照、L9はL10に自動的に変わって欲しいので相対参照になります。
それでは、セルM9の数式をM8とM10~M15にコピーしましょう。
平均値以上の都道府県数を求める
いよいよゴールです。このCOUNTIF関数を使って、人口や面積がそれらの平均値以上の都道府県数を求めてみたいと思います。これも結論から申し上げます。
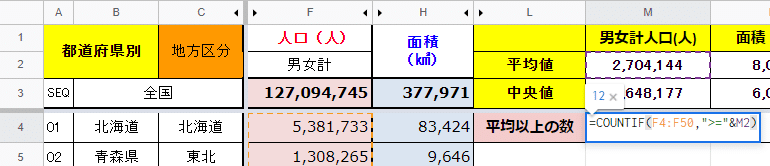
セルM4に
=COUNTIF(F4:F50, ">="&M2)
を入力します。
F4~F50(47都道府県別人口)のうち、 M2(人口の平均値)以上(>=)のセルの数をカウントして出力しなさいという意味の数式です。
数学の「大なりイコール」を「>=」で表します。さらに、これを&でM2と連結をすることで、「M2の値以上」を表しているということです。
かなりややこしいですね。こちらを入力すると12が出ます。つまり、人口が平均値以上の都道府県は12であり、残り35はそれ以下であるということを表しています。繰り返しになりますが、上位の数都道府県によって平均値がかなり上に押し上げられていることが分かると思います。
面積についても同様です。セルN4に =COUNTIF(H4:H50, ">="&N2)
を入力します。こちらも12が出力されます。
都道府県別人口と面積のデータのこれくらいの分析でも表計算ソフトの基本的な操作方法をそれなりに学べることが分かりました。
次回は四分位数について記事を書いてみたいと思います。お読みいただきありがとうございました。