
【第23回】クロス集計-後編

今回もアンケート調査でよく用いられるクロス集計についてまとめます。
高等学校の情報Iの授業で扱いたい、集計に使う手法として下記3つを順に考えているという内容です。
表計算ソフトのCOUNTIFS関数・複合参照
表計算ソフトのピボットテーブル
Pandasのcrosstabメソッド
前回は1.の方法についてまとめました。
よろしければ、前回の記事をご覧ください。
今回は2.と3.についてまとめ、最後に個人的な見解と自身の実践を述べたいと思います。早速、具体例を使ってみてみましょう。
前回のまとめ
次のようなアンケートをある中学生・高校生合わせて500名を対象に行い、その回答結果をクロス集計表にまとめようとしています。
(1) あなたの校種を答えてください。
( )中学生 ( )高校生
(2) これまでにPythonを学んだ経験がありますか?
( )ある ( )ない
回答スプレッドシートは下記の通りで、行ごとにそれぞれの人の回答内容が列A、列Bに入っています。全部で500行のデータです。
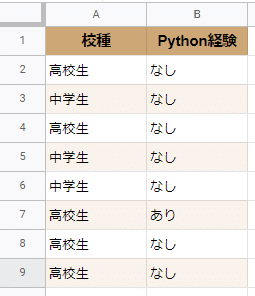
これを集計して、作成しようと思っているのはこのような表です。
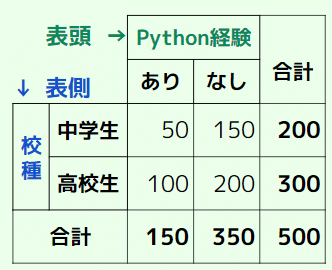
それでは、今回も上記のクロス集計表を作成していきましょう。
方法2: ピボットテーブル
ピボットテーブルとは表計算ソフトにおいて、大量のデータをもとにさまざまな集計を行ったり分析したりできる便利な機能です。
対象集計データは元のデータとは異なる別の表として生成されます。
ここでは、Googleスプレッドシートでの操作をまとめます。
Step1(作成)
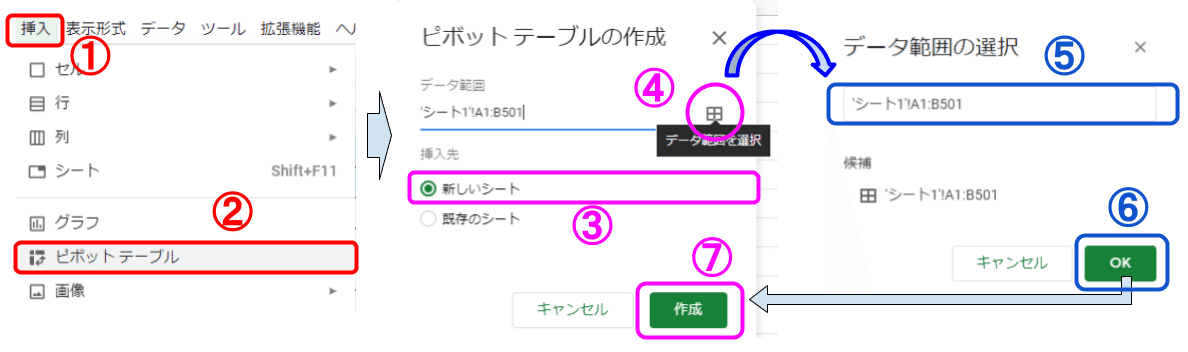
メニューバーから[挿入]→[ピボットテーブル]
挿入表を新規シート、既存シートのいずれに作成するか選択
データ範囲をヘッダ行(列名を入力している行)から選択 → [OK]
データ範囲と挿入先を確認 → [作成]
Step2(行・列項目指定)
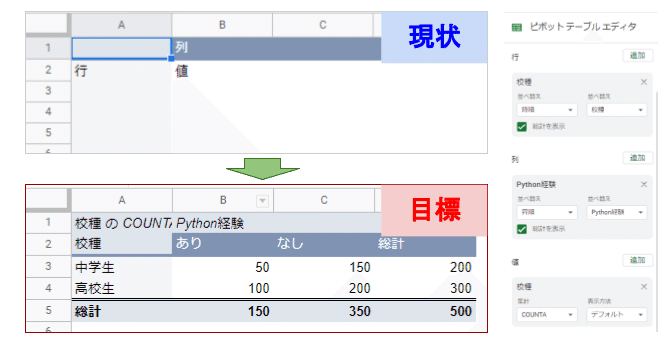
ピボットテーブルエディタの行・列・値の[追加]ボタンを押し、行項目、列項目、出力する値を選択します。今回は次の通りです。
行: 校種 並び替え「降順」
列: Python経験 並び替え「昇順」
値: 校種 集計「COUNTA」 表示方法「デフォルト」
「値」について少し補足します。
こちらは集計方法が「校種ごとのPython経験の有無の人数」か、「Python経験の有無ごとの各校種の人数」の違いであり、どちらでも同じ結果になります。
クロス集計表では「行項目ごとの列項目別集計数」で考えるのが通常の場合ですので、ここでは前者の集計方法を選択し、校種を選んでいます。
また、集計で選択した「COUNTA」は表計算ソフトのCOUNTA関数と同じで範囲の空白セル以外を数えるという意味です。今回は「あり」「なし」という文字列データを数えるので、他のSUMやAVERAGEのような数量を計算する集計方法は意味を成しません。
表示方法の「デフォルト」は単純にカウントした数を表示させるという意味で、他には「行集計に対する割合」などがあります。(下図)
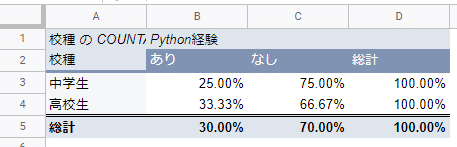
このようにクロス集計表があっという間に作成できます。便利ですね!
方法3: Pandas
最後にPythonのPandasライブラリのメソッドを使ってクロス集計表を作成してみます。Google Colaboratoryを利用します。
Step1(ファイル読込)
元の回答スプレッドシートをCSVファイルとしてダウンロードし、Googleドライブにアップロードします。
私は、マイドライブの「Colab Notebooks」フォルダ内にファイル名「中高生のPython経験調査」で保存しました。
Google Colaboratoryを起動しましたら、まずはドライブのマウントです。
この操作は以前の記事にまとめておりますので、よろしければ、ご覧ください。
まずはPandasライブラリの読込とCSVファイルの読込を行います。
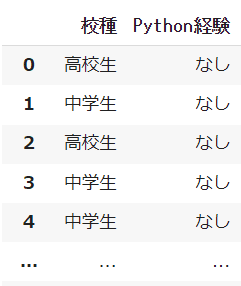
ファイルはデータフレーム(Pandasの表形式)として読み込まれ、これを変数dfに代入し、出力させます。
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/Colab Notebooks/中高生のPython経験調査.csv")
dfこれを実行すると、次のような表が出力されます。
Step2(クロス集計)
このデータフレームdfをクロス集計するメソッドがcrosstabメソッドで次の形で使われます(dfの部分はデータフレームを代入した変数名)。
pd.crosstab(index = df["行項目"], columns = df["列項目"])
ここまでで、とりあえずコードを書き、実行結果を示して、後で補足をすることにします。
dfcross = pd.crosstab(index=df["校種"], columns=df["Python経験"],margins=True)
dfcross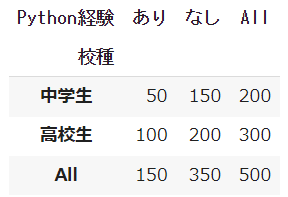
クロス集計表も1つのデータフレーム型になり、これをdfcrossという新たな変数に代入して出力させています。
また、margins = Trueというオプションをつけることで、行ごとの総計、列ごとの総計を出力させることができます。
このように4行程度のコードでクロス集計ができ、こちらも便利ですね!
まとめ
前回・今回でクロス集計の3つの方法を見てきました。
最後にそれぞれのポイントをまとめてます。
方法1:COUNTIFS関数は複合参照も含め、表計算ソフトの大事な考え方を学ぶ上で非常に意義がある。
方法2:ピボットテーブルは、社会で実務を行う上で最も実践的な方法であり、一度は基本操作を学んでおきたい。
方法3:Pandasはデータ分析においてプログラミングを活用することの良さを学ぶ経験ができる点に意義がある。
(個人的好み)
どれも学ぶ意義があり、年間授業計画の中で表計算ソフトやプログラミングをどのように扱ってきたかによる部分が大きいため、これが正解というものはないと思います。
私は、方法3を対面授業で行い、方法1を課題にし、方法2を興味がある生徒向けに解説動画を作成して紹介するという方法をとってみました。
まだまだ迷いがあります。今年度の生徒の習熟度を見ながら、実践と研究を重ねて参りたいと思います。
高等学校で情報の授業をされていらっしゃる先生方、コメントでご意見やご助言をいただけますと幸いです。
次回は、クロス集計した結果をもとに一方の要因が他方の要因に影響を与えていると判断できるかどうかを考える「独立性の検定」を考えていきます。
最後までお読みいただき、ありがとうございました。