
AI PCを買ったはずがCopilot+の要件に満たず早速オワコンになったCore Ultraでもローカルで生成AIを実行してみたい(LM Studio)

やりたいこと
Core Ultraが発表になり、AI PCの売り文句に乗っかってWIndowsPCを手に入れたんだけど、Microsoft様がCopilot+PCを発表したら要件に足りてない・・・
早速オワコンになったCore Ultra搭載で単体GPUが乗っていないPCでも生成AIを手元で動かせるのか試して自分を慰めることにしました。
LM Studioがカジュアルに試せそうなのでやります。
前提
AI PC出た!ということで、Core Ultra発売したときに、喜び勇んで購入したPC(Lenovo IdeaPad Pro 5i Gen 9)。メモリが32GB乗っていて10万円台という高コスパ。
CPUとGPUの共有メモリが32GBで、例えば16GBをGPU側に割り当てても、メモリ不足でPCが重くならないのがポイント。単体GPUで16GBもメモリ載ってるやつは非常にお高い(それこそノートPCもう一個買える)ので、内蔵GPUでのLLM時代来ちゃうんでは!?という期待。
かつ、NPUも別途搭載しているので、AI PC待ったなし!というのも期待していた。
そう、Copilot+PCが発表されるまでは・・・
Copilot+PC、とても良さそうですね。Snapdragonが載ったPCというだけでも欲しいのに、強力なNPUが載っているということでとても欲しい。
さて、とはいえ当初目論んだ通り、ローカルでLLM動かせるのではないだろうか?ということで、試してみたいなと思っていたところ、こちらの記事を見て、「お、何か簡単にできるっぽいぞ」と思い、腰の重くて上がらない男から重い腰が上がる男になりました。
余談だけど、この記事のプロンプトの活用方法はとても楽しそう。というか、自分好みのAIを作り、そのAIと思い出を作りながらいつでも会話できるようにしていくプロンプトの使い方がなるほどと思いました。
使えるトークン数が増えた故に、RAGとかを使うまでもなく、無料でAIキャラクターとの会話が楽しめる世界になったのだなーと。
実際にやってみる
LM Studioの使い方は、公式からダウンロードしてインストール、モデルを選択してメモリにロードするだけ。簡単です。
モデルはアプリのホーム画面にずらりと表示されるやつが、メジャーというかサイズと速度のバランス的におすすめ何だと思います。

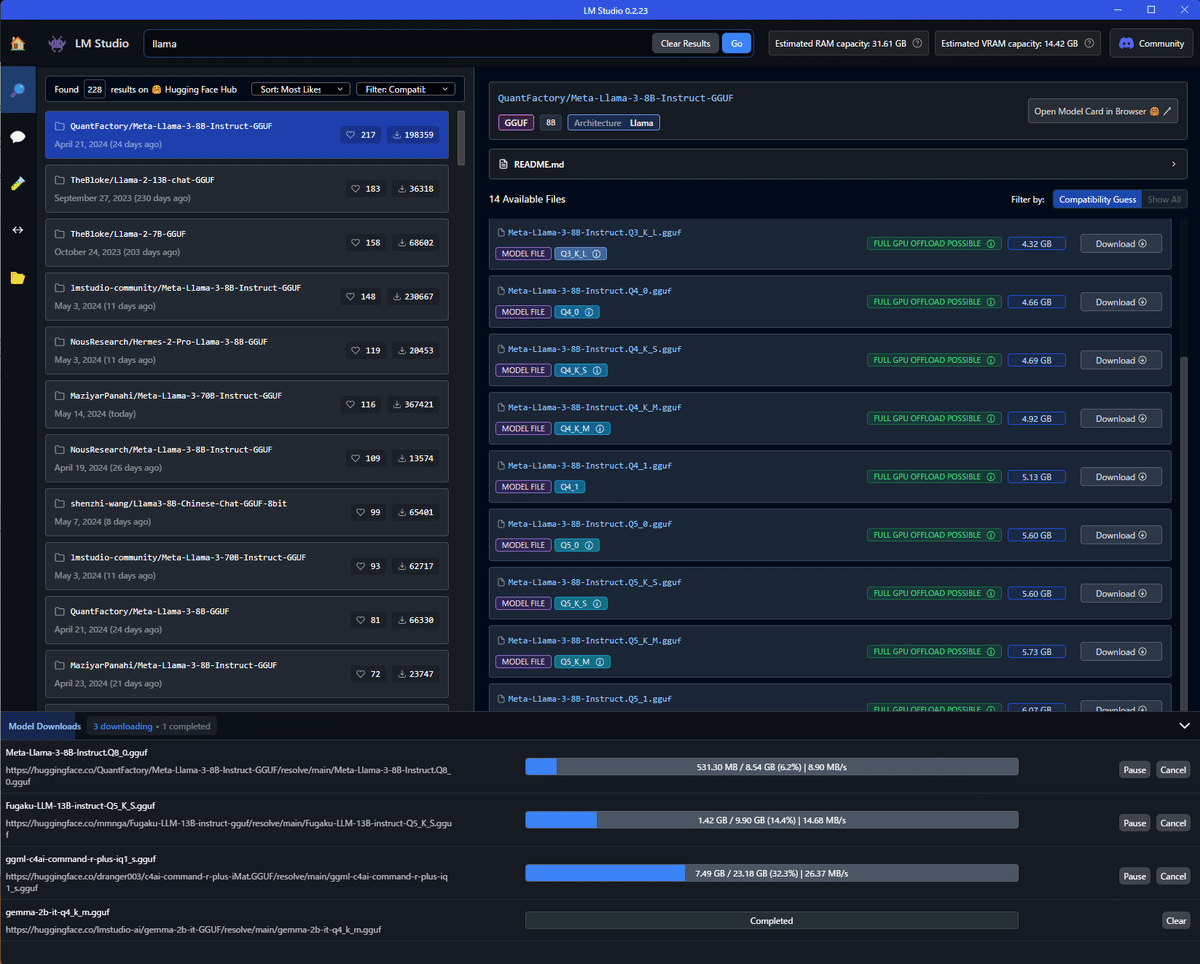
左のツールバーから検索アイコンを選択すると、モデルの検索画面になります。Hugging Faceから利用できるモデルを検索して、この画面でダウンロードができます。
自分のPCで実行できるかは、右に出てくるモデルの表示を確認すれば良いです。モデルのサイズがGPUメモリに収まるかを表示してくれています。
以下ではFULL GPU OFFLOAD POSSIBLEとグリーンになっているので、メモリにすべて載せられるモデルということです。
同じモデルでもたくさんの選択肢が出てきますが、左側では一番スターの多いものを選べばいいのではないでしょうか。(投げやり)
右では軽いものほど精度が低い(量子化されている)ということです。なるべくギリギリいっぱいまでメモリを使うサイズを選ぶのがいいんじゃないでしょうか。(投げやり)
お好みのモデルのダウンロードが終われば、あとは、左ツールバーでチャットマークを選び、上部でモデルを選択すれば、チャットのやり取りをすることができます。
ChatGPTやGemini同様に、やり取りの経緯を踏まえて回答してくれていると思います。
ちなみにシステムプロンプトは右ツールバーにあるので、どういったチャットボットとして振る舞うかはここで指定してください。


話題のオープンなLLMや、日本語を学習したLLMとかを試してみると面白いです。
MetaのLlama3、GoogleのGemma、MicrosoftのPhi-3、mistralあたりは、4GB程度のメモリでも動くので、試すのに良いと思います。
もう少し頑張ると、Phi-3や、日本語モデルのFugakuやELYZAでも遊べます。
それぞれ速度の差や回答精度、得意分野があるので、取っ替え引っ替えできるのは楽しいですね。
ちなみに左ツールバーでPlaygroundを選ぶと、一度に複数のモデルを読み込んで、一つのプロンプトを複数のモデルに回答させることができます。
使用トークン数やトークンの生成速度も表示してくれるので、比較には便利ですね。


やってみてどうだった
LM Studio、簡単で素晴らしいですね!エンジニアじゃなくても使えそうです。
実際に動かしてみて、テキスト推論であれば、ローカルでもそこそこ動くんだなーという感じ。速度はGPT-4oに比べちゃうともちろんダメダメだけど、GPT-4(Not Turbo)くらいの速度は普通に出る。
ので、お金をかけずにバシバシ叩くような場合には良さそうです。
ただ、今回は日本語でチャットしていたこともあり、やっぱり精度の問題が。言い回しがおかしかったり、変な単語が混ざったりします。まあそれもローカルで遊ぶ分にはご愛嬌、ですね。
もっと大きいモデル、特に自分のPCでは試せなかったCommandR+何かが使えると、もっと実用性が高そうです。
とはいえ、単体GPUも積んでいないノートPC一個でLLMが動くのは面白いし、使い所を考えてみたいと思いました。
APIを叩きたい
LM Studioにはローカルサーバ機能があり、APIを叩くことができます。
APIはOpen AI互換になっているそうで、実際Pythonのサンプルコードではopenaiモジュールをインポートしています。

というわけで、次の記事ではWSLからLM StudioのAPIを叩くところをやりたいと思います。
これができれば、活用の幅は広がりそうです。
以上、読んでいただきありがとうございました!