
哲学者間の相関を知りたい! by Python スクレイピング

思想文化系出身プログラマー行きのKai Fukushimaと言います。前々から哲学の勉強をしてる時に、「この哲学者誰と関係しているんだ、、?」みたいなことがよくあったので、確かめてみました。
検証方法
今回はPythonでWebサイトをスクレイピングして、検証してみました。この検証は、以下の仮定に基づいています。
仮定「関連のある哲学者はより多くの記事の中で同時に言及される」
また、簡単なプログラムなので、Google Colaborateで実行しました。Pythonのバージョンは3.6.9です。
哲学者の抽出
import requests
from bs4 import BeautifulSoup
# Britanicaからphilosopherのリストを取得
def get_philosophers():
philosophers = set()
url = "https://www.britannica.com/topic/list-of-philosophers-2027173#ref327487"
html = requests.get(url)
soup = BeautifulSoup(html.content, "html.parser")
for a in soup.find_all(class_="md-crosslink"):
if a is None:
continue
philosophers.add(a.text)
with open('./philosophers.txt', 'w') as f:
for p in philosophers:
f.write(p + '\n')
return philosophers
get_philosophers()まずは、Britanicaのページから哲学者のリストを抽出します。
Joseph Hall
Franciscus Hemsterhuis
Gustav Theodor Fechner
Friedrich Albert Lange
William of Moerbeke
…
Dāwanī
Nicholas of Cusaこんな感じで667人の哲学者の名前が載ったテキストファイルが取得できました。
文書数の取得
import re
import csv
import requests
import types
import time
from bs4 import BeautifulSoup
# txtファイルを読み込んでリストに
def read_philosphers_txt():
philosophers = []
with open('./philosophers.txt') as f:
for i in f:
philosophers.append(i.rstrip('\n'))
return philosophers
# document数を計算
def get_number_document(philosophers):
with open('./docs_philosophers.csv', 'w') as f:
writer = csv.writer(f)
# 哲学者の二次元配列を作成
n_philosophers = len(philosophers)
print('哲学者の数', n_philosophers)
n_docs = [[0 for _ in range(n_philosophers)] for _ in range(n_philosophers)]
# 文書数を取得
url = "https://plato.stanford.edu/search/search?query="
i = 0
while i < n_philosophers:
j = i
while j < n_philosophers:
time.sleep(1)
queries = []
queries += philosophers[i].split()
queries += philosophers[j].split()
search_url = url + '+AND+'.join(queries)
html = requests.get(search_url)
soup = BeautifulSoup(html.content, "html.parser")
s = soup.find(class_="search_total").text
if s == "No documents found":
pass
elif re.search(r'[0-9]* documents', s):
doc = re.search(r'[0-9]* documents', s)
n = int(re.search(r'[0-9]*', doc.group()).group())
n_docs[i][j] = n
n_docs[j][i] = n
else:
print("error")
j += 1
print(n_docs[i])
# csvに書き込み
writer.writerow(n_docs[i])
i += 1
return n_docs
philosophers = read_philosphers_txt()
print(get_number_document(philosophers))上のファイルを元にStanford of Encyclopedia Philosophyから文書数を取得します。方法としては、検索queryに2人の哲学者の名前を入れてあげるだけです。
ただし、哲学者が667人だと、一処理1秒(負担かけすぎないようにtime.sleepしてます)としてもCombination(667, 2)で222,111秒=61時間かかってしまうので、哲学者の数を先に厳選しておきます。具体的には、哲学者1人で検索して100以上の文献がヒットした人だけにしました。そのコードは上のコードとほぼ同じですので省略しますが、それでも77人いるので、48分かかります。。笑
結果として、以下のようなcsvが取得できました。
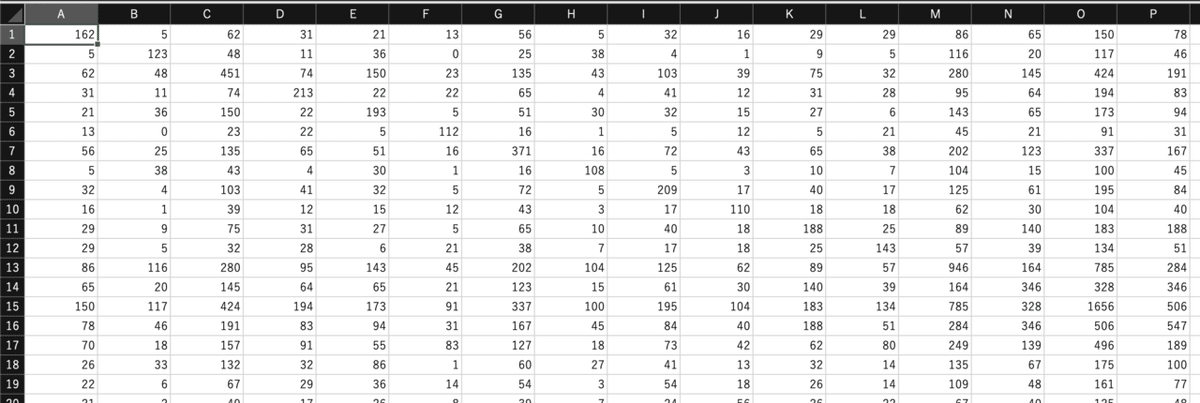
関連の表示
import csv
import matplotlib.pyplot as plt
def most_related(philosopher):
with open('./docs_philosophers.csv') as f:
docs_philosophers = []
reader = csv.reader(f)
for row in reader:
docs_philosophers.append(list(map(int, row)))
with open('./philosophers.txt') as f:
philosophers = []
for i in f:
philosophers.append(i.rstrip('\n'))
# 重みによる調整
i = 0
while i < len(philosophers):
j = 0
heavy = docs_philosophers[i][i]
while j < len(philosophers):
docs_philosophers[j][i] /= heavy
j += 1
i += 1
# 関連の高い順に出力
i = philosophers.index(philosopher)
ns = sorted(docs_philosophers[i], reverse=True)
x = []
y = []
# 上から10人
for n in ns[:10]:
j = docs_philosophers[i].index(n)
x.append(philosophers[j])
y.append(docs_philosophers[i][j])
plt.plot(x, y)
plt.xticks(rotation=90)
plt.show
philosopher = input()
most_related(philosopher)これを実行すると、以下のような結果になります。割と直観的には妥当な結果となっているのではないでしょうか。もし、他に気になる人がいれば、追加しますのでぜひコメントで教えてください。




反省と展望
思ってたよりはいい感じの結果が得られましたが、反省点もいくつかあります。
①統計として有意なのかわからない
②名前が一定でない人や、同名の人、一般的名詞と同じ名前の人など名前の問題がいつくかあった
③マイナーな哲学者(厳選に入らなかった)はおそらくこの手法だと難しい
今後はdocs2vecなんかも使ってみたいですね
この記事が気に入ったらサポートをしてみませんか?