
5. 概念モデルをITシステムに組み込む

本ドキュメントの利用は、https://github.com/kae-made/kae-made/blob/main/contents-license.md に記載のライセンスに従ってご利用ください。
Date:2023/11/26 - Version:1.1.1
はじめに
概念モデリングを行う目的は、現実世界のビジネスで扱う様々な情報の構造をモデル化しITシステムが扱うデータ構造処理の基盤を作成することです。概念情報モデルの使い方について、読者に更に具体的なイメージを持ってもらうために、最近のITシステムで利用可能ないくつかの具体的なサービスを使って組み込む方法を簡単に紹介していきます。
概念情報モデルを利用可能なサービスで実装する
ここで取り上げるサービスは、ITシステムはビジネスの質の向上と規模の拡大を目的として構築するという前提で選んでいます。ビジネスの質の向上と規模の拡大が継続すれば、サービスの利用者と扱うデータ量は当然年々増加していくので、サービスにはこれに対応できるための最低限のスケーラビリティが必要です。また、多くのユーザーがインターネットを介してサービスを利用するので、ゼロトラストの考えに則ったセキュリティも備えている必要があります。
この様な大規模なデータを扱うシステムにおいては、一台のパソコンにインストールされたアプリだけで完結可能な小規模なデータを扱うビジネスアプリの常識は通じません。
ここでは、オンプレミスで運用されているデータセンターやクラウドで提供される、
ストレージサービス
リレーショナルデータベース
No SQL データベース
グラフデータベース、あるいは、オブジェクト(オントロジー)指向データベース
について考えてみます。
ストレージサービス
例えば、Azure Blob Service のような、様々なファイル(Blob)を保持・共有するサービスです。この場合は、前に説明した、概念インスタンス群を表す、CSVやJSON形式のファイルを保持・共有するという非常にシンプルな使い方です。概念情報モデルへの操作は、ストレージサービスが提供するAPIを使って開発者がどう処理するかを、概念クラス図が定義する制約を守るコードも含め、設計し実装していくことになります。概念インスタンス群の情報だけでなく、何らかの形で、概念クラスとその特徴値、及びデータ型、関係の定義も保持し共有できる仕組みも必要です。

リレーショナルデータベース
概念情報モデルの概念クラスと関係は、スーパークラスとサブクラスの関係以外は、基本的にはリレーショナルセオリーの三次正規化を満たします。関係クラスも含め、概念クラスとその特徴値の定義に従って、テーブルを作成し、関係の定義に従って、外部キー等を定義すればリレーショナルデータベースのスキーマが出来上がります。

スーパークラスとサブクラスの関係を持った概念クラス群は、サブクラスを持つ概念クラスはそれ自体単独では概念インスタンスを持たないので、サブクラスを持たない枝葉の概念クラスに注目すれば、その概念クラスの特徴値と関係している一連のスーパークラスの特徴値をすべて持つテーブルを定義するなどすれば、各階層の概念クラスが持っている他の概念クラスとの関係をどう実装するかは、かなり頭を悩ます問題ではありますが、何とかリレーショナルデータベースのスキーマは定義できそうです。
それらを考慮した変換ルールを決めて、概念情報モデルをいったんER図に置き換てスキーマを作成し、データベースを構築すれば、ある程度は実用上問題ないITシステムが出来上がるでしょう。この場合、概念情報モデルで定義された制約はリレーショナルデータベースのスキーマ定義の中にかなりの部分を取り込むことができ、加えて、リレーショナルデータベースで用意されたSQL文を活用することで、概念情報モデルに対する操作のほとんどを実現可能です。
No SQL データベース
例えば、Azure Cosmos DB など、リレーショナルデータベースの様な事前のスキーマ定義がいらない、JSONデータをそのまま保持・共有できるようなサービスです。
基本的にはシンプルなストレージサービスと同じような使い方になりますが、SQLライクなクエリーの利用が可能なので、ストレージサービスよりも少ない開発量での実現が可能と思われます。ただし、No SQL データベースはリレーショナルデータベースの様なスキーマ定義の機能は持っていない(それがNo SQLデータベースの売りですばい)ので、概念情報モデルの制約を満たすための処理の自前開発は必要です。

グラフデータベース、あるいは、オブジェクト(オントロジー)指向データベース
概念情報モデルは、基本的にはノードとエッジで構成されるグラフであり、また、Shlaer-Mellor法のオブジェクト指向分析モデルを基本としたモデルです。前の3種類のサービスで説明したように、概念情報モデルを実装するためには、
概念インスタンス群の保持と共有
概念情報モデルへの操作
概念情報モデルの制約の適用
の3つが必要であり、利用を予定しているサービスがそれらを提供していない場合は自前で処理を設計・実装しなければなりません。逆に言えば、この3つの処理を提供するサービスを使えば、少ない開発量でITシステムに概念情報モデルを組み込むことができます。
その様な利用可能なサービスの例としては Azure Digital Twins が挙げられます。Azure Digital Twinsでは、あらかじめTwin Modelというスキーマを DTDL(Digtal Twins Definition Language) という JSON 形式の言語で定義し、現実の写しとして Twin Graph を保持することができます。一部足りないところはあるものの、本稿で解説してきた、概念情報モデルは DTDL にほぼそのまま変換可能であり、概念インスタンス群は Twin Graph で表現可能です。利用可能な4つのサービスのうち、概念情報モデルを組み込むためのサービスとして、Azure Digital Twins は最も手間のかからないサービスといえるでしょう。

※ 概念モデルから DTDL を生成する実践的な方法は、 「BridgePoint で作成した概念モデルから DTDL 定義を自動生成する」で解説しているのでそちらをご覧ください。
プログラミング言語による実装
概念情報モデルのインスタンス状態に対する操作は、最終的にプログラミング言語で記述されたコードで実行されます。この時、プログラミング言語の型定義の機構を使った、概念情報モデルの定義に基づいたデータ構造とライブラリを作っておくと便利です。C++やC#、Javaといったオブジェクト指向言語は、概念情報モデルと近しい概念に基づいてシンタックスやセマンティクスが決まっているので、概念情報モデルのクラスやその特徴値、関係を、プログラミング言語の class や property を使ってある程度自然に表現できます。ただし、C#やJavaの様なクラスの多重継承を許さない言語を使う場合、概念情報モデルのスーパークラス、サブクラスを表現方法には、interfaceをうまく活用するなどの工夫が必要です。
概念情報モデルの概念インスタンスは、プログラミング言語のインスタンスとしてロジック上で扱えます。ビジネスロジックを実装するアプリケーションコードでは、このライブラリを使って、インスタンス生成・削除、特徴値の参照・更新、問合せを行い、このライブラリが、実装で使っているサービスへのデータ保存、サービスからのデータ取り出しを担います。
ITサービスに関するまとめ
以上、具体的な4つのサービスについて、概念情報モデルをITシステムに組み込む方法を紹介してきました。実装技術の選定は、ステークフォルダーの様々な思惑、開発部隊の技量等、純粋に技術的な観点だけから選べるものではありません。システムの継続的な機能追加・改善の容易さ、運用コストなども重要な選定基準です。参考までに技術的な観点から見た4つのサービスの比較表を紹介しておきます。
アーキテクチャ
さて、概念情報モデルをITシステムに組み込む方法を紹介しましたが、それだけではITシステムを構築のためのピースは未だすべてが出そろっていません。ほかに必要な機能要素は、
View ― ユーザーへの情報提供と操作の受付け
Behavior Model ― 概念情報モデルの状態モデルとドメイン ファンクション
現実世界からの情報取り込みと現実世界への働きかけ
他のビジネスシステムとの連携
等が挙げられます。
上に挙げた項目と概念情報モデルの関係を図に示します。

概念情報モデルに基づいた概念インスタンス群を表す情報は、ITシステムのデータ基盤であり、各項目はそれと連携してITシステムを構成します。
図の最上位の“View”は、ビジネスシナリオに基づいた画像や3Dのグラフィックスを用いた直感的なダッシュボードや、保守作業等、作業の特徴に特化したGUIを持つアプリケーションです。View の層と、概念モデルを実装した Business Logic の層の間で、
View 上の操作 ⇒ 概念モデルのドメイン ファンクション、または、状態モデルのイベント
View 上の表示 ⇒ 概念情報モデルをスキーマにした、概念インスタンス、それぞれの概念インスタンスの特徴値の値、概念インスタンス間のリンク
の様な対応付けを行えば、システムが構築できることが容易に想像がつくでしょう。
View の設計・実装については、人間工学や User Experience 等、View 独自の特性に応じた様々な概念や実装技術を扱わなければならないため、本稿では取り扱いません。
現実世界からの情報取り込みと現実世界への働きかけ
概念情報モデルがデジタル化された現実世界の写しであるためには、現実世界で起こっている事象を取り込んで、対応する概念情報モデルの状態の更新や、人の判断やAIの予測で更新した概念情報モデルの状態に基づいて、現実世界への働きかけをする仕組みが必須です。
センサーやアクチュエータを備えた機械が現実世界との窓口になる場合は、いわゆる IoT(Internet of Things)の仕組みが利用できます。人によるアプリケーションの操作や、ソーシャル上のつぶやき・投稿など、現実世界の事象が人に起因するものである場合は、それらを取り込むサービスを利用して、概念情報モデルに流し込む仕組みも必要です。
他のビジネスシステムとの連携
生まれたてのベンチャー企業でない限り、ITシステムをこれから構築する場合には、お客様向け、取引先向け、社内向けを問わず既に多くのビジネスシステムが稼働しているはずです。中には数十年にわたって運用され続けているシステムもあるかもしれません。そんなレガシーなシステムも含め、連携が必要であれば、それぞれのインタフェースに応じた接続方法の設計が必要です。
以上説明してきた機能要素を使ってITシステムの構築には、「パーツを構成するための骨格」、つまり、“アーキテクチャ”を、あらかじめ決めておくことが非常に重要です。ITシステムは、継続的な保守が必要なのは言うまでもなく、使われれば使われるほど、新しい要求が出てきて新しい機能が追加され継続的に成長していくものです。機能追加の際、それぞれを担当する開発者が勝手な判断で機能を追加していくと、あっという間に、ITシステムは、“おんぼろ煙突”化し、メインテナンスや新たな機能追加で支障をきたしてしまいます。更に悪いことにITシステムを運用しているハードウェアや基本ソフトウェア、サービスは日進月歩で進化するため、ビジネスシステムは適度なタイミングでそれら最新の変更を取り込んでいかなければならない宿命を持っているのですが、いったんこのような状態に陥ってしまったら、新規技術への対応など夢のまた夢になってしまいます。
そうならないためには、ITシステムが、
容易な新規機能追加
データと処理量増加に伴うスケーラビリティ
を担保できるよう、ITシステムの大まかな構成要素と、機能追加の際の従うべきパターンや、新規技術の採用に関するルールなどを、事前に明確に決めて共有し、それを守った開発・保守活動を行うことが重要です。また、市場動向や技術動向の変化に応じて、その時々に最適なアーキテクチャも変わりうるので、アーキテクチャ自身も定期的な見直しが必要です。
本稿で取り上げているITシステムは、現実の世界で起こった事象を起点にデータが発生して、概念情報モデルに取り込まれ、概念情報モデルの状態変化によってビジネスロジックが実行され、そこで加工されたデータが更にそれを必要とするサービスに伝搬していくような特徴を持っています。この様なデータの流れを実現するのが、メッセージ駆動型のアーキテクチャです。このアーキテクチャは、システムを構成する機能のまとまりと、その間でデータをメッセージとして伝達するメッセージブローカーという仕組みから成り立ちます。
ある機能のまとまりが生成するメッセージを、複数の別の機能のまとまりが受信できるチャネルを用意しておけば、新しい機能要件が出てきたときに、それを実現する機能のまとまりを設計・実装し、そのチャネルに接続すれば、既に稼働中のその他の部分に何の影響を与えることなくITシステムに新しい機能を追加できます。この様な形式を、“パブリッシャー・サブスクライバーパターン”と呼びます。
このパターンでは、他の機能のまとまりが動いているかどうかに関わらず、サブスクライブしている出力チャネルにメッセージが送られてきたときだけ機能のまとまりが動くようになっているので、機能のまとまりが動く順番は、メッセージ送受信の依存関係のみで決まり、メッセージ送受信の依存関係がない機能のまとまりは、コンピューティングリソースの許す限り、同時並行的に実行することができます。これは前述のITシステムに必要なスケーラビリティの実現にうってつけです。Digital Twinsを実現するITシステムは、パブリッシャー・サブスクライバーパターンを使ったメッセージ駆動型アーキテクチャを元に設計することを推奨します。
勘の良い読者は、「概念振舞モデル」で説明したデータフローモデル、状態モデル、実行セマンティクスの考え方が、実装上の設計パターンと非常に親和性が高いことに気がついているはずです。この類似性は、どちらかがどちらかを参考にしたものではなく、遺伝的には関係のない生物の種が似たような環境で進化した結果、似たような姿になるのと同じく、現実世界のモデル化、実装基盤を考えたときの自然原理的なものに従った結果であるのではないかと、著者は考えています。

当然、概念情報モデルを保持・共有する仕組みにも、状態の更新を他のサービスに通知するための出力チャネルが必要です。前に紹介した Azure Digital Twins は Twin Graphの変化を受信するための“出力チャネル”を持っているので、便利です。
長年ITシステムを開発してきた読者の中には、データベースを中心に据えたデータ統合型のアーキテクチャが頭の底に沁みついている開発者がいるかもしれません。このアーキテクチャは、一旦データを貯めて、オンデマンドな要求を起点にデータを引き出すPull型のパターンであり、データの出し入れをする人が増えてくるとデータベースへのアクセスがボトルネックになりメッセージ駆動型のアーキテクチャの様なスケーラビリティを担保することは困難です。過去の緩やかな時間の流れの時代のころには妥当だったかもしれませんが、より俊敏な反応を求められる現代のITシステムでは、パブリッシャー・サブスクライバーパターンによるメッセージ駆動型アーキテクチャが適しているので、考えを改めましょう。
概念モデルの概念情報モデル(メタモデル)
概念モデリングは、ありとあらゆる問題領域に対して行うことができます。概念情報モデルの道具立ては、物事を理解するための有効な思考パターンの一つです。その有効性を、初めて概念情報モデルに触れた読者にも感じてもらっていれば、本稿は成功といえるのですが、いかがでしょう。
しかし、初学者が実際に各自が抱える問題領域に概念モデリングを試みようとした途端、何を概念クラスとして、何を関係として抽出したらいいか、途端に途方にくれるのではないかとも、これまでの経験上推察しています。筆者の過去を振り返ると、筆者が満足に概念情報モデルをかけるようになるまで、手法に出会ってから実に8年の歳月が流れました。当時は情報が少なかった事もありますが、なかなかに難しかったのは、
そもそも何を問題領域=ドメインとすべきか
詳細な概念情報モデルは作る価値が本当にあるのか
に確信が持てなかった点にあります。当時は、ソフトウェア開発対象の現実世界をモデル化する事と、ソフトウェア設計上のソフトウェアのモデル化との区別が明確に意識できていなかったことも大きな要因ではあったのですが。
二番目の疑問は本稿の残りを読解することで納得してもらうことにして、ドメインとは何かについて更に詳しく解説していきます。
冒頭で「ありとあらゆる問題領域」と書きましたが、ということは、本稿で説明してきた、概念情報モデルを対象とした問題領域も当然存在してモデル化が可能なはずです。そして、それは事実可能なのです。
“概念情報モデル”の章をもう一度注意深く読み返してみます。すると、概念クラスの候補として、
ドメイン
クラス
特徴値
関係
データ型
…
等が概念の候補として抽出できます。それぞれの候補の間の関係も、前に説明した方法で抽出が可能であり、図による表現が可能です。これらの候補を元に、モデリングを進めて実用可能な程度の詳細度で描いた概念情報モデルを参考までに図示しておきます。

※ 本稿では、ソフトウェア実装技術に頭が慣れ切った読者の勘違いを防ぐために、“概念クラス”や“特徴値”、“関係”など、あえて日本語で用語を表記し解説しています。しかし、“概念情報モデルの概念情報モデル”については、様々な問題領域をモデル化した“概念情報モデル”をデジタル化する事が、厳密に定義する理由であり、ソフトウェア実装技術で扱うことが前提なので、ASCII文字で保持可能な英単語でモデルを記載しています。1990年代散々日本語の文字コードの問題で頭を悩ませた年代の悲しい性です。
※ この図では、本稿で解説した内容を一部含んでいません。何が含まれていないか、考えてみてください。
※ 逆に、この図は、本稿では不明確に説明している点を明確にしています。何を明確化しているか、考えてみてください。
さて、この概念情報モデルで定義された制約に従って、当然、概念インスタンスの状態を定義できるのですが、存在しうる概念インスタンス群とその間のリンク群は何を意味するでしょう?
答えは、様々なドメインに対して作成された概念情報モデルです。試しに以前に例示した”商品販売“の概念情報モデルで試してみましょう。

問題なく“概念情報モデル”をモデル化した“概念情報モデル”のインスタンスとして定義できます。“概念情報モデル”の章でくどくど長ったらしい文章で説明していたモデリング上の縛り等は全て、“概念情報モデル”上のクラスと関係で簡潔に図示化されているのが理解できるでしょう。
もし、理解できない、腑に落ちない場合は、概念情報モデル構築スキルの獲得をあきらめるか、最初に戻ってまた読み直すか、 Knowledge & Experience (https://www.kae-made.jp) に助けを求める(笑)か、いずれかを選択してください。
概念情報モデル自身を概念モデルの道具立てで自己記述しているので、”概念モデルの概念情報モデル”のことを、概念モデリングの”メタモデル”といも言います。
さて、“概念情報モデル”ドメインの“概念情報モデル”が全てのドメインの概念情報モデルをインスタンスとして持ちうる、ということを納得したうえで、この特性を活用した開発作業の自動化を紹介します。
汗水たらして苦労して作成した概念情報モデルを、Azure Digital Twinsで実装する場合を考えます。
Azure Digital Twins を採用する場合、DTDLで記述されたTwin Modelを用意しなければなりません。双方の定義から推定するに
の様に双方の概念を関係付けられます。細かいところでは色々と対応方法を決めないといけない項目もありますが、大筋では、以下の様な手順でDTDLを造っていくことができます。
先ず、概念情報モデルの概念情報モデルの概念インスタンスとして、DTDL化したいドメインの概念情報モデルの定義内容を電子化します。
次に、以下の様なテンプレートを用意します
Class 用テンプレート
{
"@context": "dtmi:dtdl:context;2",
"@id": "<- Model Id ->",
"@type": "Interface",
"displayName": "<- Model Name ->",
"contents": [
<- properties part ->
<- relationship part ->
]
}Property 用テンプレート
{
"@type": "Property",
"name": "<- Property Name ->",
"schema": "<- Data Type Name ->"
}Relatioship 用テンプレート
{
"@type": "Relationship",
"@id": "<- Relationship Id ->;1",
"name": "<- Relationship Name ->",
"target": "<- Target Class Name",
"maxMultiplicity": <- Max Multiplicity ->,
"minMultiplicity": <- Min Multiplicity ->
}概念情報モデルの概念情報モデルの“Domain”のインスタンスを一個取り出し、domain の R1 の関係を辿ってclass のインスタンスを全て取り出します。それぞれのインスタンス毎に、以下を繰り返します。
Domain.NameとClass.Nameから決まりに従ってモデルのIDとモデルの名前を定義し、テンプレートの <- Model Id -> と <- Model Name -> に埋め込む
Class の R2 の関係を辿って Property のインスタンスをすべて取り出し、それぞれのインスタンス毎に、以下を繰り返します。
Property.Nameを元にプロパティ名を決め、Property の R3 の関係を辿って datatype インスタンスを取り出し、テンプレートに従って Property の定義ブロックを完成させ、埋め込む。
Class の R18 の関係を辿って、Binary Relationship のインスタンスを全て取り出し、ルールに従って、DTDL の Relationship の定義方法に従って定義を生成し、埋め込む。
全ての特徴値、関係について変換し終わったら、JSONファイルとして保存。
スーパー、サブクラスの関係をどう変換するか、等、考えなければならないことは色々とありますが、生成の例としては、煩雑なのでここまでにしておきます。この一連の操作で、あるドメインで定義された全ての概念クラスに対するDTDLファイルを、概念情報モデルの概念情報モデルと決められた手順を使って生成するイメージがつかめたと思います。
出来上がった DTDL ファイルを Azure Digital Twins インスタンスにアップロードすれば、Twin Model の定義が行われ、概念インスタンスは Twin として、また、リンクは、Twin 間の Relationship として保持できるようになります。
ここで重要なのは、概念情報モデルからDTDLを導き出す決まりが、“概念情報モデルの概念情報モデル”の “Class” と “Relationship” の定義のみに依存して決められていて、インスタンスには一切言及されていないということです。つまり、一旦概念情報モデルが出来上がってしまったら、現実の世界を映す概念インスタンス群の様々な在りようには全く無関係に作業ができるということです。
くどいようで恐縮ですが、「現実の世界を映す概念インスタンス群の様々な在りようには全く無関係に作業ができる」は、「開発中の開発対象のビジネスシナリオ、アプリケーション機能要件に一切関係なくソフトウェア設計が可能である」との言いかえも可能です。
「概念情報モデル」の章で紹介した、図の表記やテキストによる定義も、実は同じ考え方で概念情報モデルの概念情報モデルのクラスや特徴値、関係に図表現を当てはめれば図が出来上がり、テキストを作成するルールを与えてやれば、テキストによる定義が出来上がるようになっています。
この様なテキストの生成は、Visual Studio の T4 Template の仕組みを使えば容易に自動生成プログラムを作ることができます。
概念モデルからの DTDL 生成の実例を、「BridgePoint で作成した概念モデルから DTDL 定義を自動生成する」で解説しているので、読んでみてください。
「概念情報モデル」の章において、テキストによる定義をYAML風にしていたのは、記述自体の可読性だけでなく、記述内容をコンピュータで読み込んで概念情報モデルのインスタンスとしてデジタル化する際に、解釈するプログラムを簡単に作成できるように、という配慮からということで、種明かしをしておきます。
いかがでしょうか。概念情報モデルを使った様々な開発作業の自動化は、実用上、非常に便利なテクニックです。概念情報モデルを一から自力で作るのは難しくても、概念情報モデルの読み方さえ理解できれば、概念情報モデルを使った開発作業の自動化はできるので、自動生成テクニックの習得をお勧めします。
本稿で解説している”概念モデリングによるソフトウェア開発”は、所謂、MDD(Model Driven Development)と呼ばれるソフトウェア開発手法に分類されるものです。
一般的に MDD はソフトウェア開発における品質・効率を上げると言われており、読者が、本稿で解説している”概念モデリング”以外の MDD 的な技法を選択することはもちろん自由です。
しかし、技法を導入する前に、導入しようとしている技法が、
”設計と実装が、”メタモデル”によるアプローチを採用しているか”
について十分吟味してから選択することをお勧めします。
現代のプログラミング言語仕様やコーディング環境は、大抵の小規模なちょっとした問題解決ならば、その環境を使ってコードを手書きする事が出来るぐらい高性能化しています。採用する MDD のツールの機能が、現代の高性能なコーデイング環境に引けを取らないぐらいのいけてる描画機能と表現力を持っているなら別ですが、メタモデルによるアプローチを持っていない MDD はプログラミング工程の前段階において、限定的な目的を達成するだけの絵を操作性の悪い環境で作成する苦役を追加するだけになってしまう恐れがあるのでご留意ください。
以上で、概念情報モデルで定義されたスキーマと概念インスタンスの管理・保持を Azure Digital Twins で行う方法を説明は終わりにします。次に必要なのは、概念情報モデルの操作を実装する方法です。前述の通り、概念情報モデルの操作は、状態更新の5種類と問合せの3種類があります。これに加えて、メッセージ駆動型のシステムに組み込むための状態変化通知の仕組み、Azure Digital Twins で定義された REST API と対応付け、更に、採用するプログラミング言語で利用可能なライブラリやフレームワークを元に、各操作についてコーディングのパターンを決めれば実装方法が確定します。
後は、ビジネスシナリオにおける概念群への操作のそれぞれに対し、決めたパターンで機械的にコーディングをしていけば、実際にITシステムの中で動くソフトウェアモジュールが出来上がります。
以上を踏まえ、読者がたぶん抱いているであろう、そして筆者が概念モデリング初学者だった頃に抱いていた、「モデルはどこまで詳細に定義すればいいのか」という疑問に対する回答を、ここに記しておきます。
答えは、「コンピュータで自動化するときに必要なレベルまで」です。単に人が理解するためだけのモデルならスケッチレベルで十分です。様々なIT技術をローコストで利用可能な現代、何か作業をするときには、各自が作成している成果物の、後工程での電子的な活用のしやすさは常に意識するべきでしょう。
概念モデルを使った実行テスト
前のセクションでは、作成した概念モデルを、実際にコンピュータ上で実行するために必要なソフトウェア成果物を変換生成する方法の概要を解説しました。
この基本的な仕組みによって、概念モデリングによるシステム開発を選択した人は、安心して概念モデリング専用ツール(例えば BridgePoint)を使って概念モデルの作成に専念できるのですが、当然のことながら、作成した概念モデルが現実と合っていなかったり、記述に間違いがあった場合は、それらの不整合や不具合を含んだソフトウェアに変換されることになり、結果として意図しない(記述通りなのである意味意図した) IT システムが出来上がってしまいます。
そうならないように、概念モデルを使ったシミュレーションを行って、ソフトウェア変換の前に、概念モデルの不具合を取り除くことが推奨されます。
テストの基本的な流れ
モデル化対象のドメインを元に、テストシナリオ群を設定します。
テストシナリオ毎に、
初期状態
テストのトリガー
終了状態
を定義し、概念情報モデルの定義を元に初期状態を満たす
概念インスタンス群と特徴値の値
概念インスタンス間のリンク群
を設定し、テストのトリガーに相当する、ドメイン ファンクションの起動、または、概念インスタンスへのイベント送信を行い、
ドメイン ファンクションの場合
記述したデータフローモデルを実行セマンティクスに従って実行
概念インスタンスへのイベント送信の場合
受信する概念インスタンスの概念クラスで定義された状態モデルで、遷移先の状態を特定
状態のエントリアクションを実行セマンティクスに従って実行
エントリアクションの実行途中で、新たに事象(イベント)が送信されたら、上の2つの項目を繰り返し実行
を概念モデルの記述に従って実施し、一連のアクション実行が完了した時点で、想定した終了条件、つまり、存在すべき概念インスタンス群と特徴値の値、及び、Relationship のリンク群に合致するかを確認していきます。もちろん、合致したらテストは成功、です。
この一連の過程は、概念モデルを描いた図面群を元に、ホワイトボードなどを使って手動で行う事も可能です。
コンピューティング技術を駆使したテスト
「手動でも出来るんだから、図面群を使って手動でかっちりとテストやろうよね…」等というパワハラは今の時代流行りません。
例えば、”図6. 設計用アーキテクチャ”で説明したのと全く同じ要領で、
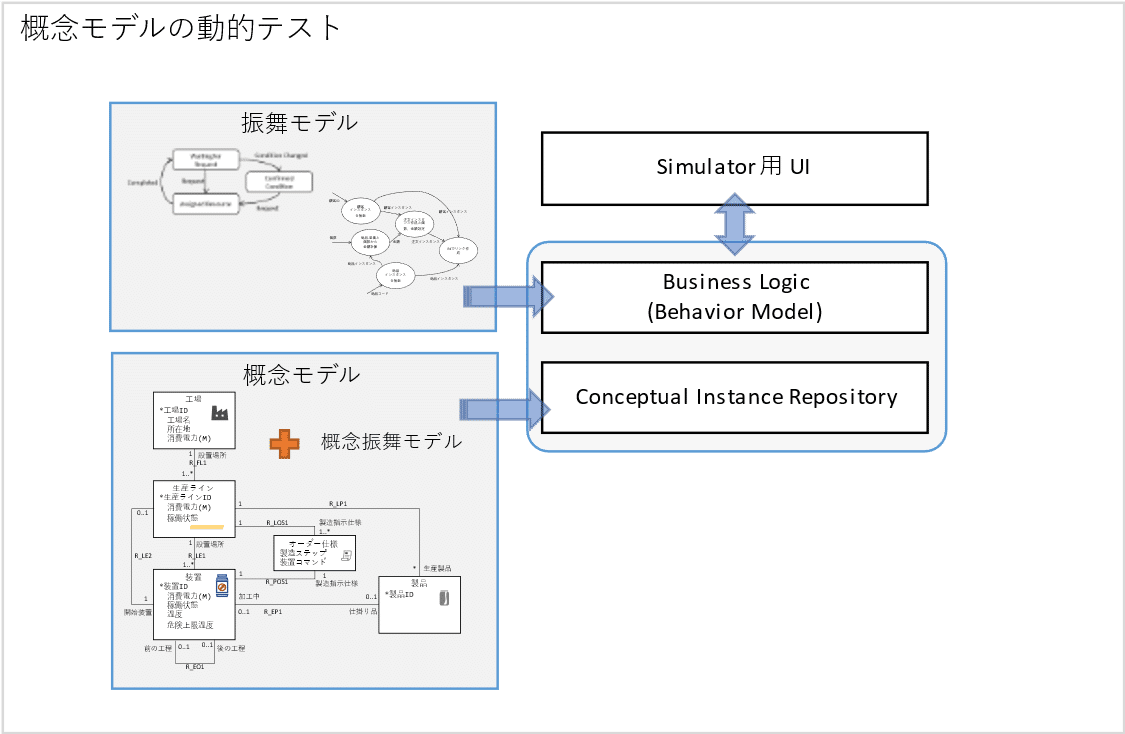
概念情報モデルと概念振舞モデルから、例えば、Windows PC 上で動作するプログラムコード一式を生成し、シミュレーション用の UI を上にかぶせれば、より効率的、かつ、効果的なテストが可能です。
この際、概念モデルから生成するソフトウェア成果物は、IT システム構築用のソフトウェア成果物と一致している必要はありません。
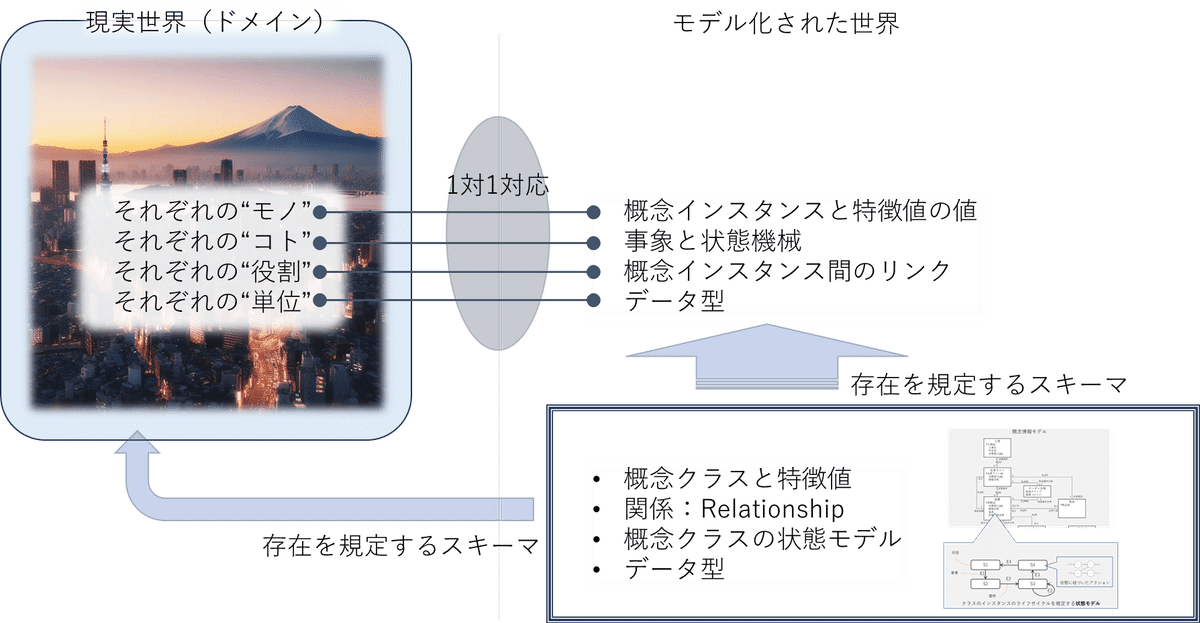
As-Is のモデルと To-Be のモデル
これまで説明してきた通り、概念モデルは、モデル化対象の現実世界(主題領域:ドメイン)の在り様を規定するスキーマモデルであると解説してきました。概念モデルを雛形に、概念インスタンス、とそれに紐づいた特徴値の値、リンクを構成することにより、現実世界の状態スナップショットを表現できるだけでなく、事象発生時の現実世界の状態の変化をも表現できます。
ということは、順調に流れていたビジネスプロセスがある状況になるとデッドロックが発生してデータの流れが止まってしまったり、資源不足で期待していた作業が滞ってしまうような問題を抱えた現実世界を、そのままモデル化してしまうと、当然のことながら、できあがった概念モデルも、全く同じ問題を抱えたモデルになってしまいます。このように、現時点での現実世界をそのままモデル化してできたモデルのことを”As-Is”のモデルと呼ぶことにします。問題を抱えた”As-Is”のモデルをもとにシステムを構築すれば、当然のことながら、問題を書かけたシステムが出来上がってしまいます。一般的なソフトウェア開発で、要求定義に不具合があれば、システムも不具合を抱えるのと事情は一緒です。
何も考えずに思考停止状態で、ただ単に目の前の事項をモデル化しただけで、抱えている問題が解決できるほど世の中は甘くはありません。
概念モデリングは、概念情報モデルをベースに概念インスタンスとリンクを構成し、事象を発生させてやれば、振舞を記述する状態モデルとアクション記述に従って、現実世界のシミュレーションを行う事ができ、現実世界において問題を起こしている原因を特定できます。
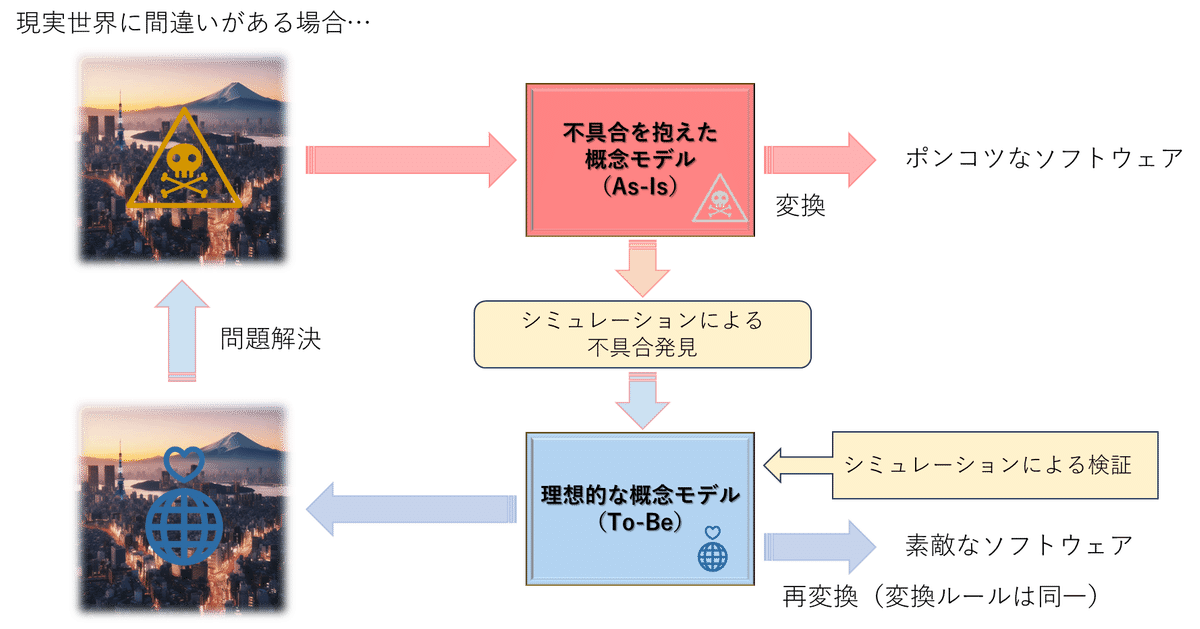
その原因を排除し問題を起こさないモデルのことを”To-Be”のモデルと呼ぶことにします。”To-Be”のモデルは、同様にシミュレーションを行う事によって、問題ないことを確認できます。
”To-Be”のモデルをもとにソフトウェアを実装してやれば、現実世界の問題を解決できるシステムができあがります。
”IoT・Digital Twins 最初の一歩”は、この考え方をベースに議論を進めているので、読んでみることをお勧めします。
”Technique of Transformation” で解説している”変換による実装”を駆使して、概念モデルをソフトウェアに変換している場合には、”As-Is”で使った設計ルール一式をそのまま再利用すればよいので、出来上がった”To-Be”のモデルを使ってソフトウェア一式を再生成してやるだけで、素敵なソフトウェアのできあがりです。
概念情報モデルをITシステムに組み込む基本的な考え方に関する解説は以上です。次は、「ドメインとITシステム構築」で、ドメインの種類と、複数のドメインを統合してITシステムを構築する方法を解説します。