
【生成AI】Bytedance(バイトダンス)、写真に話させるAI技術「INFP」を発表

Bytedance(バイトダンス)は、写真に「話す」能力を与えるAI技術「INFP」を発表した。この技術は、静止した写真に音声を組み合わせることで、自然な動きや表情を再現し、まるで会話をしているような効果を実現する。

INFPの仕組みと特徴
INFPは、写真を動かし「話せる」ようにするため、2つの主要ステップで動作する。
1. リアルな動作の再現
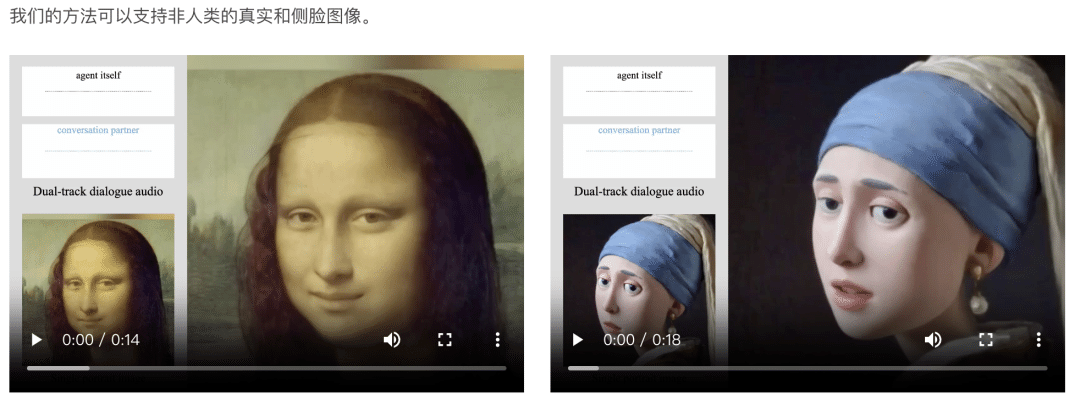
写真の人物に対話中の自然な表情や頭の動きを加える。システムは動画から学習した人間の動きを分析し、静止画に適用して再現する。
2. 音声に基づく動作生成
音声入力をもとに話し手と聞き手の動きを自動で生成する。さらに、AIモデル「拡散変換器」が細かな調整を行い、音声に自然に一致するリアルなアニメーションを作り出す。
INFPは対話の役割を自動的に判断することが可能で、従来の手動で設定する方法より効率的かつ直感的に利用できる。
DyConvデータセットの活用
INFPの性能を支えるのが、Bytedance独自のデータセット「DyConv」だ。このデータセットには200時間以上の高品質な会話動画が収録されており、既存のデータセット(ViCoやRealTalk)を上回る表現力を持つ。これにより、INFPは感情表現やリアルな動作再現において優れたパフォーマンスを発揮している。
さらなる拡張の可能性
現在、INFPは音声入力のみに対応しているが、研究チームは将来的に画像やテキスト入力にも対応させる可能性を探っている。目標は、静止画から人物全身のリアルなアニメーションを生成することだという。
応用分野と慎重な技術管理
この技術は、Bytedanceが運営するTikTokやCapCutといったプラットフォームでの活用が期待されている。たとえば、ユーザーはお気に入りの写真を簡単に加工し、自然な動きや声を持たせた動画を作ることができるかもしれない。
一方で、技術の悪用リスクを考慮し、研究チームはこのコア技術を研究機関のみに提供する方針を示した。これは、Microsoftが高度な音声クローン技術を管理している方法に近い。
プロジェクトの詳細
INFPは、Bytedanceの広範なAI戦略の一部であり、同社の人気アプリを活用することで、AI技術のさらなる発展を支える基盤となる可能性がある。詳細は以下の公式プロジェクトページで確認できる。
技術の特徴
• 音声駆動による表情生成
音声の特徴を抽出・モデリングし、音声内容に一致した表情や動作を生成する技術。
• マルチモーダル融合
静止画像のアバターと動的な音声コンテンツを融合し、高精細なアニメーションを生成。
• 軽量化の実現
効率的なモデル設計と最適化により、生成速度と視覚品質のバランスを確保。
活用シーン
• ビデオ会議やインスタントメッセージング
リアルタイムで仮想アバターを生成し、より楽しく表現力豊かなコミュニケーションを実現。
• バーチャルアバターとライブ配信(Vtuberなど)
自動でバーチャル配信者の動画を生成し、コンテンツ制作の効率を向上。またはバーチャルライバーの配信にも活用可能。
• 教育とエンターテインメント
教育シーンではバーチャル教師やデモンストレーションキャラクターを提供し、エンターテインメントではキャラクターとのインタラクションに活用。
• ゲームとバーチャルソーシャル
ゲーム内のバーチャルキャラクターにリアルな表現力を与え、バーチャルソーシャル環境で動的なアバターを生成。
写真に「話す力」を与えるINFPは、AI技術が人々の表現方法にどのような新たな可能性をもたらすかを示す一歩といえる。