追試研究に参加して勉強したこと②:追試研究のいろは

ケント大学博士課程後期3年の今田です。
前回の投稿の続きになります。今回は、Heyman and Ariely (2004)の追試実験の論文執筆をする中で学んだ「(直接)追試研究のいろは」的なものと、豆知識的なものをまとめていきたいと思います。
なんでそれ?
追試研究論文イントロでは、「なんでこの実験を追試したのか」を説明しなければいけません(Giladが生徒のために作ったレポートのテンプレートには"Choice of Replication"というセクションがあります)。
これはReplication Justificationなんて呼ばれたりするんですが、トップジャーナルに追試研究を投稿する際にめちゃくちゃ重要になります(Psychological Science / Social Psychological and Personality Sciencesに追試論文を投稿した際の裏話回で詳しく書こうと思います。。。)。
今回は、どんなReplication Justificationがあって、どんな研究の追試をするべきだと研究者が思っているのか、に関してさらっと紹介していきます。
どんなReplication Justificationが使われてきたの?
Peder Iagerさんが、過去に出版された85本の直接追試研究を題材に、Replication Justificationの類型をした、というブログポストがあります。
はい、じゃあ興味ある人はこれ読んで、でもいいんですけど、「自分が学んだ追試研究のいろはを紹介する」と言ってしまったので、自分の言葉で、日本語で、簡単に紹介します。
Pederさんの観察によって導き出されたReplication Justificationは大きく分けて5つあります。
(1) Theoretical Impact (理論的なインパクト)
オリジナル研究の理論的な貢献の大きさから追試の必要性を主張する、というのはよくあるReplication Justificationうちの1つです。もしかしたら泥船にのってしまっているかもしれない、、、これめちゃくちゃ怖くないですか?だから追試で、ちゃんとした船かどうか確認するのです。
(2) Personal Interest (個人的な興味)
これは概念的追試に多いjustificationで、「(概念的)追試自体が自分の研究を進めていくうえで重要だ」、という主張がこれにあたります。
(3) Academic Impact
引用件数が多かったり、教科書に絶対載ってたり、なにかしらのacademic impactを表す(とされている)指標を用いたJustificationがこちら。
(4) Public / Societal Impact
アカデミア外へのインパクトの大きさを使ったJustification。オリジナル論文の知見が非学術的な媒体でとりあげられている、政策・ビジネスポリシーに影響を与えている、実用的な示唆に富んでいるなど。
(5) Methodological Concerns
オリジナルの知見に疑義がある場合(とりわけ手法や統計などにおかしな点がある、明らかに間違いがある)がこのJustificationにあたります。自分が追試したHeyman and Ariely (2004)、にはいくつかおかしな統計結果の記載がありました。この論文はPsychological Scienceに出版されたので、追試論文をPsychological Scienceに投稿したんですが、編集者の方はこれをデスクリジェクトしたものの、おかしな統計に関するフォローアップを行い、Expression of Concernを出版した、ということがありました。俺たちの追試論文も一緒に出版してくれよ~と思いました。(実はDan Ariely本人もボイスメッセージで、「この追試論文も一緒に出版すればいいのにね」と言ってくれました。最近何かと炎上(?)している彼ですが、彼からこの追試研究に対してとても真摯なコメント・フィードバックを頂きまして、この人いい人だな~などと思っています。)
追試を出版するのは大変、という話をする回で詳しく話そうと思っていますが、「この研究面白いから追試した!」といって追試した論文に対して編集者が「お~追試したんだすごいありがとう!」とかいって無条件に査読に回すほどイージーな世の中ではないのです(特に上位の雑誌だと)。
1から5まで全部並べて「俺の追試には価値がある!」と主張しても、「あ、追試したんだ、すごいね、でもその程度の貢献じゃううちの雑誌には載せられないよ」とデスクリジェクトを喰らうこともあるのです(実際に喰らった)。キビシィー!。
どんな研究を追試すべきなの?
これに関しては、先ほど紹介したブログポストの冒頭でも触れられている通り、けっこう論文がでています。ただ、どんな研究を追試すべきなのか、に関してはまだ論じられている段階で、これといったスタンダードは確立されていないのではないかなと思います。BBSのターゲット論文、Zwaan et al. (2018). Making Replication Mainstreamへのコメンタリー(Coles et al., 2018; Hardwicke et al., 2018; Witte & Zenker, 2018)でその辺の話を詳しくしているので、興味がある方は読んでみてください。BBS論文以外だと、Field et al. (2019)もこの手の話についての論文ですね。 こちらもちゃんと説明しようかな、と思ったんですがなんかもう疲れてしまったので今回は勘弁してください!
ちなみに、Zwaan et al. (2018)は直接追試研究の価値について論じた論文で、自分の追試の価値を売るための段落を執筆する際に大変お世話になりました。追試論文執筆の前に目を通してみると良いと思います。
それ、直接的追試なの?概念的追試なの?
直接的追試はオリジナルをそのまんま繰り返す、概念的追試はなんかちょっと変えてやる、ぐらいのざっくりした区別だけでもいいんですけど、論文を執筆する上ではそれではちょっと困るんですよね。というのも、「なにが直接的追試なのか」に関しては割と多種多様な意見があり、「お前は直接的追試だと思ってるようだが、それは概念的追試だぞ」といった査読コメントが飛んでくることが少なくないからです(はい、私にも飛んできました)。
そんな時に頼りになる論文がこちら、LeBel et al. (2018).

出典:LeBel et al. (2018), Table 1.
こんな感じで、どこからどこまでが直接的追試と認識されるべきなのかを細かく議論しています。言語や文化は"Contexual Variables"に含まれるので、「西洋でやられた実験を日本で追試した」というタイプの追試研究も、サンプル以外がオリジナル実験と同一なのであれば、Exact Replicationにあたります。もちろん、この論文にあるような類型が絶対的に正しい、とは思いませんが、このような客観的な追試研究の類型はとてもありがたいと思います。
Heyman and Ariely (2004)の追試でも、「オリジナルはアメリカの大学生、追試はMTurkとProlific、はいこれは概念的追試!」といった査読コメントを頂きました。「いや、直接的追試だよ」、と返事しました。
どうなったら追試成功なの?
仮に、オリジナル論文が「水素水を飲んだ群は水道水を飲んだ群よりも、算数のテストの得点が有意に高かった (N = 60, d = 0.8)」といった内容だとしましょう。そしてあなたは直接的追試を行いました(N = 400)。
結果A: 水素水を飲んだ群は水道水を飲んだ群よりも、算数のテストの得点が有意に高かった (N = 400, d = 0.8)
結果B:水素水を飲んだ群は水道水を飲んだ群よりも、算数のテストの得点が有意に高かった (N = 400, d = 1.6)
結果C:水素水を飲んだ群は水道水を飲んだ群よりも、算数のテストの得点が有意に高かった (N = 400, d = 0.1)
結果D:水素水を飲んだ群と水道水を飲んだ群を比べると、、算数のテストの得点に有意な差はなかった (N = 400, d = 0.05)
結果E:水道水を飲んだ群は水素水を飲んだ群よりも、算数のテストの得点が有意に高かった (N = 400, d = .15)
さて、どの結果が「追試成功」で、どの結果が「追試失敗」でしょうか。なんとなく察して頂けたでしょうか。そうです、追試の成功失敗は「有意か非有意か」で片付けていいほど単純ではないのです (Simonsohn, 2015)。じゃあどうやって追試の評価をすればいいのと思ったそこのあなたにお勧めしたいのが、LeBel et al. (2019)です。
とても簡単に内容を説明すると、
「オリジナル研究の効果量が、追試研究の効果量の95% CIに含まれているかどうかを加味して、追試の評価をしていこう」
という話です。
もう少し細かく説明すると、オリジナル実験で有意な効果があったか・なかったか、追試実験で有意な効果があったか・なかったか、どちらにも効果があった場合オリジナル実験と追試実験の効果の大きさ・向きは同じなのか、この辺を、追試効果量の95% CIとオリジナル効果量を使ってちゃんと明確に議論しましょう、という感じです(以下の図をご覧ください)。
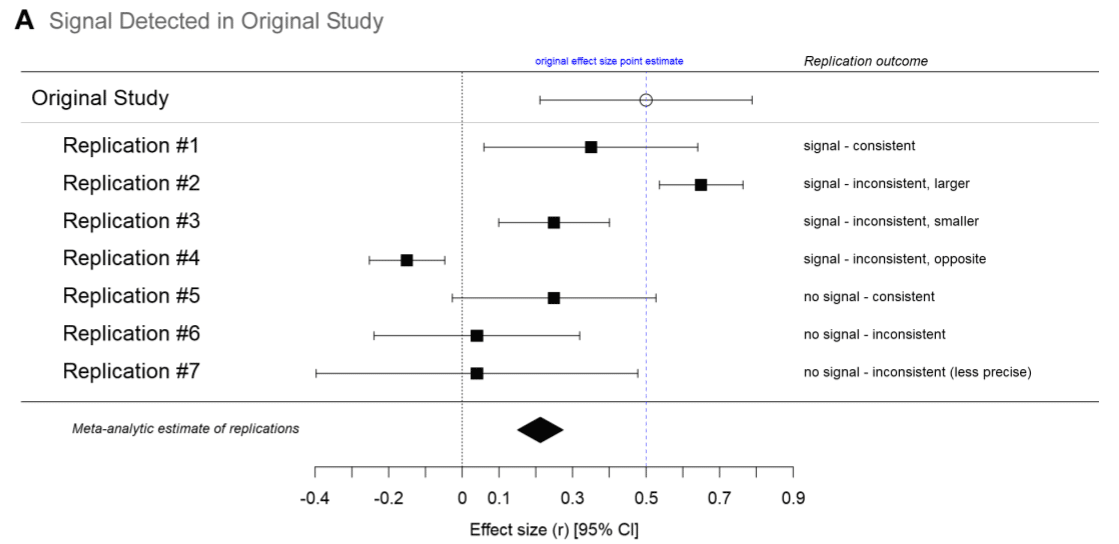

出典:LeBel et al. (2019).
Giladが主導する追試研究の追試の評価では必ずこの評価基準を使っています。Google Scholarで引用件数を確認したところ、2021年10月末の段階ではまだ引用数は46ほどだったので、まだ追試研究界隈(?)でもメインストリームになっていないのかもしれません。
ただ、何をもって追試成功とするのか、があやふやのまま追試を行ってもしかたがないですし、「オリジナルも追試も有意!ハッピー!」で済むような世界ではおそらくないので、今後LeBel et al. (2019)がスタンダードになっていくのではないのかなと思っています。
で、サンプルサイズはどうすんの?
オリジナル実験の効果量をもとに、必要な参加者数を決定する、というのが可能な場合はそれでいいんですが、オリジナル実験が古くて効果量が載っていない・検出不能という場合は少なくありません(Heyman & Ariely, 2004もそうでした)。そんな時に使えるツールや論文を紹介します。
WebPlotDigitizer
「グラフはあるけど細かい記述統計量の記載がない」みたいな古い論文ありますよね。記述統計がないので効果量の計算ができない!とお困りのそこのあなたのためのツールがWebPlotDigitizerです。図表をアップロードすると、なんと自動で記述統計を書き出してくれます。うわぁ、便利。

Simonsohn (2015)とLakens (2015, blogpost)
追試研究をたくさん読むと「Following Simonsohn's (2015) recommendation,」なるフレーズを多々目にします。これは、SimonsohnがPsychological Scienceに出版した”Small Telescopes: Detectability and the Evaluation of Replication Results”という論文内での、「追試サンプルサイズ = オリジナル x 2.5でいこう」というものの引用です。ただ、このルールを使って盲目的にサンプルサイズ設計をするのはダメだよ、よいう話をDaniel Lakens大先生がこちらのブログポストでしているので、一度ご覧になることをお勧めします。
...こんな感じですかね。
今回は、Heyman and Ariely (2004)の追試研究論文執筆を通じて新しく学んだことをまとめてみました。思っていた以上に、追試研究の作法(?)が多くて、色々勉強しながらの論文執筆は結構大変でしたね。
Giladのチームにはオープンサイエンスに熱心なECRがたくさんいて、みんなでお互いの追試論文にコメントをしたり、分析コードのチェックをしたり、協力しながら楽しくOpen & Transparent Replicationをしています。知らないことだらけでなかなか大変でしたが、本当に楽しみながら追試やオープンサイエンスについていろいろ勉強できてよかったなと今は思っています(今も勉強中です)。
この追試論文を書き始める前は、「QRP警察に絡まれたくないからそれなりにやっとく」程度のモチベーションでしたが、今はオープンサイエンス関連の知識を積極的に生かして、自分の研究をより良いものにしておこうと、奮闘しています。
次の投稿では、追試論文の出版が大変な話(Psychological Science / SPPSに投稿したときの裏話)を書こうかなと思っていますが、オープンプラクティスだったりプレレジの話も書いてみる予定です。
ただこのNoteがあんまり読まれないようだったら何も言わずに更新やめます、私、現金な性格なので!
では