
ChatGPTとNoteableによる科学技術情報分析

はじめに
どこかで発表したわけではないですが、表題のスライドをSpeaker Deckにアップしました。noteでも簡単な説明と補足・追加コメントをまとめておきたいと思います。
ChatGPT + Noteableを使うことで、言語的指示(プロンプト)だけでどんなデータ分析ができるか気になったので試してみました。素のChatGPTでは、誤った計算・集計結果を出すため、結果の信頼性の担保に課題があり、実際の分析作業では使いづらいと感じていました。そんな中、プロンプトから、コードを生成・実行・出力するプラグイン「Noteable」を知りました。そこで私が好きな科学技術情報分析において、論文情報収集(arXiv)〜書誌情報分析〜テキストマイニングといったプロセスに沿って試してみました。
なお、汚い状態のままではありますが、実際のChatGPTとのやり取りと生成されたスクリプトも公開しています。参考になれば幸いです。

ちなみに、Noteableプラグインに興味を持ったきっかけは、下記の記事です。
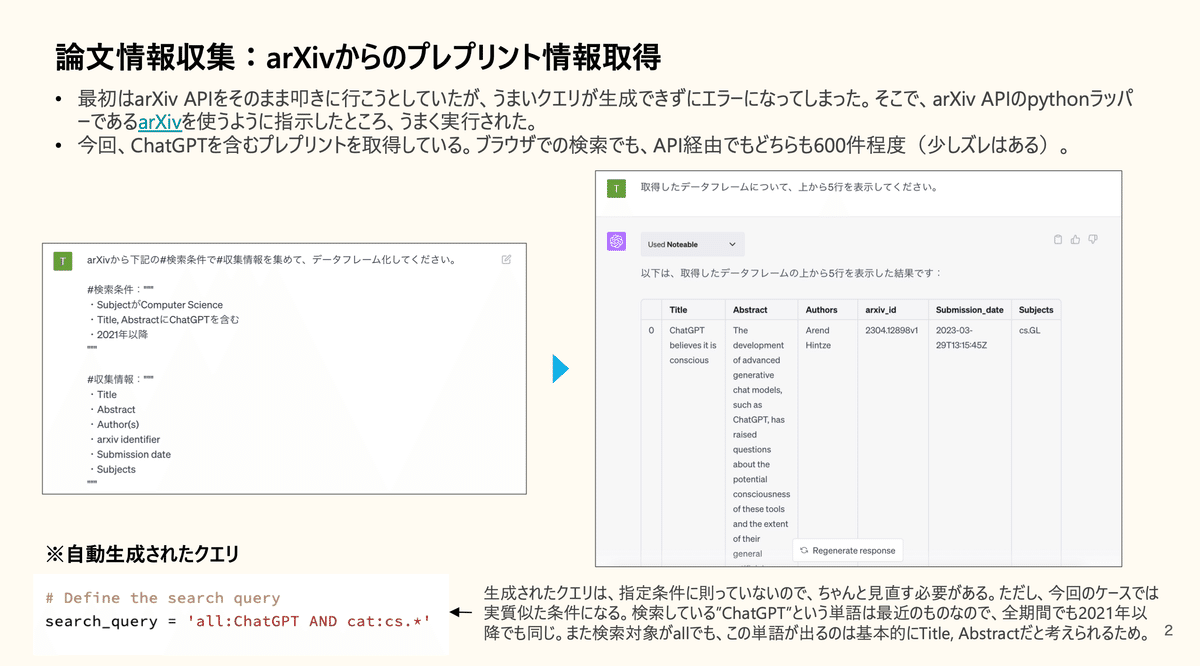
論文情報収集:arXivからのプレプリント情報取得
arXivから"ChatGPT"という単語を含む論文(プレプリント)を取得するように依頼ました。一発ではうまく行きませんでしたが、利用するライブラリを指示することで成功し(arXiv APIのPythonラッパー)、600件取得できました。ただし、生成されたクエリは指示した条件と違うものだったので、結果を鵜呑みせずに確認することが大事です。
ちなみに、あとのプロセスでも同じなのですが、一定レベルのエラーは自ら修復して実行してくれます。このエラー回復能力は有り難いです。
書誌情報分析:時系列推移、カテゴリ集計
プレプリントの時系列推移(年月単位)を可視化したり、Subjectsというカテゴリ情報の集計も難なくできました。
Subjectsトップはcs.CL(Computation and Language)で、cs.AI(Artificial Intelligence)、cs.LG(Machine Learning)が続きます。"ChatGPT"を含むものを収集しているので、ここまでは機械学習技術ど真ん中な感じもします。その後、cs.CY(Computers and Society)、cs.HC(Human-Computer Interaction)等が続き、社会への影響やインタラクションに関する話題も出てきていることがわかります。なお、Subjectsの詳細が気になる方は、arXivのCategory Taxonomyを参照してください。

書誌情報分析:カテゴリ別時系列推移、著者集計
Subjects(カテゴリ)ごとに時系列推移のグラフを作ったり、著者ランキングを作ることも難なくでもきます。
Subjectsの時系列推移を見ると、cs.CL、cs.AI、cs.LGといった機械学習技術そのものに注目が集まり、その後、cs.CY、cs.HC、cs.SE(Software Engineering)、cs.CV(Computer Vision)といった、「社会」「インタラクション」「エンジニアリング」「コンピュータビジョンへの応用」等が立ち上がっています。

テキストマイニング:アブストラクトからのキーフレーズ抽出と集計
キーフレーズを抽出する方法・ライブラリは複数あります。そこで、あえて手段を指定せずに依頼してみました。すると、自動的に必要なライブラリを見つけて、インストールして実行してくれます。
最初はnltkのrakeを使おうとしていたようですが、途中回線が切れてしまいました。そこで再度依頼をしたら、SpacyのTextacyを使い始めたので、時と場合によって挙動が変わることは注意です。
また、出力結果をより良いものにするには、ストップワード等の指示は必須ですので、一定のNLPに関する知識は必要かと思います。「一般的な意味のない用語は省いて」と依頼すれば何かしてくれるかもしれませんが。
あと、集計単位は勝手に文献単位を想定していたのですが、出現回数で集計していました。この辺り、ちゃんと言語化して指示しないといけません。

テキストマイニング:クラスタリングと解釈
Abstractを使って、600件の論文をクラスタリングさせます。ここでもあえて手段を指定せずに依頼してみました。すると、ベクトル化はTF-IDF、クラスタリングはk-means(クラスタ数5)で実行されました。お好みのアルゴリズムがあれば、指示すれば実行してくれると思います。
また、各クラスタのテーマを類推するところも依頼しました。はじめはうまく行きませんでしたが、解釈する上でヒントを提示するとうまく行きました。さらにその解釈を一言で表すことも依頼できるので、各クラスタへのラベリング付与の初期解として良いかもしれません。

一方、こちらから手段を指示するのはいいのですが、ChatGPT自身に良い手段を検討してもらえると良いなと思い、下記の依頼を追加してみました。
Abstractに基づいて、各レコードをクラスタリングし、各クラスタがどんなテーマなのかを教えてください。なお、あなたが思う良いベクトル化とクラスタリング手法・クラスタ数で実行してください。なぜそれが良いと思ったのか、理由も述べてください。
出力結果は下記のようになりました。私としては複数手段を試行錯誤して、最も良い手段を提示してくれる可能性を期待したのですが、そこまでは先のプロンプトでは難しいようです。確かに、「色々と実験して確かめろ」と言っていないので、事前知識から最良だと思われる手段を提示するのは回答としては正しいです(私のプロンプト力不足)。なので、「複数手段を試し、結果を比較検討して最も良い手段を提示してください。」と言えばやってくれるのでしょうか。明確な定量的な評価指標を指定しない、もしくは無い場合でも、自ら比較観点を設定して試行錯誤してくれるのでしょうか。こういった「試行錯誤の自動化」は、どんな問題であれば、どこまでできるのかに興味があるので、今後、実験してみたいと思います。

テキストマイニング:俯瞰可視化(二次元可視化)
Abstractを使って、各論文の類似性に基づいた二次元可視化を依頼しました。600件全体を俯瞰的見ることを意図しています。ここでもあえて手段は指定してません。すると、TF-IDFでベクトル化し、T-SNE法で二次元可視化を行ってくれました。こちらもユーザー自身が好きな手段を提示すれば、その通りやってくれると思います。一方で、より良い可視化図を作るためには、ストップワードや各種パラメータ調整が必要です。この辺りも、「試行錯誤の自動化」ができると面白いなと思っています。予測精度という明らかな評価指標がある予測モデル構築と違い、この手の可視化は正解がないので、どのように機械が試行錯誤するのか興味があります。

おわりに
スライドに書いた通りです。本当に面白いことになって来ましたね。

Appendix. 素のGPTによる集計結果例
素のGPT4とGPT4+Noteableで、テキスト処理・集計をやってもらった結果の比較です。前者では出力された数値がおかしく、集計・計算系タスクをお願いするのは難しいと思っていました。これが今回の施行をしようと思った課題認識です。

このスライドに掲載しているリンクは下記の通りです。
論文や特許調査で、プレイヤー別にキーワードを集計したいときがあります。以前、pythonで集計する方法を下記noteに記載しましたが、Chat GPTにお願いすればできました。
— hayataka🦌 (@hayataka88) March 5, 2023
論文・特許データ等における区切り文字がある時の集計方法 - 組織集計を例にhttps://t.co/Iu0zv4xpKf pic.twitter.com/zZ4V4yqAe6