
学問としてのBusiness Analyticsとは何か

講義の概要
長きに渡る修士課程取得の道、記念すべき最初の講義はInstroduction To Business Analytics というデータサイエンス概要・フレームワークを学ぶ講義でした。終始講義を通じて言われ続けたのは以下の2つの点。「問題の構造化に拘れ、アクションに繋がらなければ分析など意味をなさない」ということ。言われてみれば当たり前の話ではありますが、問題を掘り下げずに打ち手を立案することや、綺麗なチャートを作って分析満足にアクションに繋がらない分析は日常多々あるかと思います。ビジネスはアクションに繋がってナンボであり、” Decison Logic” を限られた時間で高速に練り上げることが今のビジネスパーソンにとって重要であることを改めて実感することができました。
以下に通っているニューヨーク大学のプログラム再掲します。AIの力を使ってビジネスのパフォーマンスを最大化しようという狙いのプログラムです。
⚫︎⚫︎Analyticsとか、⚫︎⚫︎Scienceとかあるけど、結局何が違うのか
Chat GPTの影響もあってか、データ分析に纏わるバズワードが世の中に出回っています。特に学問や職種でも⚫︎⚫︎Analytics、⚫︎⚫︎Scienceという言葉が多数ありますが、一度整理をしておきたいと思います。
・Business Analytics:統計的方法を利用してビジネスの洞察を得て、意思決定を支援する学問(または、職種)
・Data Analytics: ある特定の領域や業界においてデータの処理や分析を行い、有用な情報を発見して意思決定を支援する学問(または、職種)
・Data Science:よりシステマチック(系統的)な理論や高度化されたツールを用いて問題を解決する学問(または、職種)
・Computer Science:計算および情報の性質、起源、応用、制約、能力、および実用性に関する研究を中心とする学問(または、職種)
つまり、上から下にいく程学問や職種としては専門性が高まっていき、文理でいうと理系の要素が高まっていきます。
なぜBusiness Analyticsが必要か、なぜ学ぶべきなのか
「我々の講義はビックデータを取り扱える能力を養うことではない。小さいデータでもいいから洞察を得て、それをストーリーを持って解決策として伝えることだ。」これは教授から言われたことですが、データをたくさん入手できる世の中になったものの、それを活用してビジネスにまで昇華できていない事例が多々あることを意味しています。
直感やひらめきによるアイディアは尊いものですが、その一方で無闇矢鱈に打ち手を繰り出しでも手戻りが発生し、結果として何も生むことができないことも多々あると思います。アインシュタイン博士は分析の重要性についてこう言っています。
”問題の定式化は、単に数学的あるいは実験的スキルの問題であるその解決策よりも重要であることが多い。”
問題解決のプロセス全体の中で最初のステップ、すななち正確な問題の特定をすることが最も重要であることが強調されています。
つまり、Business analyticsを学ぶことの意義はデータドリブンな社会において、定量的に問題を構造化できる力を身につけることと解釈をしています。
分析のフレームワーク
分析のフレームワークについて解説していきます。プロセスは大きく6つの工程に分かれます。文字にするとシンプルに見えますが、実際はその工程を行ったりきたり、評価後に再度最初の工程に戻り、問題の深掘りをすることになります。
ビジネス理解 > データ理解 >データ準備 > モデリング > 評価 > デプロイメント
1、ビジネス理解
・このプロセスはデータ分析というよりドメイン知識や当該ビジネスの原理原則、Key Success Factorが何かを理解できているのか、現場で起きている課題は何かを抽出するプロセスです。定量的というよりは、定性的な課題抽出という方が適切な表現かもしれません。
2、データ理解
・ここからはBusiness Analyticsの本丸に入ってきます。ビジネスに関連するデータの探索する作業、通称EDA(Exploratory Data Analysis)は、探索的データ解析と呼ばれる手法のことを指します。Python・R・STATAを使い基本統計量の計算や可視化をすることによって、データに潜むパターンや構造、異常を明らかにしていきます。
3、データ準備
・次のモデリング前にデータ準備の処理が必要です。モデル構築するためには、モデリングを構築するトレーニングデータと、それを評価するテストデータに2分割する必要があります。これをCross Validationと呼びますが、一般的にはデータから75%をトレーニングデータ、25%をテストデータに分割します。
・また、データと言っても数値データもあれば文字データ、加えて欠損値も多くあるのが現実世界です。モデリングしやすい形にデータを細分化しなければ、機械学習は作動しません。
4、モデリング
・トレーニングデータを活用して予測、最適化するプロセスであり、習したアルゴリズムやその結果を指します。この工程で機械学習を使うのですが、その手法へ別項で紹介します。
5、評価
・作成したモデルをテストデータに当てはめて、モデルの再現性を確認します。評価する指標は機械学習モデルによって違いますが、残差二乗和・R2・F1スコアなど様々な指標があります、
6、デプロイメント
・開発されたモデルを実際の環境に展開し、予測や分析のタスクを実際に実行することを指します。たとえば、顧客の購買行動を予測するモデルを開発した場合、それを本番環境にデプロイして、リアルタイムでの予測や推薦に使用することが考えられます
ちなみに講義では習いませんでしたが、これらを総称してCRISP-DMは、Cross-industry standard process for data mining とも言うそうです。
分析をビジネス価値に昇華させる
Confusion Matrix
Confusion Matrixは、分類モデルの性能を評価するための表で、実際のクラスとモデルによる予測クラスの関係を示しています。二値分類の場合、クラスは「Positive(陽性)」と「Negative(陰性)」の2つです。以下の
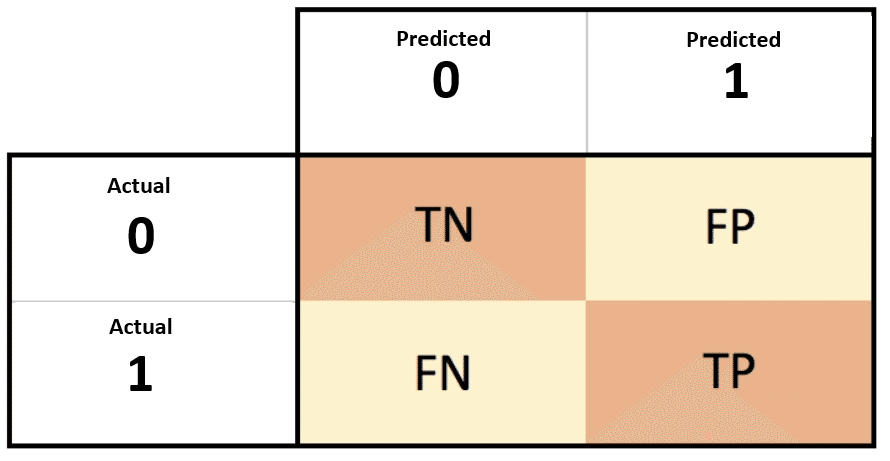
True Positive (TP):正しくPositiveと予測されたデータ数
True Negative (TN):正しくNegativeと予測されたデータ数
False Positive (FP):実際はNegativeなのにPositiveと誤って予測されたデータ数(Type I Errorとも呼ばれる)
False Negative (FN):実際はPositiveなのにNegativeと誤って予測されたデータ数(Type II Errorとも呼ばれる)
これらの基本的な4つの要素を元に、さまざまな評価指標(例:正解率、適合率、再現率、F1スコアなど)を導出することができます。Confusion Matrixは、モデルのどの部分がうまく動作しているのか、どの部分で改善が必要かを明確に理解するための非常に有用なツールです。
Expected Value Analysis
モデルを作成しただけでは、分析をビジネスに昇華するこはできません。Confusion Matrixとセットで生み出された利益・費用を考慮してモデルの良し悪しを決めることが肝要です。
次のステップとしては同様の四章限を活用し、Cost/ Benfitマトリックスを作成します(下の図の右上)。例えば、ある広告キャンペーンを行う場合に得られる利益が10ドル、広告にかかる費用が3ドルであれば以下になります。
Yp:7ドル(10ドル-3ドル) 広告を売って新規顧客獲得
Yn : -3ドル 広告を打つが新規顧客獲得できず
Bp : 10ドル 広告を打たなくても新規顧客獲得
Nn : 0ドル 広告を打たず新規顧客を獲得できず
ビジネスの状況に合わせたCost/Benefitマトリックスに正規化したConfision マトリックスを掛け合わせます。
確率(TP)* Yp + 確率(TN)*Yn > 確率(FP)* Bp
上記の関係式で広告を打った方がリターンが得られることが証明された場合、このモデルの状況においては広告を打つというアクションを実行することになります。

最後に
Chat GPTの登場によって、様々な問題が高速で解決できる時代に突入したと言えるかと思います。しかし、GPTのプロンプトに入力するのは未だに人間であり、正しい質問をしないと求められた答えは返ってきません。つまり問いの立てる行為自身に相対な価値は上がりつつあります。Business Analytics を学ぶ意義、すなわち定量的に問題を構造化させる力を身につけることが重要になってきているのではないでしょうか。正しい、問題設定ができなければ生まれるものはゴミとして取り扱いされてしまうでしょう。もし正しい、問題設定ができれば、AIによって高速に問題解決することが可能かともしれません。
これから長く続く講義の第一回目に問いの設定力の大切さを深く考えさせられました。