
【ComfyUI + AnimateDiff】〜「私の生成したキャラが、いい感じに、動いてくれたらなぁ」を実現しよう〜

こんばんは。
この一年の話し相手はもっぱらChatGPT。おそらく8割5分ChatGPT。
花笠万夜です。
前回のnoteはタイトルに「ComfyUI + AnimateDiff」って書きながらAnimateDiffの話が全くできなかったので、今回は「ComfyUI + AnimateDiff」の話題を書きます。
あなたがAIイラストを趣味で生成してたら必ずこう思うはずです。
「私の生成したキャラが、いい感じに、動いてくれたらなぁ」
これを、今日は、叶えます!
といっても私は触り始めて1週間のど初心者なので、できることは限られてるんですが、それでもこの熱い気持ちを伝えたいんや!
とりあえず前提としてローカルを想定しています。
Colabの使い方はわからん…。
今回実現するメニューはこちら!
A : 4秒アニメーションさせる!
B : まばたきしたり、笑ったりする!
C : 自分のキャラを画像として参照させる!
D : 参照動画と同じ動きをさせる!
E : アップスケールして高品質にする!
F : アップスケール後に顔だけ再描写してより高品質にする!
世の中にはワークフローを公開してくれてる奇特な方がたくさんいらっしゃるので、この巨人の叡智をお借りしつつ、実現を目指しましょう!
ComfyUI、下記辺りがまとまったノードを組めれば私のやりたいことは作れるかもしんない
— 花笠万夜 (@hanagasa_manya) December 25, 2023
なので、ちょっとずつ近づいてきましたね
✅AnimateDiff
✅ControlNet - DW openpose
✅Batch Scheduler
✅IP Adapter
❌FaceDetailer
🔺Upscaler
❌Rembg
🔺(LCM)
(これが実現したかったのです)
とりあえずゴールはこんな感じ。


では一つ一つ解説します。
A : まずアニメーションさせる!

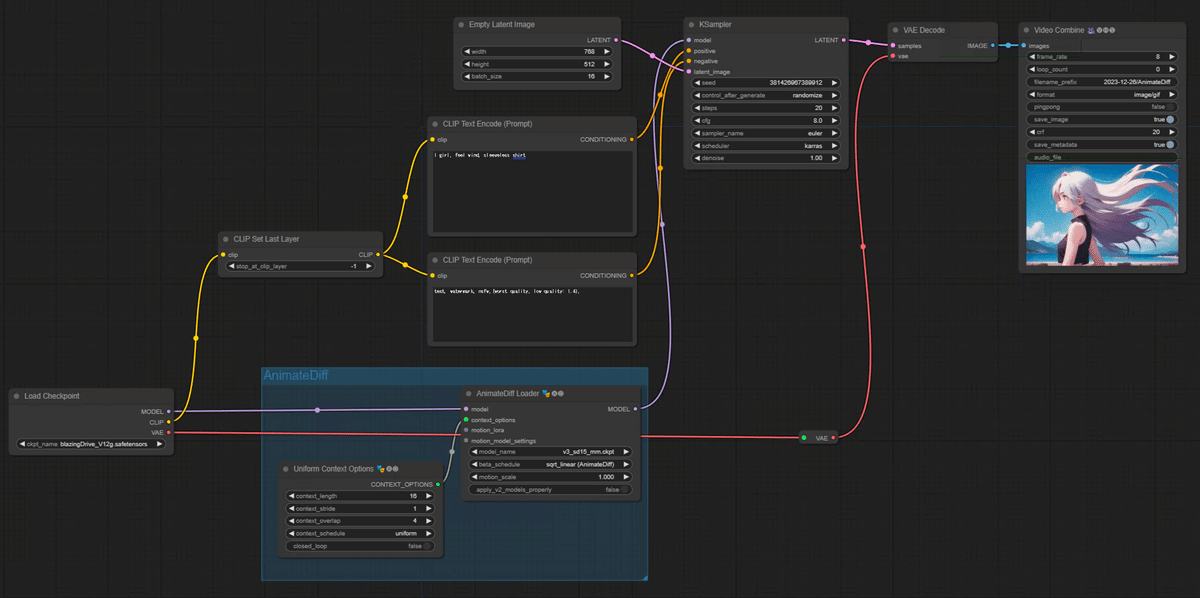
このワークフローのポイント
・カスタムノード「AnimateDiff-Evolved」を使ってます。
ComfyUIでAnimateDiff環境を作るにはAlone1Mさんのnoteを参考にしようね!

・モーションモジュールは最近AnimateDiffの新バージョン「AnimateDiff v3」がでたのでソレを使ってますよ。今のところSD1.5モデルで使えるみたいです。ここで「v3_sd15_mm.ckpt.ckpt」を落としてね。
・「motion_lora」は下記にズームアップ(カメラ拡大)とかパンレフト(カメラ左へ)とか、そういう動きをしやすくなるLoRAがあるので、それをつなげれます。ただLoRAはv2用とあります。また今回はカメラを動かさない想定なのでなにもつけてません。
https://github.com/guoyww/AnimateDiff
・「Uniform Context Options」は全然わかってないので初期値だ!
下記で議論されてるけど、アニメーションの量などを決めるらしい。オーバーラップは、次のフレームのモーションを計算するために使用されるフレーム数だそうで。
https://github.com/Kosinkadink/ComfyUI-AnimateDiff-Evolved/issues/101
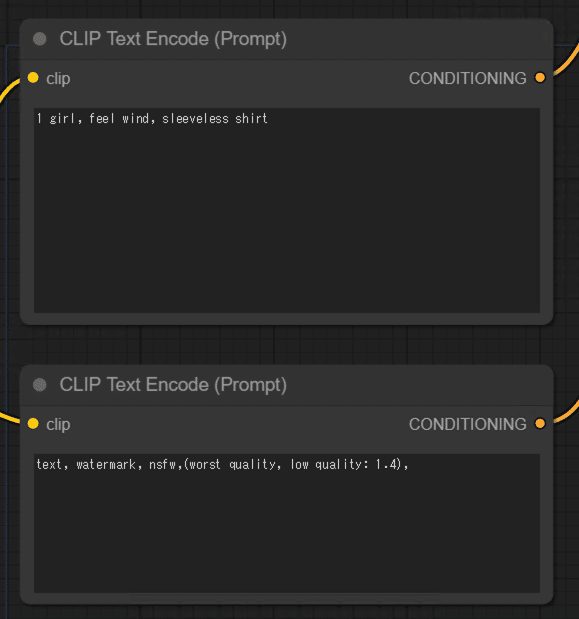
・プロンプトは動きが出やすそうな「feel wind」をいれてます
・最近のモデルはネガティブプロンプトを頑張らなくても、それなりの絵が出ますが、AnimateDiffではソレが通用しません。がっつり記述しましょう。
ここでは「text, watermark, nsfw,(worst quality, low quality: 1.4)」をいれてます。textやwatermarkがでやすいのでこの記述も大事。
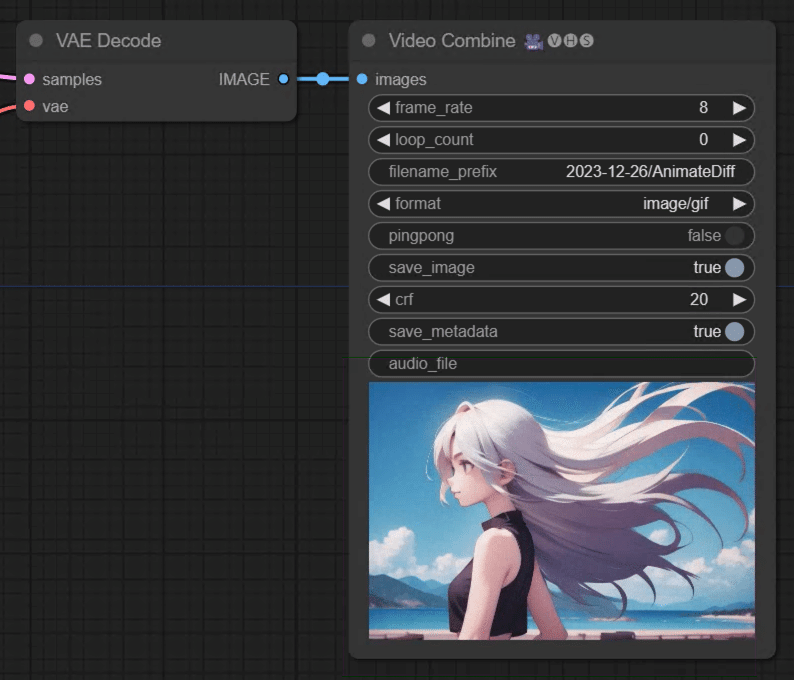
・動画の結果を保存するのはカスタムノード「Video Helper Suite」の「Video Combine」を使っています。このノード超便利。
連番で生成された画像をアニメgifやmp4にしてくれます。
・「Empty Latent Image」のbatch_sizeを16に指定。「Video Combine」でframe_rateを8に指定してるので、2秒(16フレーム)の動画を生成していますね。冒頭で「4秒アニメーションさせる」って言ってましたが4秒じゃないので間違えてますね。まぁいいや。あとで直します。
・ちなみにComfyUIでは保存先が「output」になって無限に溜まっていくのでfilename_prefixで「ディレクトリ名\ ファイルの接頭辞名」を記述しておくと、その該当ディレクトリに「接頭辞名_00001.png」といった形で保存されます。
B : まばたきしたり、笑ったりする!

・カスタムノード「FizzNodes」の「Batch Prompt Schedule」を入れました。ここでプロンプトトラベル(フレームごとに異なるプロンプトを適応)が実現できます。
・最初のフィールドに下記のように記述しています。
要はまばたきしたり、表情変えたり、みたいな内容です。
頭の数字はフレームに該当します。
"0" :"open eyes, expressionless",
"4" :"close eyes, expressionless",
"14" :"close eyes, blush, grit teeth",
"18" :"open eyes, expressionless, make a fist",
"20" :"open eyes, expressionless, make a fist",
"22" :"close eyes, expressionless, make a fist",
"24" :"open eyes, smile, look at viewer, make a fist"
・2番目のテキストフィールドはアニメーションするモノ全体にかかる記述です。
・3番目のテキストフィールドは背景にかかる記述…なのかな?
わかっていません…。
・他の項目もよくわからん、けど動いてるからいいじゃない。詳細はココ読んでくれい。
・とりあえず「Clip Text Encode」のポジティブの代わりに使ってます。そこから次のポジティブコンディショニングにつないでるけど、これでいいのかどうかは怪しい…
C : 自分のキャラを画像として参照させる!
アニメーションに、絵を参照させるにはComfyUIを使ってるとよく聞く「IP Adapter」というのを使います。


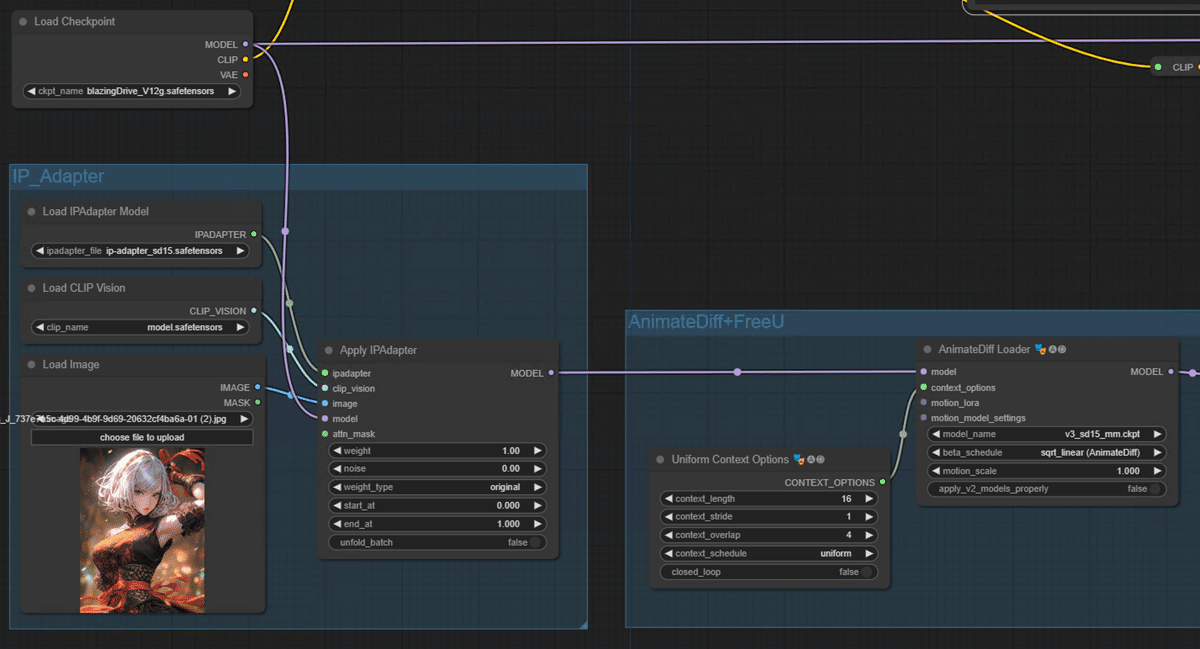

・IP Adapterは謎技術過ぎてよくわかってないです!すごい!
・使うにはIP Adapterモデルと、Clip Visonと、参考にさせたい元絵がいります。モデルとClip Visonの使い方はBakuさんのnoteにめちゃくちゃわかりやすく書いてあります。
・元絵を参照するやり方として、ControlNetをつかってip2pをやるのか、lineArtをうっすら適用させるのか、Tileを指定し、timestep keyframeで徐々に効き目を弱めるのがよいのか、その複合が良いのか、全然わからないので雰囲気でやっています。ただIP Adapterは楽でいいですね。
D : 参照動画と同じ動きをさせる!

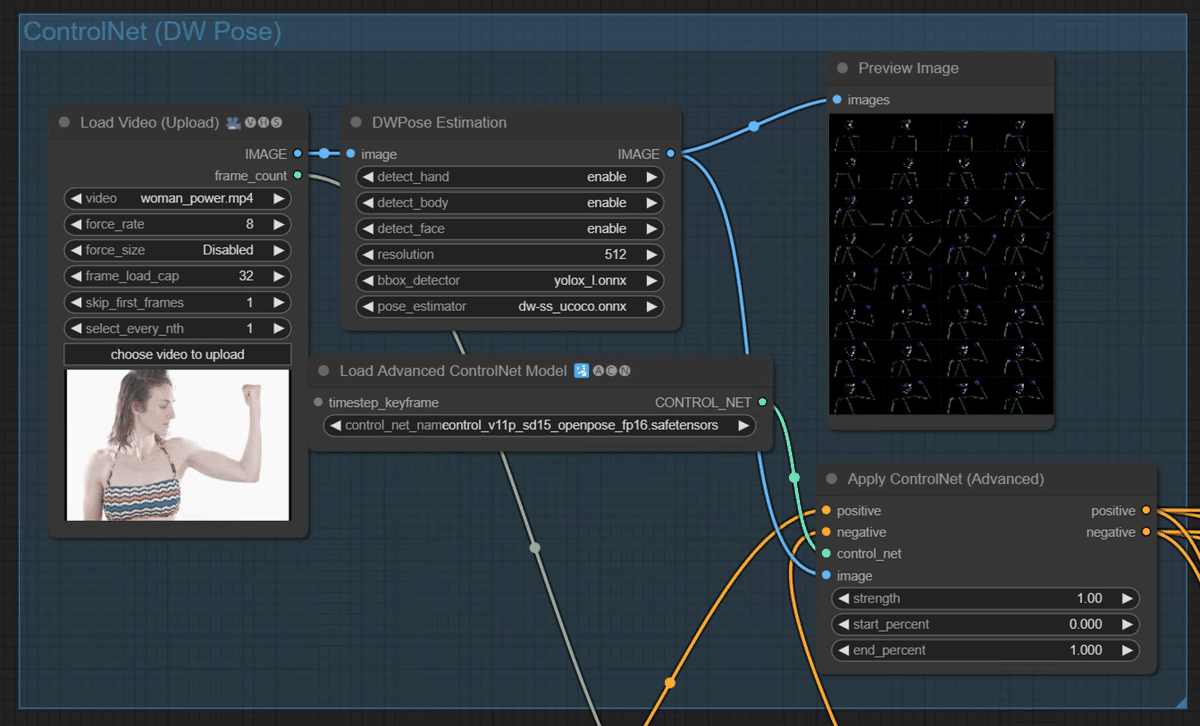
みんな大好きControlNetだ!
参考になる動きの動画はpixaboyさんからDLさせてもらいました。
・この動画を適切なサイズ(768× 512)にトリミングしました。
※Pixaboyさんの素材はライセンスに「Modify or adapt Content into new works」を許可とあります
・ControlNetは「Advanced-ControlNet」「ControlNet Auxiliary Preprocessors」のカスタムノードを使っています。どれ使ってるかは忘れた…。
・ポーズ推定技術はopenposeでなくDW poseを使っています。本家openposeはライセンスがややこしいので…
・「DWpose Estimation」で元動画をオープンポーズ画像群にプリプロセッサーして、そのできたイメージ群を「Appry ControlNet(Advanced)」にimageとして渡しています。
・DWプロセッサーで取得するものを有効化します。結果が微妙だっったらpose_estimatorの種類を変えたりして調整。
チェックのために「Preview Image」ノードをつけとくといいですね。
・ビデオの読み込みは「Video Helper Suite」の「Load Video(upload)」で読み込んでます。force_rateでフレームをどれぐらい細かく分割するかが決まります。よくわからんかったら「Preview Image」ノードつけて目で見て決めるとよいかと思います。(サイズ指定がなぜか「Disabled」になってる…。正しい値を入力すればよいと思います)
・ちなみにControlNetは「positive」と「Negative」のコンディショニングノード同士を繋げれば何個でも繋げられます。
E : アップスケールして高品質にする!

最適な方法を模索中
・Dでできたimageを「Upscale Image(using model)」で拡大しています。「Load Upscale Moder」ノードでアップスケールモデルの「RealEsRGEN」4倍モデルを使っています。
・ただ4倍は大きすぎるので「Upscale Image By」で0.5倍と縮小しています。
・その画像群を「VAE Encode」でLatent状態に戻しKsamplerにLatentとして入力しています。
・ここの「Ksampler」大事ね!ちなみにmodelは「AnimateDiffからのモデルのエッジ」をmodel入力に突っ込んでいます。あっていますか?(Checkpointから?IP adapterから?わからんけど、結果的には悪くないのでいいのでは)
・「Ksampler」Denoiseは0.1にしたけど、もう少し上げてもいいかな…
・このあたりのアップスケール検証は下記のサイトがとても参考になります。
F : アップスケール後に顔だけ再描写してより高品質にする!


・「ComfyUI-Impact-Pack」の 「Face Detailer」ノードを使っています。
・使い方の詳細は青猫さんのnoteがわかりやすいですね!
・アップスケールした「VAE Decode」のimage、ココには大量のBatchイメージが詰まってるので、一度これを「Image Batch to Image List 」でイメージの一覧として扱います。
・そのimageを「Face Detailer」に入力します。
・modelは今は「Checkpoint」のmodelを入れてるんですけど、今考えると、これはもしかして「AnimateDiff」からのモデルを入れたほうがいい気がしてきた。ガクガクしてるのはこれが原因かも?
(と思ってAnimateDiffのモデルいれたらおかしくなったので、あってるのかな)
・「UltralyticsDetectorProvider」は「bbox/face_yolov8m.pt」で顔を検出するように。これをbbox_detectorにつなぎます。
・「SAM Loader」は「sam_vit_b_01ec64.pth」を指定してsam_model_optにつなぎます。
・samplerはお好みの設定で。
ComfyUIでやりたかったことは一本のパイプラインでつながりました!
— 花笠万夜 (@hanagasa_manya) December 26, 2023
ただそれなりに各工程で時間がかかるのでワークフローを分けた方が、試行錯誤ができて良いような…
次は背景合成とSparseCtrl あたりを試してみますかね#ComfyUI #AnimateDiff https://t.co/GlpN6C3uaV pic.twitter.com/Z9vPVJVNQO
というわけで、これがワークフローの全容です。

結構いろんな箇所で自信ないな…
まぁいろいろさわってみてください。
いきなり全部実現するのは大変だと思うので、一つづつ試しながらやっていくといいと思います!
さぁ、自分のAIイラストキャラを存分に動かそう!!!
※今OpenPose動画を楽に作れないかなーと、iPhoneとTDPTアプリとVloidの組み合わせを試してます。また何か進捗あれば𝕏でポストします。
こちらもあわせてどうぞ。