
DynamoDBの設計ベスプラ in 公共系

0.はじめに
DynamoDB(KVS)のベスプラは、RDBとは異なり正規化をせず、
同一TBLに色んな情報を正規化を極力しない形で、縦に情報をもつこと。
というのを出来なかったので、真剣に考えてみたシリーズのVol.1です。
なお、この記事は、以下の特性でした。
① アジャイル案件
② 公共案件&ミッションクリティカルであり、要望はお客様がもっている
= 事業会社やベンチャーのような自分たちの好き放題できない。
また、データミスが許容されるようなシステムではない。
ゆえに、トランザクションも必須。
③ 拡張性が要求される。
・突発的なアクセス急増に耐えるアーキテクチャ。
・要件拡張として、DB設計の着手前に
アクセスパターンをすべて抽出することは不可能。
④ 性能要求を最重視する。
・ターンアラウンドタイム:0.5秒
・NW経由 + 認証認可 + 入力チェック +
他システム連携×2(認証含む) + DB参照+登録後に、
クライアントサイドへのレスポンス含む
⑤ 超大量データになる。
・年間で最大約7億レコード
⑥ RDBの思想が強いメンバが圧倒的に占めており、KVSのノウハウがない。
1.特性に対するベスプラ(サマリ)
さっそく、結論から。
1)特性③、④のため、オンラインサイドはDynamoDB必須。
2)特性①、②、⑤、⑥のため、好き勝手なSQL検索を実現するための
DynamoDBのベスプラは、しない方がベター。
2.ベスプラしない方がベターな詳細
それでは、上記特性化では"DynamoDBのベスプラは、しない方がベター" の詳細な説明をします。
まず、公式のベスプラはGSIのオーバーローディングという手法です。
簡単にいうと、SKやGSI-PKでは、「縦に情報をもつ」方法です。
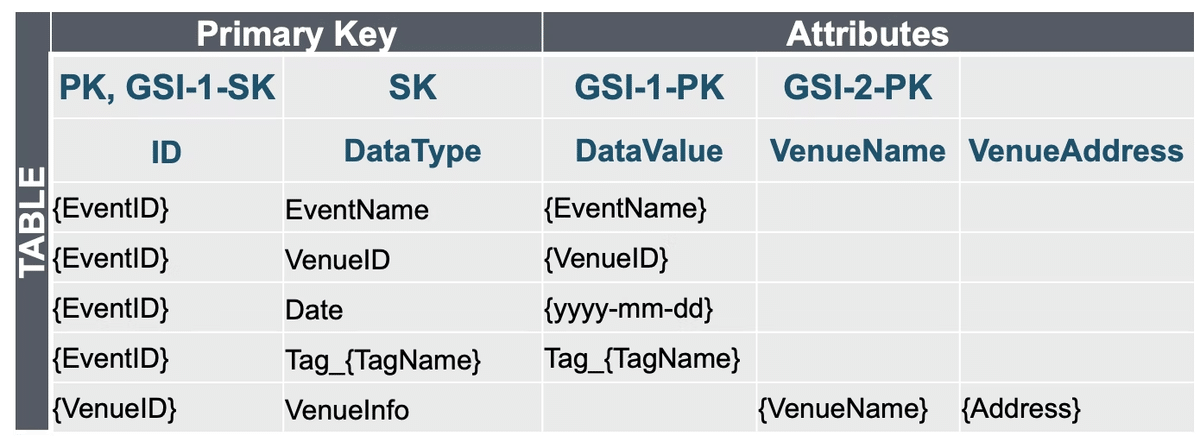
ただし、これは特性①、②、④、⑤、⑥の条件ではなかなか難しいです。
特に"② 公共案件&ミッションクリティカルであり、要望はお客様" 、④ 性能要求、⑤ 超大量データの条件がすべて求められる場合、障壁は一気に膨れ上がります。
① アジャイル案件
⇒ 後から色々と要件が追加されるため、アクセスパターンが定まらない。
②と密に影響してますが、要望は我らではない。

② 公共案件&ミッションクリティカルであり、要望はお客様
⇒ データ移行や、データパッチも適宜必要となるが、
人が理解しにくい構造のため、移行ツールが非常に複雑になる、
ミスの温床でしかない。

⑤ 超大量データ
⇒ ②のトランザクションと関連。
超大量データのため、トランザクションを保持するために、
正規化のDBでは1レコード登録すれば良いが、情報を縦にもつため、
ベスプラに則ると、10レコード程度に一気に増加する。
また、GSI-PKが固定になるため、大量データでは処理が集中する。
つまり、データの偏りが生じるため、性能劣化に繋がる。
⇔ ④の性能要求に反する。
⑥ KVSのノウハウがない
⇒ 事前検証での把握、ないし有スキル者をアサインするのどちらかで
安定した設計が実現できる。
また、②と関連して、データパッチでミスりやすい。
3.次回予告:どうすりゃいいんだ!
特定の条件下ではベスプラに則らない方がベターな理由を列挙しました。
「難しい理由はわかった。うっさい、じゃ?どうすればいいんだ!」
という内容を次回は記載します。
いいなと思ったら応援しよう!
