
【python】最大フロー問題(最大流問題)をnetworkxで計算する【networkx】

【はじめに】
今回は「networkx」をつかって、「最大フロー問題(最大流問題)」を計算してみる。
【例題】
■ 問題
「拠点x → 拠点y」へ「資源」を運びたい。
ルートは以下の図のようになっていて、
・「中継地点:0~3」が存在する。
・「各拠点間」には「数字で記載された輸送量上限」がある。(※)
※例えば「拠点x と拠点1」の間では、輸送上限量は「13」になっている。
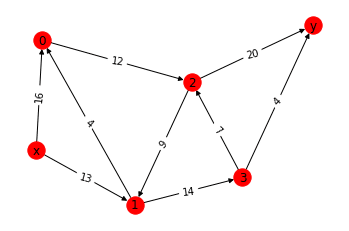
各ルートの輸送上限は越えられない。それを踏まえつつ、
いい感じに輸送量を分配して、拠点x → 拠点y に輸送する量をできるだけ大きくしたい。

【解答例】
実行環境は「Google Colab」。
■networkxのインストール(アプデ等)
もともと「GoogleColab」上に「networkx」はインストールされているのでやらなくてもいいっちゃいい。
!pip install networkx
!pip install --upgrade networkx■Jupyter用マジックコマンド等を仕込む
%matplotlib inline
import matplotlib.pyplot as plt
#import seaborn as sns
#sns.set()【1】サンプルデータの作成(隣接行列)
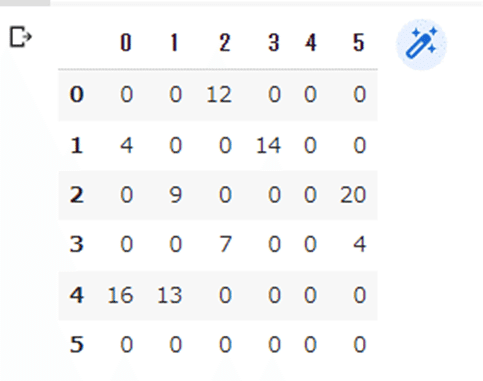
今回のサンプルデータは「隣接行列」をpandasで作成し、それをnetworkxで読み込んでみる。
import pandas as pd
# DF作成
my_sample_data_df = pd.DataFrame([
[0,0,12,0,0,0],
[4,0,0,14,0,0],
[0,9,0,0,0,20],
[0,0,7,0,0,4],
[16,13,0,0,0,0], # 拠点x 相当
[0,0,0,0,0,0], # 拠点y 相当
])
my_sample_data_df【実行結果例】
【2】networkxで読み込んでグラフ作成
この「隣接行列」を「networkx」で読み込んで「グラフ」を生成する。「networkx」では「from_pandas_adjacency()」を使う。
import networkx as nx
# 隣接行列(DataFrame)の読み込み
G = nx.from_pandas_adjacency(my_sample_data_df, create_using=nx.DiGraph)
# 必要に応じてグラフに名前を設定する
G.name = "Graph from pandas adjacency matrix"
nx.info(G)【ここまでの実行結果】
DiGraph named 'Graph from pandas adjacency matrix' with 6 nodes and 9 edges
さらに「ノード情報」や「隣接情報」を出力して確認してみる
# node情報を取得(属性も含む)
print( G.nodes(data=True) )
# 隣接情報(重みの属性)を確認
print( G.adj )【ここまでの実行結果例】
NodeDataView({0: {}, 1: {}, 2: {}, 3: {}, 4: {}, 5: {}})
AdjacencyView(
{0: {2: {'weight': 12}},
1: {0: {'weight': 4}, 3: {'weight': 14}},
2: {1: {'weight': 9}, 5: {'weight': 20}},
3: {2: {'weight': 7}, 5: {'weight': 4}},
4: {0: {'weight': 16}, 1: {'weight': 13}}, # 拠点x 相当
5: {}} # 拠点y 相当
)
▲「ノードのラベル名」は「順番に番号」が振られている。
「エッジ情報」には「隣接行列の値」が「属性:weightの値」として格納されている。
※1:読み込んで生成したグラフを描画してみる
ついでに、エッジ部分に「属性:weightの値」を表示しつつグラフを描画してみる。
まずは、「get_edge_attributes()」を使って「属性:weight」の値を取得する。
# 「グラフG」の「属性(attribute)名:weight」取得
labels = nx.get_edge_attributes(G,'weight')
print(labels)【ここまでの実行結果例】
{(0, 2): 12,
(1, 0): 4,
(1, 3): 14,
(2, 1): 9,
(2, 5): 20,
(3, 2): 7,
(3, 5): 4,
(4, 0): 16,
(4, 1): 13}
次に描画用の座標データを用意する。
※今回は事前に「spring_layout()」をつかって「いい感じに作られた描画用座標データ」を使っていく。
※参考:spring_layout()
#pos = nx.spring_layout(G)
# 何度かspring_layout()を動かして
# いい感じの描画用座標だったもの今回は直埋め
pos = {
0: [-0.77069852, 0.36290033],
1: [-0.16543567, -0.4545243 ],
2: [0.2083616 , 0.15452308],
3: [ 0.53878648, -0.31734415],
4: [-0.81101389, -0.18321122],
5: [1. , 0.43765626]
}エッジ部分に何かしらの文字を表示するには「draw_networkx_edge_labels()」を使う。
▲この関数はあくまでも「エッジのラベルを描画するだけ」で、「グラフ自体の描画は別」なので注意する。
# 以下の通り可変長引数「**kwds」を利用して設定値分離でもOK
other_param={
"node_color":"red",
"with_labels":True
}
nx.draw(G, pos, **other_param) # グラフ自体の描画
nx.draw_networkx_edge_labels(G, pos, edge_labels = labels) # edgeのラベル(重み)部分の描画
【実行結果例】
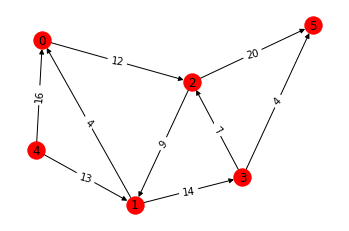
なお、networkxでの描画については以下でも色々と紹介されている。
※2:ノードのラベルをリネームしてみる
ラベルのリネームなどはせずそのまま最大フローを求める計算をしてもよいが、networkxの練習も兼ねてノードのラベルをリネームをしてみる。
「ノードのラベルリネーム」には「relabel_nodes()」を使用する。
mapping = {4: "x", 5: "y"} # リネームデータをマッピング
H = nx.relabel_nodes(G, mapping)想定通りリネームできているかを確認してみる。
# ノード情報を確認
print( H.nodes(data=True) )
# 隣接情報を確認
print( H.adj )【ここまでの実行結果例】
NodeDataView({0: {}, 1: {}, 2: {}, 3: {}, 'x': {}, 'y': {}})
AdjacencyView(
{0: {2: {'weight': 12}},
1: {0: {'weight': 4}, 3: {'weight': 14}},
2: {1: {'weight': 9}, 'y': {'weight': 20}},
3: {2: {'weight': 7}, 'y': {'weight': 4}},
'x': {0: {'weight': 16}, 1: {'weight': 13}},
'y': {}})
先ほどと同じように描画してみる
# 「グラフ」の「属性(attribute)名:weight」取得
labels_w = nx.get_edge_attributes(H, 'weight')
labels_w
# 描画用座標データを用意
pos_h = {
0: [-0.77069852, 0.36290033],
1: [-0.16543567, -0.4545243 ],
2: [0.2083616 , 0.15452308],
3: [ 0.53878648, -0.31734415],
'x': [-0.81101389, -0.18321122],
'y': [1. , 0.43765626]
}
# 以下の通り可変長引数「**kwds」を利用して設定値分離でもOK
other_param2={
"node_color":"yellow", # 今回はyellowを設定
"with_labels":True
}
nx.draw(H, pos_h, **other_param2) # グラフの描画
nx.draw_networkx_edge_labels(H, pos_h, edge_labels=labels_w) # edgeのラベル(重み)を描画
【実行結果例】
※前回の結果と区別するためノードの色をyellowにしている
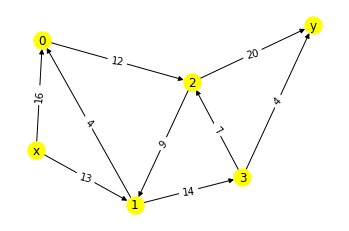
【3】最大フロー問題を解く
「networkx」には様々なアルゴリズムがあらかじめ用意されている。
例えばフローに関するものは以下がある。
今回は単純に「maximum_flow()」を使ってみる。
# グラフに設定した「weight」の値をflow計算に使うエッジ容量(capacity)とみなして計算を実施
#flow_value, flow_dict = nx.maximum_flow(G, 4, 5, capacity="weight")
flow_value, flow_dict = nx.maximum_flow(H, "x", "y", capacity="weight")
print(flow_value)
print(flow_dict)▲「ノードをリネームしたグラフH」を使用しているが、別に最初に生成した「グラフG」でもいい。
【実行結果例】
23
{0: {2: 12},
1: {0: 0, 3: 11},
2: {1: 0, 'y': 19},
3: {2: 7, 'y': 4},
'x': {0: 12, 1: 11},
'y': {}}
つまり、
拠点x → 拠点y に輸送できる最大量は23まで
ということ。(正解)
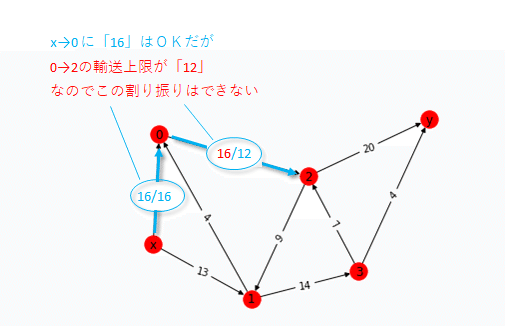
図にすると以下のような感じ。
※比較・参考までに、最初に例として適当に分配したパターンも並べている。
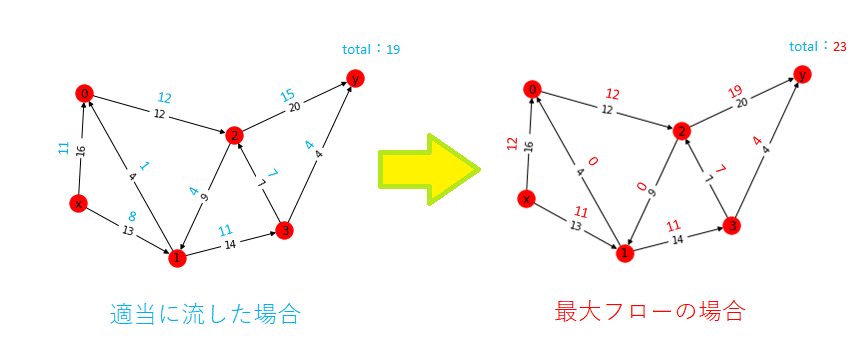
【4】全体コード
最後に全体コードを残しておく。実行環境は「Google Colab」
※1つのセルで実行すると描画されるグラフが重ね書きになるので、適当にセルを分ける、matplotlibのsubplotを使う、不要ならコメントアウトする、など。
%matplotlib inline
import matplotlib.pyplot as plt
#import seaborn as sns
#sns.set()
import networkx as nx
import pandas as pd
# DF作成
my_sample_data_df = pd.DataFrame([
[0,0,12,0,0,0],
[4,0,0,14,0,0],
[0,9,0,0,0,20],
[0,0,7,0,0,4],
[16,13,0,0,0,0], # 拠点x 相当
[0,0,0,0,0,0], # 拠点y 相当
])
#my_sample_data_df
# 隣接行列(DataFrame)の読み込み
G = nx.from_pandas_adjacency(my_sample_data_df, create_using=nx.DiGraph)
# 必要に応じてグラフに名前を設定する
G.name = "Graph from pandas adjacency matrix"
print( nx.info(G) )
# node情報を取得(属性も含む)
print( G.nodes(data=True) )
# 隣接情報(重みの属性)を確認
print( G.adj )
# 描画確認
# 「グラフG」の「属性(attribute)名:weight」取得
labels = nx.get_edge_attributes(G,'weight')
print(labels)
#pos = nx.spring_layout(G)
# 何度かspring_layout()を動かして
# いい感じの描画用座標だったもの今回は直埋め
pos = {
0: [-0.77069852, 0.36290033],
1: [-0.16543567, -0.4545243 ],
2: [0.2083616 , 0.15452308],
3: [ 0.53878648, -0.31734415],
4: [-0.81101389, -0.18321122],
5: [1. , 0.43765626]
}
# 以下の通り可変長引数「**kwds」を利用して設定値分離でもOK
other_param={
"node_color":"red",
"with_labels":True
}
nx.draw(G, pos, **other_param) # グラフ自体の描画
nx.draw_networkx_edge_labels(G, pos, edge_labels = labels) # edgeのラベル(重み)部分の描画
mapping = {4: "x", 5: "y"} # リネームデータをマッピング
H = nx.relabel_nodes(G, mapping)
# ノード情報を確認
print( H.nodes(data=True) )
# 隣接情報を確認
print( H.adj )
# 描画確認2
# 「グラフ」の「属性(attribute)名:weight」取得
labels_w = nx.get_edge_attributes(H, 'weight')
labels_w
# 描画用座標データを用意
pos_h = {
0: [-0.77069852, 0.36290033],
1: [-0.16543567, -0.4545243 ],
2: [0.2083616 , 0.15452308],
3: [ 0.53878648, -0.31734415],
'x': [-0.81101389, -0.18321122],
'y': [1. , 0.43765626]
}
# 以下の通り可変長引数「**kwds」を利用して設定値分離でもOK
other_param2={
"node_color":"yellow", # 今回はyellowを設定
"with_labels":True
}
nx.draw(H, pos_h, **other_param2) # グラフの描画
nx.draw_networkx_edge_labels(H, pos_h, edge_labels=labels_w) # edgeのラベル(重み)を描画
# グラフに設定した「weight」の値をflow計算に使うエッジ容量(capacity)とみなして計算を実施
#flow_value, flow_dict = nx.maximum_flow(G, 4, 5, capacity="weight")
flow_value, flow_dict = nx.maximum_flow(H, "x", "y", capacity="weight")
print(flow_value)
print(flow_dict)【実行結果例】
23
{0: {2: 12},
1: {0: 0, 3: 11},
2: {1: 0, 'y': 19},
3: {2: 7, 'y': 4},
'x': {0: 12, 1: 11},
'y': {}}
いいなと思ったら応援しよう!
