
PythonやGNU Octaveを使ってデータをプロットしてみよう

またGoogleアプリが楽しそうな記事を拾ってきたので釣られてみた。データサイエンスの一連の流れ(データの読み込みから分析結果のグラフ出力まで)を、PythonやGNU Octaveでやってみようというものだ:
データ分析の一般的な流れを簡単な例題でやってみることで各言語の雰囲気を知ってもらうというところが主旨なので、コードの各行の意味とかちょっとした注意点なんかも丁寧に書いてあるようだ。
ここでは、記事の概要を示しつつ実際にやってみて、最後に全文拙訳を記載しようと思う。
記事の概要
新しい言語に馴染むには、自分がよく知っているタスクを実際にその言語でやってみるのが一番!というわけで、筆者は簡単なデータサイエンスの処理をPythonとGNU Octaveで実演することにしたようだ。
実際に2つの言語により、
1. データの読み込み(csvファイルから)
2. データを直線近似
3. 結果をプロット(グラフに出力)して画像化
という一連の作業をやっていく。
データはAnscombe's quartetと呼ばれるXY点群データを用いる。4セットのデータがありどれも一見まったく異なるデータだが、平均値や相関などが同じというとても不思議なデータらしい。(↓にリンク先Wikipediaページのサムネイル画像が見えると思うが、この4つ)
このうちの1セット(上記サムネイルでいうと左上のやつ)について、ファイルからデータ列を読み込んで、線形近似計算して、結果をプロットした画像を生成しよう、PythonとGNU Octaveで。というのが本記事の主なストーリーである。なお両言語によるサンプルコードを示すだけであり、あまり立ち入って比較する意図は無いようだ。(どちらの言語が優れている、とかいう話はそんなにしない)
Pythonによる方法(概要)
インストール
さすがにPythonのインストール手順からは説明されてない。最低でも以下のパッケージが必要であるとのこと:
・NumPy (アレイや行列を便利に扱えるように)
・SciPy (科学計算で使う)
・Matplotlib (結果プロット用)
Pythonでデータサイエンスやろうとする方はだいたい上記は既に使える状況かと思う。
私はついさっきPython 3.7.6を手元の環境にインストールしたばかりなので、ターミナルにて下記コマンドで各パッケージをインストールした:
pip3 install numpy
pip3 install scipy
pip3 install matplotlibたぶん最近だとAnacondaとか使うのが一般的なんだと思うけど、なんとなくmanuallyにやってみたいなぁと思ったので。
なお元記事では、下記コマンドだけで簡単にインストールできるよ!Fedoraならね!って書いてある。
sudo dnf install python3 python3-numpy python3-scipy python3-matplotlib
Pythonでデータサイエンスやる人、だいたいUbuntuなのではないかと思ったりする(偏見)が、海外だとFedoraはメジャーなんでしょうか。
コメント(とシェバン)
最初に、Pythonでのコメント行の与え方を説明。
そして、最初の1行めは以下のスペシャルコメントを書きましょうとしている:
#! /usr/bin/env python3環境がWindowsでも一応このシェバンは意味があるのかな?まぁ最悪でもコメント扱いで何も悪さはしないはずなので、迷ったら書いておきましょう。
必要ライブラリ
先ほどリストアップされていたライブラリをインポートする記述を書く:
import numpy as np
from scipy import stats
import matplotlib.pyplot as pltサブモジュールのみのインポートもできるよーとか、インポートの書き方も何通りかあるよー、という説明あり。
変数の定義
あとで使用するための変数を作る:
input_file_name = "anscombe.csv"
delimiter = "\t"
skip_header = 3
column_x = 0
column_y = 1
特に各変数の意味の説明は、この時点ではなし。
データの読み込み
numpyのgenfromtxt()関数により簡単にファイルからデータを読み込める:
data = np.genfromtxt(input_file_name, delimiter = delimiter, skip_header = skip_header)・・・ということであるが、読み込むファイル(anscombe.csv)が元記事では配布されていない。自分で作るしかない。
先ほどの変数内容から察するに、
・ファイル名はanscombe.csv
・デリミタはタブ
・ヘッダー行が3行
・今回使いたいデータは、0カラムと1カラムに入れておく
という点を満たしていれば良さそうだ。
以下にコードとして貼っておくのでコピペしたら使えるんじゃないかな多分。
anscombe.csv
I II III IV
X Y X Y X Y X Y
10.0 8.04 10.0 9.14 10.0 7.46 8.0 6.58
8.0 6.95 8.0 8.14 8.0 6.77 8.0 5.76
13.0 7.58 13.0 8.74 13.0 12.74 8.0 7.71
9.0 8.81 9.0 8.77 9.0 7.11 8.0 8.84
11.0 8.33 11.0 9.26 11.0 7.81 8.0 8.47
14.0 9.96 14.0 8.10 14.0 8.84 8.0 7.04
6.0 7.24 6.0 6.13 6.0 6.08 8.0 5.25
4.0 4.26 4.0 3.10 4.0 5.39 19.0 12.50
12.0 10.84 12.0 9.13 12.0 8.15 8.0 5.56
7.0 4.82 7.0 7.26 7.0 6.42 8.0 7.91
5.0 5.68 5.0 4.74 5.0 5.73 8.0 6.89改めて見返したら、サンプルコードファイルと同じ場所で配布されているっぽい:
https://gitlab.com/cristiano.fontana/polyglot_fit/-/tree/master
無駄に頑張ってcsv作ったのにー。
ちょっと本筋からそれてしまったが、これで変数dataにAnscombe's quartetのデータすべてが入る。
ただ、今回使いたいのはこの中の1セットのみ(最初の2列)だけなので、ここだけを取り出して別変数に格納しておく:
x = data[:, column_x]
y = data[:, column_y]データのフィッティング
SciPyを使ってデータフィッティングを行う。linregress()関数により、傾き、切片、相関を得る:
slope, intercept, r_value, p_value, std_err = stats.linregress(x, y)
print("Slope: {:f}".format(slope))
print("Intercept: {:f}".format(intercept))
print("Correlation coefficient: {:f}".format(r_value))プロット
Matplotlibを用いて結果をプロットする。ただしMatplotlibでは点列データしかプロットできない、つまり関数式を直接与えてプロットすることはできない。したがって、フィッティングで得られた関数から点列を計算しないとプロットできない。
というわけで、linspace()関数を用いて、適当な等間隔のX点データをまず作る:
fit_x = np.linspace(x.min() - 1, x.max() + 1, 100)たぶん、Xデータの最小値-1からXデータの最大値+1の範囲で100等分したデータ列になるんじゃないかと。
続けて、生成したX点データを用いてフィッティングで得られた関数の計算をすることで、対応するY点データを作る:
fit_y = slope * fit_x + interceptプロットのため、まずはfigureオブジェクトを作る:
fig_width = 7 # inch
fig_height = fig_width / 16 * 9 # inch
fig_dpi = 100
fig = plt.figure(figsize = (fig_width, fig_height), dpi = fig_dpi)
作成したfigureオブジェクトを利用してaxesを定義する:
ax = fig.add_subplot(111)
ax.plot(fit_x, fit_y, label = "Fit", linestyle = '-')
ax.plot(x, y, label = "Data", marker = '.', linestyle = '')
ax.legend()
ax.set_xlim(min(x) - 1, max(x) + 1)
ax.set_ylim(min(y) - 1, max(y) + 1)
ax.set_xlabel('x')
ax.set_ylabel('y')プロットをPNG画像で保存するには、以下をコール:
fig.savefig('fit_python.png')画像保存ではなく直接表示させるには、以下をコール:
plt.show()結果
コマンドラインへの出力は:

Matplotlibにより得られるプロット画像は:

思ったよりあっさりできて、一安心。
GNU Octaveによる方法(概要)
GNU Octaveってあまりメジャーじゃないと思う。ただ、MATLABとの高い互換性を掲げているフリーソフト(オープンソース)なので、必然的に(?)行列の扱いはやりやすい。上記のPythonと比較しながら見ていくと良いかと。
インストール
今回の例題にあたってはOctaveの基本パッケージのみでOK。元記事には例によってFedoraなら以下のコマンドでできるよ!って書いてある:
sudo dnf install octave公式のダウンロードページ見ると、Windowsのみインストーラが配布されてる。
Linuxは各ディストリビューション向けに有志がパッケージを用意してくれてるらしい。MacならWiki見てトライするか、Homebrewほかサードパーティ製パッケージマネージャを使うべし、とのこと。
とりあえず手元のLinuxMintを使うことにした。以下のコマンドでいけるようだ:
sudo apt install octaveOctaveがインストールできたら、以下のコマンドでGNU OctaveのGUIが起動する:
octaveCUIを使いたい場合は以下の様にオプション指定すべし。
octave --no-gui変数の定義
Pythonと同様に、まずは変数を定義する:
input_file_name = "anscombe.csv";
delimiter = "\t";
skip_header = 3;
column_x = 1;
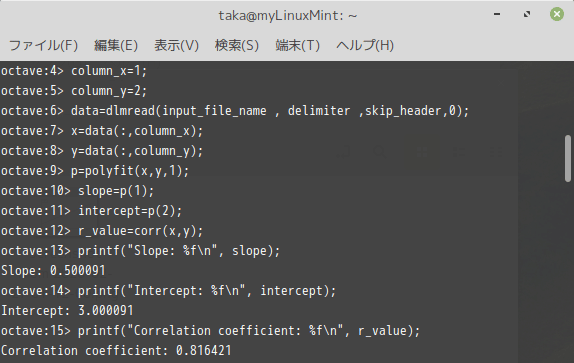
column_y = 2;データの読み込み
dlmread()関数でファイルからデータを読み込み、今回使用する列データのみを別の変数に格納する:
data = dlmread(input_file_name, delimiter, skip_header, 0);
x = data(:, column_x);
y = data(:, column_y);データのフィッティング
polyfit()関数で線形関数近似結果(勾配、切片)を得る:
p = polyfit(x, y, 1);
slope = p(1);
intercept = p(2);相関を得るためcorr()を使う:
r_value = corr(x, y);得られた結果を画面出力するため、printf()関数を用いる:
printf("Slope: %f\n", slope);
printf("Intercept: %f\n", intercept);
printf("Correlation coefficient: %f\n", r_value);プロット
Matplotlibと同じ様に、近似結果用のデータセットを準備する:
fit_x = linspace(min(x) - 1, max(x) + 1, 100);
fit_y = slope * fit_x + intercept;
そしてfigureオブジェクトを作り、axesオブジェクトを与える:
fig_width = 7; % inch
fig_height = fig_width / 16 * 9; % inch
fig_dpi = 100;
fig = figure("units", "inches",
"position", [1, 1, fig_width, fig_height]);
ax = axes("parent", fig);
set(ax, "fontsize", 14);
set(ax, "linewidth", 2);
また、以下の設定も与えておく:
xlim(ax, [min(x) - 1, max(x) + 1]);
ylim(ax, [min(y) - 1, max(y) + 1]);
xlabel(ax, 'x');
ylabel(ax, 'y');
以下のコマンドで、実際にプロットを追加する:
hold(ax, "on");
plot(ax, fit_x, fit_y,
"marker", "none",
"linestyle", "-",
"linewidth", 2);
plot(ax, x, y,
"marker", ".",
"markersize", 20,
"linestyle", "none");
hold(ax, "off");
さらに凡例を追加する:
lg = legend(ax, "Fit", "Data");
set(lg, "location", "northwest");
グラフを画像として保存しよう:
image_size = sprintf("-S%f,%f", fig_width * fig_dpi, fig_height * fig_dpi);
image_resolution = sprintf("-r%f,%f", fig_dpi);
print(fig, 'fit_octave.png',
'-dpng',
image_size,
image_resolution);結果
コマンドラインへの出力は:
本来はmファイルにでも記述してスクリプト実行すべきだったのだけど、手抜きですべてインタラクティブでやってしまったので見づらいですね。失敗。
プロット画像は:

当たり前だけど、Pythonの場合と同じ結果が得られた。
ところで画像生成のコマンド(最後のprint()関数)で多数Warningが出たのだけどこれはスルーでいいのかしら。PNG画像は無事に生成されたが・・・。
所感
どちらも一長一短あり、あるいはどっちもイマイチなところあり、どっちが良いとは一概には言いにくいところ。
行列の扱いはOctaveが非常にやりやすいと思う。GUIも利用できて変数の一覧とかデータサイズ(行列なら行数・列数とか)もぱっと見でわかるのでデバッグもしやすい。MATLAB互換があるので、Googleで "MATLAB 線形補間" とか検索してヒットするMATLABリファレンスの内容がだいたい使える(基本機能の関数であれば)。ただ、ユーザー数がたぶん(Pythonよりは)少ないので困った時に助けてもらえる人がいない。ネット上に情報も少ない。
Pythonは、今回の様なメジャーなライブラリであればユーザーも情報もそこそこ多いんじゃないかと思う。
以下、全文拙訳
ここまでの内容で、基本的に原文全体の内容を把握できるようにしているが、細かい説明(といってもそこまで多くない)を見たい方は原文をどうぞ。英語読むのめんどくさい方は以下の拙訳でよろしければご参照ください。
ここから先は
¥ 100
Amazonギフトカード5,000円分が当たる