
「数値シミュレーションで読み解く統計のしくみ」をPythonで写経 ~ 第5章5.5「反復測定分散分析のシミュレーション」

第5章「統計的検定の論理とエラー確率のコントロール」
書籍の著者 小杉考司 先生、紀ノ定保礼 先生、清水裕士 先生
この記事は、テキスト「数値シミュレーションで読み解く統計のしくみ」第5章「統計的検定の論理とエラー確率のコントロール」の5.5節「反復測定分散分析のシミュレーション」の Python写経活動 を取り扱います。
今回は反復測定分散分析のシミュレーションです。
R の基本的なプログラム記法はざっくり Python の記法と近いです。
コードの文字の細部をなぞって、R と Python の両方に接近してみましょう!
ではテキストを開いてシミュレーションの旅に出発です🚀
はじめに
テキスト「数値シミュレーションで読み解く統計のしくみ」のご紹介
このシリーズは書籍「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」(技術評論社、「テキスト」と呼びます)の Python写経です。
テキストは、2023年9月に発売され、副題「Rでためしてわかる心理統計」のとおり、統計処理に定評のある R の具体的なコードを用いて、心理統計の理解に役立つ数値シミュレーションを実践する素晴らしい書籍です。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「数値シミュレーションで読み解く統計のしくみ〜Rでためしてわかる心理統計」初版第1刷、著者 小杉考司・紀ノ定保礼・清水裕士、技術評論社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
5.5 反復測定分散分析のシミュレーション
テキスト5.4節冒頭の分散分析の概説を引用いたします。
・分散分析は3群以上の平均値の差を同時に検定する手法
・データに対応がある場合の分散分析を参加者間計画と呼ぶ
・データに対応がない場合の分散分析を参加者内計画と呼ぶ
反復測定分散分析は一要因参加者内計画の分散分析です。

この記事は Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
概ね確率分布の特性値算出には scipy.stats を用い、乱数生成には numpy.random.generator を用いるようにしています。
主に利用するライブラリをインポートします。
### インポート
# 数値計算
import numpy as np
# データフレーム
import pandas as pd
# 確率・統計
import scipy.stats as stats
import statsmodels.api as sm # 分散分析関連
import statsmodels.formula.api as smf # 分散分析関連
import pingouin as pg # 統計便利ツール
# 描画
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = 'Meiryo'以前の記事でも使った$${p}$$値のヒストグラムを描画する関数を定義します。
### p値のヒストグラム描画関数の定義
def plot_hist_pvalue(pvalue, bins=20):
# 描画領域の設定
plt.figure(figsize=(6, 3))
# ヒストグラムの描画
plt.hist(pvalue, bins=bins, ec='white', alpha=0.7)
# x軸ラベル、y軸ラベル、タイトルの設定
plt.xlabel('p value')
plt.ylabel('Frequency')
plt.title('Histogram of pvalue')
plt.show()
5.5.1 反復測定データの生成
テキストに従って複合対称性の仮定を満たすデータを生成します。
複合対称性の仮定は「すべての群の分散が等しく、測定間の相関も等しい」です。
また、次項以降では球面性の仮定を検討します。
球面性の仮定は「すべての群間の差の分散が等しい」です。
■ 複合対称性の仮定を満たすデータの生成
すべての群の分散に$${2^2}$$、相関に$${0.5}$$をそれぞれ設定して、多変量正規分布乱数を生成します。
最初に多変量正規分布のパラメータの1つ、分散共分散行列を作成します。
### 212ページ 反復測定データの生成1 設定、母分散共分散行列の作成
# データ生成の設定
m = 4 # 測定回数
n = 20 # サンプルサイズ
# 1つだけ差が大きい平均値を設定
mu = [6, 5, 5, 5]
# すべての群で等分散を仮定
sigma = [2, 2, 2, 2]
# すべての反復測定間の相関も等しいことを仮定
rho = 0.5
# 要因計画
x = np.repeat(a=[1, 2, 3, 4], repeats=n) # factor型ではない
# 参加者ID
id = np.tile(A=range(1, n+1), reps=m) # factor型ではない
# 母分散共分散行列の作成
sigma_mat = np.zeros((m, m))
for i in range(m):
# 対角以外の成分:共分散
for j in range(m):
if i > j:
sigma_mat[i, j] = rho * sigma[i] * sigma[j]
sigma_mat[j, i] = sigma_mat[i, j]
# 対角成分:分散
sigma_mat[i, i] = sigma[i]**2
# 母分散共分散行列の表示
sigma_mat【実行結果】
全ての測定間の共分散が等しく$${2}$$になりました。

次に多変量正規分布乱数を生成します。
テキストと異なる値になることにご留意ください。
### 213ページ 反復測定データの生成2 多変量正規分布乱数の生成
# データ生成
rng = np.random.default_rng(seed=1234)
Y = rng.multivariate_normal(size=n, mean=mu, cov=sigma_mat)
Y[:6, :]【実行結果】
冒頭の6行を表示しました。

続いて$${Y}$$を1つのベクトルに並び替えます。
### 214ページ 反復測定データの生成3 Yを1つのベクトルに並び替える
Y_vec = Y.flatten(order='F')【実行結果】なし
statsmodels で扱いやすくする目的で、$${x, id, Y}$$を1つのデータフレームにまとめます。
### データフレーム化 xとidをカテゴリ型に変換
df = pd.DataFrame({'x': pd.Categorical(x),
'id': pd.Categorical(id),
'Y_vec': Y_vec})
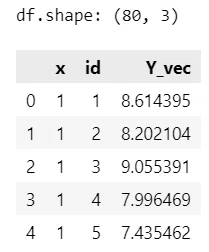
print('df.shape:', df.shape)
display(df.head())【実行結果】
■ 生成したデータの分散分析を実行
statsmodels と pingouin で分散分析をやってみます。
生成したデータはテキストと異なるので、果たして、分散分析の結果が適切なのかどうか、自信は無いです・・・
### 214ページ 分散分析の実行
result_lm = smf.ols(formula='Y_vec ~ x + id', data=df).fit()
result_anova = sm.stats.anova_lm(result_lm, typ=2)
result_anova【実行結果】

$${F}$$値と$${p}$$値を取り出します。
### 214ページ F値の算出
result_anova.loc['x', 'F']【実行結果】
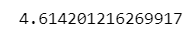
### 214ページ p値の算出
result_anova.loc['x', 'PR(>F)']【実行結果】

■ 別解 pingouin の rm_anova を使用
### 別解 pingouinの反復測定分散分析rm_anovaを使用
pg.rm_anova(dv='Y_vec', within='x', subject='id', data=df, detailed=True)【実行結果】

5.5.2 球面性の仮定
球面性の仮定が満たされないときにタイプⅠエラー確率がどのように変化するかをシミュレーションで確認します。
■ 自己相関があるデータの反復測定分散分析のタイプⅠエラー確率シミュレーション
時期が遠くなると相関が自己相関の累乗になる1次自己相関を仮定します。
隣の相関$${r=\tau}$$、2つ離れたときの相関$${r=\tau^2}$$となるそうです。
最初に分散共分散行列の算出です。
### 215ページ 自己相関ありデータのシミュレーション1 設定等
## 設定と準備
m = 4 # 測定回数
n = 20 # サンプルサイズ
mu = [5, 5, 5, 5] # 群ごとの母平均
sigma = [2, 2, 2, 2] # 群ごとの母標準偏差
rho = 0.5 # 相関係数
tau = 0.3 # 自己相関
# 要因計画
x = np.repeat(a=[1, 2, 3, 4], repeats=n) # factor型ではない
# 参加者ID
id = np.tile(A=range(1, n+1), reps=m) # factor型ではない
# 母分散共分散行列の作成
sigma_mat = np.zeros((m, m))
index = 0
for i in range(m):
# 対角以外の成分:共分散
for j in range(m):
if i > j:
index = index + 1
sigma_mat[i, j] = (rho + tau**(i - j)) * sigma[i] * sigma[j]
sigma_mat[j, i] = sigma_mat[i, j]
# 対角成分:分散
sigma_mat[i, i] = sigma[i]**2
# 母分散共分散行列の表示
sigma_mat【実行結果】
離れているデータほど共分散の値が小さくなっています。

続いて反復測定分散分析のシミュレーションです。
前のコードで設定した群ごとの母平均と母標準偏差を用いて正規分布乱数を生成します。
有意水準は$${5\%}$$で 2000 個の$${p}$$値を求めます。
### 216ページ 自己相関ありデータのシミュレーション2 データ作成、シミュレーション
## 設定と準備
iter = 2000 # シミュレーション回数
alpha = 0.05 # 有意水準
pvalue = np.zeros(iter)
## シミュレーション
rng = np.random.default_rng(seed=2)
for i in range(iter):
# Yの多変量正規分布乱数の生成して平坦化
Y = rng.multivariate_normal(size=n, mean=mu, cov=sigma_mat)
Y_vec = Y.flatten(order='F')
# Y_vec, x, idをデータフレーム化
df = df = pd.DataFrame({'x': pd.Categorical(x),
'id': pd.Categorical(id),
'Y_vec': Y_vec})
# 回帰および分散分析の実行
result_lm = smf.ols(formula='Y_vec ~ x + id', data=df).fit()
result_anova = sm.stats.anova_lm(result_lm, typ=2)
# p値の取り出し
pvalue[i] = result_anova.loc['x', 'PR(>F)']【実行結果】なし
$${p}$$値のヒストグラムを描画します。
### 217ページ 自己相関ありデータのシミュレーション3 p値のヒストグラムの描画 図5.13
# 確率が低いところ&高いところの歪みが大きい
plot_hist_pvalue(pvalue)【実行結果】
確率が低いところと高いところに歪みがあります。

タイプⅠエラー確率を算出します。
### 217ページ 自己相関ありデータのシミュレーション4 有意になった割合
# 有意水準α=0.05を超えている
(pvalue < alpha).mean()【実行結果】
有意水準$${5\%}$$を超えました。
テキストによると「自己相関があるにもかかわらず、それを仮定しない反復測定分散分析を実行するのは危険である」としています。

5.5.3 自由度補正による球面性仮定から逸脱を修正
球面性の仮定の逸脱に対する補正方法は、$${F}$$分布の自由度を調整して$${p}$$値の分布を補正する方法だそうです。
テキストによると「自由度補正は、$${\varepsilon}$$と呼ばれる量を推定し、この値を効果と誤差の両方の自由度に乗算」するとのこと。
また$${varepsilon}$$は$${0}$$から$${1}$$の範囲の値をとります。
以下の3つの方法で$${\varepsilon}$$を計算する関数を定義します。
・Greenhouse & Geisserの方法(GGの方法)
・Huynh & Feldtの方法(HFの方法)
・Chi & Mullerの方法(CMの方法)
### 218ページ 3つの補正方法を関数に定義する
# Greenhouse & Geisserの方法
def GG(Y):
p = Y.shape[1]
sigma_mat = np.cov(Y.T) # 分散共分散行列: Yの転置行列のcovを算出
sig1 = np.diag(sigma_mat).mean() # 対角成分の平均
sig2 = sigma_mat.mean() # 全平均
sig3 = (sigma_mat**2).sum() # 二乗和
temp = sigma_mat.mean(axis=1) # 行平均
sig4 = (temp**2).sum() # 行平均の二乗和
sig5 = sig2**2 # 全平均の二乗
gg = p**2 * (sig1 - sig2)**2 / ((p - 1) * (sig3 - 2*p*sig4 + p**2*sig5))
return gg
# Huynh & Feldtの方法
def HF(Y):
d = Y.shape[1] - 1 # Yの列数-1
n = Y.shape[0] # Yの行数
gg = GG(Y) # GGの補正についての関数をここで使っている
hf = min(1, (n * d * gg - 2) / (d * (n - 1 - d * gg)))
return(hf)
# Chi & Mullerの方法
def CM(Y):
hf = HF(Y) # HFの補正についての関数をここで使っている
temp = Y.shape[0] - 1
temp = (temp - 1) + temp * (temp - 1) / 2
cm = hf * (temp - 2) * (temp - 4) / temp**2
return cm■ 1次自己相関があるデータの$${\varepsilon}$$を計算
先ほど作成した1次自己相関があるデータに3つの関数を適用して$${\varepsilon}$$を計算します。
### 219ページ Greenhouse & Geisserの補正値
# 多変量正規分布乱数の作成
rng = np.random.default_rng(seed=24)
Y = rng.multivariate_normal(size=n, mean=mu, cov=sigma_mat)
# Greenhouse & Geisserの補正値
GG(Y)【実行結果】
GGの方法の$${\varepsilon}$$は約 0.74 です。

### 219ページ Huynh & Feldtの補正値
HF(Y)【実行結果】
HFの方法の$${\varepsilon}$$は約 0.84 です。

### 219ページ Chi & Mullerの補正値
CM(Y)【実行結果】
CMの方法の$${\varepsilon}$$は約 0.81 です。

テキストは「$${\varepsilon}$$が小さいほど、$${F}$$分布の自由度を小さくして$${p}$$値が大きくなるように補正する」ので、3つの方法の中で値が最も小さい「GGの方法が保守的な補正」と解説しています。
■ 3つの方法の$${\varepsilon}$$で$${F}$$分布の自由度を補正してタイプⅠエラー確率をシミュレーション
2000 回のシミュレーションで$${p}$$値を算出してヒストグラムを描画します。
最初にデータ生成~$${F}$$値算出~$${\varepsilon}$$算出を行います。
### 220ページ タイプⅠエラー確率のシミュレーション
# HFのεをそれぞれの自由度と乗算してF分布を補正
## 設定と準備
iter = 2000 # シミュレーション回数
alpha = 0.05 # 有意水準
# 結果を格納するオブジェクト
Fvalue = np.zeros(iter)
e_GG = np.zeros(iter)
e_HF = np.zeros(iter)
e_CM = np.zeros(iter)
## シミュレーション
rng = np.random.default_rng(seed=20)
for i in range(iter):
# 多変量正規分布乱数の生成と平坦化
Y = rng.multivariate_normal(size=n, mean=mu, cov=sigma_mat)
Y_vec = Y.flatten(order='F')
# Y_vec, x, idをデータフレーム化
df = df = pd.DataFrame({'x': pd.Categorical(x),
'id': pd.Categorical(id),
'Y_vec': Y_vec})
# 回帰および分散分析の実行
result_lm = smf.ols(formula='Y_vec ~ x + id', data=df).fit()
result_anova = sm.stats.anova_lm(result_lm, typ=2)
# F値の取り出し
Fvalue[i] = result_anova.loc['x', 'F']
# 補正値の算出
e_GG[i] = GG(Y)
e_HF[i] = HF(Y)
e_CM[i] = CM(Y)【実行結果】なし
$${p}$$値のヒストグラムを描画して、有意になった割合を計算します。
① 補正しないケース
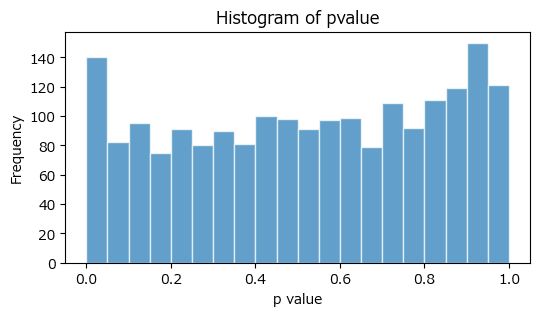
### 220ページ 補正しない場合 図5.14
pvalue = stats.f.sf(x=Fvalue, dfn=m-1, dfd=m*(n-1))
## 結果
# p値の分布
plot_hist_pvalue(pvalue)【実行結果】
### 221ページ 有意になった割合
(pvalue < alpha).mean()【実行結果】

② GGの方法で補正するケース
### 221ページ GGによる補正 図5.17
pvalue = stats.f.sf(x=Fvalue,
dfn=(m - 1) * e_GG,
dfd=m * (n - 1) * e_GG)
## 結果
# p値の分布
plot_hist_pvalue(pvalue)【実行結果】

### 221ページ 有意になった割合
(pvalue < alpha).mean()【実行結果】

③ HFの方法で補正するケース
### 222ページ HFによる補正 図5.18
pvalue = stats.f.sf(x=Fvalue,
dfn=(m - 1) * e_HF,
dfd=m * (n - 1) * e_HF)
## 結果
# p値の分布
plot_hist_pvalue(pvalue)【実行結果】

### 222ページ 有意になった割合
(pvalue < alpha).mean()【実行結果】

④ CMの方法で補正するケース
### 222ページ CMによる補正 223ページ図5.19
pvalue = stats.f.sf(x=Fvalue,
dfn=(m - 1) * e_CM,
dfd=m * (n - 1) * e_CM)
## 結果
# p値の分布
plot_hist_pvalue(pvalue)【実行結果】

### 223ページ 有意になった割合
(pvalue < alpha).mean()【実行結果】
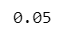
テキストの分析にならって・・・
・3つの方法はタイプⅠエラー確率をうまく補正できています。
・ただし、GGの方法は$${p}$$値の大きいところを小さく歪ませています。
5.6 演習問題
5.6.1 演習問題1
母標準偏差が異なる場合の3群の分散分析のタイプⅠエラー確率をシミュレーションします。
あわせて、各群のサイズの変化によるタイプⅠエラー確率を変化を確認します。
### 5.6.1 演習問題1
# 母標準偏差が異なる場合(σ=1, 5, 10)の3群の分散分析でタイプⅠエラー確率を
# シミュレーション
# また、群ごとのサイズが変化したときのタイプⅠエラー確率の変化を確認
## 設定と準備
alpha = 0.05 # 有意水準
k = 3 # 群の数
mu = 5 # 母平均(各群同じ値)
sigma = [1, 5, 10] # 群ごとの母標準偏差
iter = 1000 # シミュレーション回数
# サンプルサイズパターンの作成
n_fix = 10 # サンプルサイズの種
n_pattern = [1, 2, 4] # サンプルサイズの変化パターン
n_cases = [[n_fix * n_ptn**i for n_ptn in n_pattern] # サンプルサイズパターン
for i in range(len(n_pattern))]
# サンプルサイズのパターンごとにループ
for n in n_cases:
## 設定と準備2
# グループインデックスの作成(サンプルサイズによって変化)
x = np.hstack([np.repeat(a=1, repeats=n[0]), # factor型ではない
np.repeat(a=2, repeats=n[1]),
np.repeat(a=3, repeats=n[2])])
# p値を格納する変数の初期化
pvalue = np.zeros(iter)
# 乱数生成器・乱数シード
rng = np.random.default_rng(seed=1234)
## シミュレーション
for m in range(iter):
# 各グループのデータ(正規分布乱数)を生成してYに結合
Y1 = rng.normal(size=n[0], loc=mu, scale=sigma[0])
Y2 = rng.normal(size=n[1], loc=mu, scale=sigma[1])
Y3 = rng.normal(size=n[2], loc=mu, scale=sigma[2])
Y = np.hstack([Y1, Y2, Y3])
# F値を計算 statsmodelsのanova_onewayを使用
Fvalue = sm.stats.anova_oneway(
data=Y, groups=x, use_var='equal').statistic
# p値を計算
pvalue[m] = stats.f.sf(x=Fvalue, dfn=k - 1, dfd=sum(n) - k)
# タイプⅠエラー確率を計算
type1_error = (pvalue < alpha).mean()
# サンプルサイズとエラー確率を表示
print('Sample size of each group:', n)
print('Error ratio:', type1_error, '\n')【実行結果】
3番目の「各群のサイズが大きく異なるケース」ではタイプⅠエラー確率がほぼ0になりました。

今回の写経は以上です。
シリーズの記事
次の記事
前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。