
時系列分析入門【第3章 前編】単位根・系列相関・一般化最小二乗法GLSをPythonで実践する

この記事は、テキスト「RとStanではじめる 心理学のための時系列分析入門」の第3章「時系列の回帰分析」のRスクリプトをお借りして、Pythonで「実験的」に実装する様子を描いた統計ドキュメンタリーです。
取り扱いテーマは時系列回帰分析の基礎編です。
・単位根過程
・系列相関
・一般化最小二乗法
・時系列データの観察~対数変換
そろそろ、テキストのコード・分析結果の再現が難しくなってきました。
テキストの紹介、引用表記、シリーズまえがきは、このリンクの記事をご参照ください。
テキストで使用するデータは、R・Stan等のサンプルスクリプトで指定されています。
サンプルスクリプトは著者GitHubサイトからダウンロードして取得できます。
第3章 時系列の回帰分析
インポート
この章で用いるライブラリをインポートします。
### インポート
# 基本
import numpy as np
import pandas as pd
from scipy.linalg import toeplitz
# Rデータ読み取り
import rdata
# Rデータセット・一般化線形モデル・時系列分析
import statsmodels.api as sm
import statsmodels.formula.api as smf
from statsmodels.stats.stattools import durbin_watson
from statsmodels.tsa.seasonal import STL, seasonal_decompose
from statsmodels.tsa.stattools import adfuller
from statsmodels.tsa.deterministic import Fourier, DeterministicProcess
from statsmodels.graphics.tsaplots import plot_acf
# ARIMAモデル自動選択
import pmdarima as pm
# WEBアクセス
import requests
# グラフ描画
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')【補足】パッケージのインストール
利用環境に応じてパッケージをインストールしてください。
以下はインストールの参考コードです。
### インストール
## rdata
# anaconda
conda install -c conda-forge rdata
# pip
pip install rdata3.2.1 単位根過程
テキストによると単位根過程は「$${y_t}$$が非定常過程で、1階差分系列$${\Delta y_t = y_t - y_{t-1}}$$が定常過程に従う過程」です。
(弱)定常過程について、テキストの説明文・式を引用いたします。
【(弱)定常過程】
・平均$${\mu}$$が一定
$${E[y_t]=\mu}$$
・分散$${\sigma^2}$$が一定
$${V[y_t]=\sigma^2}$$
・自己共分散$${\gamma}$$が$${t}$$に依存せず、ラグ$${h}$$によってのみ定まる
$${Cov[y_t, y_{t+h}]=\gamma |h|}$$
ARMAモデルなどの時系列分析手法はデータが定常過程であることを前提にしており、単位根過程かどうかの確認が大切になるようです。
① ランダムウォークとホワイトノイズ
ランダムウォークは単位根過程であり、ランダムウォークの1階階差はホワイトノイズです。
【ランダムウォークの例】
$${y_t = y_{t-1} + \varepsilon_t, \quad \varepsilon_t \sim \text{Normal(0, 1)}}$$
$${\Delta y_t = \varepsilon_t, \quad \varepsilon_t \sim \text{Normal(0, 1)}}$$
ランダムウォークとランダムウォークの1階階差をプロットします。
テキストの図3.2に相当します。
なお、テキストの乱数生成と一致しないため、グラフも一致しません。
### ランダムウォークと1階階差
# 初期値設定
np.random.seed(123)
# ランダムウォークデータの作成
x = np.cumsum(np.random.randn(100))
# 1階階差データの作成
dy = np.diff(x, n=1)
# 描画 ※図3.2に相当
fig = plt.figure(figsize=(8, 3))
# ランダムウォークの描画
ax1 = fig.add_subplot(121, xlabel='Time', ylabel='y', title='ランダムウォーク')
ax1.plot(x)
# 1階階差の描画
ax2 = fig.add_subplot(122, xlabel='Time', ylabel='dy', title='ホワイトノイズ')
ax2.plot(dy)
plt.tight_layout()
plt.show()【実行結果】

② 見せかけの回帰
2つのランダムウォークを回帰分析すると、ただの乱数にもかかわらず、ほぼ有意な回帰となるそうです。
statsmodelsのolsで最小二乗法による回帰分析を行います。
なお、テキストの乱数生成と一致しないため、回帰分析の結果も一致しません。
### 見せかけの回帰
# 初期値設定
np.random.seed(1)
# ランダムウォークデータの作成
x = np.cumsum(np.random.randn(100)) # ランダムウォーク
y = np.cumsum(np.random.randn(100)) # ランダムウォーク
data = pd.DataFrame({'x': x, 'y': y}) # データフレームに格納
# 最小二乗法による回帰 statsmodelsのformula API
result = smf.ols(formula='y ~ x', data=data).fit()
print(result.summary())【実行結果】
変数 x の回帰係数(coef)のp値(P>|t|)は0.000になりました。
有意水準を5%とすると、p値が0.05を下回り、回帰係数が有意であるかのように見えます。

3.2.2 単位根過程の検定
拡張ディッキー-フラー検定(ADF検定)で単位根過程かどうかの検定を行います。
帰無仮説は「単位根を持つ」です。
① ランダムウォークの単位根検定
ランダムウォークの単位根検定を行います。
statsmodelsのadfullerを利用します。
このコード例ではADF検定用の関数 adf_test を定義しています。
なお、テキストの乱数生成と一致しないため、検定の結果も一致しません。
### ADF検定
# 初期値設定
np.random.seed(1234)
# ランダムウォークする時系列データの作成
y = np.cumsum(np.random.randn(200))
# ADF検定関数の定義
def adf_test(x, regression='ct', maxlag=5, autolag='AIC'):
result = adfuller(x=x, # テスト対象データ
regression=regression, # 定数項とトレンド項を含めるかどうか
maxlag=maxlag, # ラグの最大次数
autolag=autolag, # ラグ次数の選択規準
)
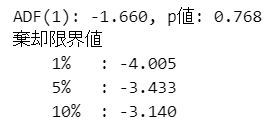
print(f'ADF({result[2]}): {result[0]:.3f}, p値: {result[1]:.3f}')
print('棄却限界値')
for k, v in result[4].items():
print(f' {k:5s}: {v:.3f}')
return result
# ADF検定 帰無仮説「単位根を持つ」
result = adf_test(x=y, # テスト対象データ
regression='ct', # 定数項とトレンド項を含める
maxlag=5, # ラグの最大次数は5
autolag='AIC' # ラグ次数はAICで選択
)【実行結果】
ラグ次数には1が選択され、p値は0.768です。
有意水準5%のとき、帰無仮説は棄却されず、単位根過程を思われます。
② ランダムウォークの1階階差系列の単位根検定
上の変数 y の1階階差についてADF検定を実施します。
1階階差は numpy の diff で求めています。
なお、テキストの乱数生成と一致しないため、検定の結果も一致しません。
### ADF検定:1階階差系列 帰無仮説「単位根を持つ」
result = adf_test(x=np.diff(y, n=1), # テスト対象データ:yの1階差分
regression='ct', # 定数項とトレンド項を含める
maxlag=5, # ラグの最大次数は5
autolag='AIC' # ラグ次数はAICで選択
)【実行結果】
p値は0.000となり、有意水準5%のとき、帰無仮説「単位根を持つ」は棄却されます。

何次まで階差をとればいいかを自動算出するには、pmdarimaのndiffsを利用します。
### 階差の次数の自動計算
pm.arima.ndiffs(y)【実行結果】
次数は1です。

3.3.2 ダービン-ワトソン検定
例えば回帰式$${y_t = \beta_0 + \beta_1 x_t + u_t}$$の残差$${u_t}$$について、自己相関があるとき、系列相関と呼びます。
残差が iid であること(互いに独立で同一の分布に従うこと)を前提とする統計的手法が多いため、残差に系列相関が無いこと(=iidである)の確認が大切だそうです。
残差に系列相関があるかどうかを検定する代表的な方法が、ダービン-ワトソン検定。
また、系列相関の有無を検討する指標がダービン-ワトソン比($${DW}$$)です。
$${DW}$$は0から4の範囲の値となり、2のときに系列相関なし、0に近いと正の系列相関、4に近いと負の系列相関が疑われるようです。
① 最小二乗法(OLS)によるAR(1)過程の回帰分析
自己相関係数$${\phi=0.9}$$のAR(1)過程に相当する乱数を生成して、statsmodelsのolsを用いた回帰分析を実行します。
ダービン-ワトソン検定を実行できるpythonのパッケージ・ライブラリを見つけられなかったので、このコード例ではダービン-ワトソン比のみを求めています。
コードの特徴は次のとおりです。
AR(1)過程の乱数生成を関数 ar1_sim で定義しました。
後の項でも再利用します。statsmodelのformula APIを利用して、'y ~ x'のような回帰式の記述をしています。
ダービン-ワトソン比はolsの結果に記載されています。
ダービン-ワトソン比だけを求める場合、statsmodelsのdurbin_watsonを利用します。ただし、残差データが必要になるため、olsの実行が必要そうです。
### ダービン・ワトソン検定 ではなく、ダービン・ワトソン比の算出
## AR(1)過程の乱数生成関数の定義
# 引数 phi:自己回帰係数φ、num:乱数の個数、sigma:誤差の標準偏差、seed:乱数シード
def ar1_sim(phi, num, sigma=1, seed=123):
np.random.seed(seed)
ar1_rand = np.zeros(num)
for i in range(1, num):
ar1_rand[i] = phi * ar1_rand[i-1] \
+ np.random.normal(loc=0, scale=sigma, size=1)
return ar1_rand
## AR(1)モデル・φ=0.9の乱数取得、データフレーム化
ar1_sm = pd.DataFrame({'AR1_sm': ar1_sim(phi=0.9, sigma=1, num=100)})
## 最小二乗法による回帰分析の実行
result = smf.ols(formula='AR1_sm ~ 1', data=ar1_sm).fit()
# ダービン・ワトソン比の計算 resultの残差residを利用
print(f'ダービン-ワトソン比: {durbin_watson(result.resid):.3f}')
# 回帰分析の結果表示
print(result.summary())【実行結果】
1行目がdurbin_watsonの結果の$${DW=0.208}$$です。
下の表はolsの結果であり、Durbin-Watson項目には$${DW=0.208}$$が掲載されています。
0に近いので、系列相関が疑われます。
なお、テキストの乱数生成と一致しないため、結果も一致しません。

② おまけ:AR(1)過程のプロット
上記の回帰分析に用いたAR(1)過程のデータをプロットします。
### おまけ:AR(1)過程のプロット
ar1_sm.plot(figsize=(8, 3), xlabel='Time', title='AR(1)過程', legend=False);【実行結果】

3.3.3 一般化最小二乗法
テキストでは、残差系列の相関構造を明示的に与えた上で回帰分析を行える一般化最小二乗法(GLS)に進みます。
Rのnlmeパッケージのgls()関数は、引数correlationでAR(1)過程に従う残差の分散共分散行列を「correlation=corAR1()」のように指定できます。
しかし、PythonのGLS関連モジュールについては、AR(1)過程に従う残差の分散共分散行列を簡単に指定できるものを見つけることができませんでした。
このコード例では、statsmodelsの公式サイトで例示されている分散共分散行列の算出方法を利用させていただきました。
ただ、この算出方法がテキストの「correlation=corAR1()」と同義かどうかは不明であり、GLSのコード例・実行結果がテキストと一致しないことを前提にしてご覧ください。
① 最小二乗法(OLS)
statsmodelsのolsを用いて通常の回帰分析(OLS)を実行します。
先程つくった ar1_sim関数を用いて、自己相関係数$${\phi=0.9}$$のAR(A)過程の乱数を生成します。
### 最小二乗法OLSによる回帰分析
## 初期値設定:データ個数
n = 50
## データの生成
# 説明変数x:時間
x = np.arange(n)
# 目的変数AR1_sm:AR(1)に従う時系列データ
AR1_sm = ar1_sim(phi=0.9, sigma=1, num=n, seed=777)
# データフレーム化
ar1_sm = pd.DataFrame({'x': x, 'AR1_sm': AR1_sm})
## 最小二乗法による回帰分析の実行
result_ols = smf.ols(formula='AR1_sm ~ x', data=ar1_sm).fit()
# ダービン・ワトソン比の計算 resultの残差residを利用
print(f'ダービン-ワトソン比: {durbin_watson(result_ols.resid):.3f}')
# 回帰分析の結果表示
print(result_ols.summary())【実行結果】
変数 x の回帰係数(coef)のp値(P>|t|)は0.000であり、回帰係数は有意に見えます。
ただし、ダービン-ワトソン比$${DW=0.460}$$は0に近いため、系列相関が疑われます。

乱数の折れ線グラフと残差の自己相関関数を描画します。
テキストの図3.3に相当します。
## 描画 ※図3.3に相当
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ar1_sm['AR1_sm'].plot(figsize=(8, 3), ax=ax[0], xlabel='Time', ylabel='AR1_sm',
title='AR(1)に従うランダムな時系列')
plot_acf(result_ols.resid, lags=20, bartlett_confint=False, auto_ylims=True,
ax=ax[1], title='OLS:残差の自己相関関数')
ax[1].set(xlabel='Lag', ylabel='ACF')
plt.tight_layout()
plt.show()【実行結果】
残差の自己相関関数は、ラグ1・2に有意な系列相関が見られます。

② 一般化最小二乗法(GLS)
statsmodelsのglsを用いて、一般化最小二乗法による回帰分析を実施します。
「パラメータsigma(分散共分散行列)の取得」では次のstatsmodels公式サイトのコードを利用させていただきました。
### 一般化最小二乗法GLSによる回帰分析
# 残差の分散共分散行列の指定方法がテキストと異なるため、結果が合致していない可能性が高い
## パラメータsigma(分散共分散行列)の取得
# ar1_smのOLS残差の1階階差系列をさらにOLS、最小二乗基準を最小化する線形係数ρを取得
ols_resid = smf.ols(formula='AR1_sm ~ x', data=ar1_sm).fit().resid
res_fit = sm.OLS(ols_resid[1:].values, ols_resid[:-1].values).fit()
rho = res_fit.params
# 分散共分散行列に変換
order = toeplitz(np.arange(len(ar1_sm))) # scipy.linalgのtoeplitz
sigma = rho**order
## 一般化最小二乗法による回帰分析の実行
result_gls = smf.gls(formula='AR1_sm ~ x', data=ar1_sm, sigma=sigma).fit()
# 回帰分析の結果表示
print(result_gls.summary())【実行結果】
変数 x の回帰係数のp値(p>|t|)は$${0.126}$$となり、有意水準5%で有意とは言えない値です。

テキストにならって、OLSとGLSの回帰直線をプロットします。
テキストの図3.4に相当します。
## 描画 ※図3.4に相当
plt.figure(figsize=(7, 3))
plt.plot(x, AR1_sm, 'o', markersize=3, color='black', label='観測値')
plt.plot(x, result_ols.fittedvalues, ls='--', color='steelblue', label='OLS')
plt.plot(x, result_gls.fittedvalues, ls='--', color='tomato', label='GLS')
plt.xlabel('$x$')
plt.ylabel('AR1_sm')
plt.legend()
plt.show()【実行結果】
OLSとGLSとで回帰直線の傾き(回帰係数)が異なることが分かりました。


【実践編】
ここからは、テキスト3.4節の新型コロナウイルス感染者数データを用いた「データの観察と変換」の一連の作業を実践します。
回帰分析に入る前の前処理を実体験できるので、とても参考になりました。
データの取得時期がテキストと異なることが原因と思われますが、テキストのデータ加工・分析結果と異なる結果になっていることを予めご了承下さいませ。
3.4.1 図示
Webサイトよりデータ取得して、利用部分を抽出します。
### データの観察と変換
# Webサイトのデータを参照してpandasのデータフレームに格納
url = r'https://github.com/RamiKrispin/coronavirus/blob/main/csv/' \
'coronavirus.csv?raw=true'
covid = pd.read_csv(url)
# 日本データの抽出
covid_ja = covid[(covid['type']=='confirmed')
& (covid['date']<='2021-09-01')
& (covid['country']=='Japan')].reset_index(drop=True)
covid_ja['date'] = pd.to_datetime(covid_ja['date'])
display(covid_ja)【実行結果】
2020年1月22日から2021年9月1日までの589行のデータを利用します。

日々の発生件数(cases)を折れ線グラフで描画します。
# 描画 ※図3.5に相当
plt.figure(figsize=(10, 3))
plt.plot(covid_ja['date'], covid_ja['cases'])
plt.xlabel('日付')
plt.ylabel('件数');【実行結果】
5つの波がどんどん大きくなる様子を確認できました。
波の大きさ(高さ)や分散(幅)が大きくなっています。
小刻みな上下には何か周期性のようなものを感じます。

3.4.2 対数変換
テキストによると、分析期間の間で分散が変化する場合、対数変換を行って分散の安定化をはかるそうです。
対数グラフで確認しましょう。
matplotlibの描画引数 yscale で 「log」を指定することで、対数変換後のグラフを描画できます。
### 対数変換 ※図3.6に相当
# 片対数グラフのプロット
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
# 日付そのままで描画
ax[0].plot(covid_ja['date'], covid_ja['cases'])
ax[0].set(xlabel='日付', ylabel='件数', yscale='log')
ax[0].tick_params(axis='x', labelrotation=30)
# 2020年2月10日以降のデータを描画
covid_ja_nn = covid_ja[covid_ja['date']>='2020-02-10'].reset_index(drop=True)
ax[1].plot(covid_ja_nn['date'], covid_ja_nn['cases'])
ax[1].set(xlabel='日付', ylabel='件数', yscale='log')
ax[1].tick_params(axis='x', labelrotation=30);【実行結果】
波の高さ・幅が似てきました。

3.4.3 単位根検定
2020年2月10日以降の感染者数を対数変換して、当該対数値が単位根過程かどうかをADF検定で確認します。
先に作成したADF検定関数 adf_test を用いています。
### 単位根検定 ※テキストの値と若干異なる
# casesを対数変換
covid_ja_nn['log_cases'] = np.log(covid_ja_nn['cases'])
# ADF検定 帰無仮説「単位根を持つ」
result = adf_test(x=covid_ja_nn['log_cases'], # テスト対象データ
regression='ct', # 定数項とトレンド項を含める
maxlag=5, # ラグの最大次数は5
autolag='AIC' # ラグ次数はAICで選択
)【実行結果】
p値が$${0.244}$$であり、単位根過程であることを棄却できないようです。

続いて、対数の1階階差の単位根検定を行います。
# 差分系列のADF検定 帰無仮説「単位根を持つ」 ※テキストの値と若干異なる
result = adf_test(x=covid_ja_nn['log_cases'].diff(1).dropna(), # diff:1階差分
regression='ct', # 定数項とトレンド項を含める
maxlag=5, # ラグの最大次数は5
autolag='AIC' # ラグ次数はAICで選択
)【実行結果】
p値が$${0.000}$$となり、単位根過程あることを棄却できるようになりました。
ここまでの分析から、対数変換後の感染者数の1階階差系列を時系列分析に用いるのがよい、と確認できました。

対数変換後の1階階差系列をプロットします。
テキストの図3.7に相当します。
### 対数変換後の感染者数の1階差分系列 ※図3.7に相当
# テキストの400あたりの大きな波が無い
plt.figure(figsize=(10, 3))
plt.plot(covid_ja_nn.index, covid_ja_nn['log_cases'].diff(1), lw=0.8)
plt.xlabel('Time')
plt.ylabel('diff(log cases)');【実行結果】
テキストの図に見られる時間400あたりの大きな波が、この図では見られません。なぜでしょう???

3.4.4 季節調整
折れ線グラフに見られた小刻みの波は、日曜・月曜に感染者数が少ない傾向を示しており、周期7日の季節成分が含まれていると想像されます。
季節成分を STL分解(LOESS)で分離してプロットします。
テキストの図3.8上に相当します。
### 季節調整 ※図3.8上に相当 テキストの季節成分のような一定振幅を再現できない
logcases_diff_stl = STL(covid_ja_nn['log_cases'].diff(1).dropna(),
period=7, robust=True).fit()
## 描画
fig, ax = plt.subplots(4, 1, figsize=(8, 8), sharex=True)
logcases_diff_stl.observed.plot(ax=ax[0], lw=0.8)
ax[0].set_ylabel('原系列')
logcases_diff_stl.seasonal.plot(ax=ax[1], lw=0.8)
ax[1].set_ylabel('季節変動')
logcases_diff_stl.trend.plot(ax=ax[2], lw=0.8)
ax[2].set_ylabel('トレンド変動')
logcases_diff_stl.resid.plot(ax=ax[3], lw=0.8)
ax[3].set_ylabel('不規則変動')
plt.suptitle('時系列の分解')
plt.tight_layout();【実行結果】
トレンド成分が滑らかです。
季節変動がテキストのように一定のリズムになっておりません、あしからず。
(時間軸の目盛りが異なっていたりします)

季節調整後のプロットです。
### 季節調整後のデータ ※図3.8下に相当 テキストの結果と異なる
ex_season = logcases_diff_stl.trend + logcases_diff_stl.resid
ex_season.plot(figsize=(9, 3), lw=0.8)
plt.xlabel('Time')
plt.ylabel('diff(log cases) ex-season');【実行結果】

このまま終了するのは寂しいので、移動平均法のseasonal_decomposeで分解します。
### 季節調整 seasonal_decompose(移動平均) ※図3.8上に相当
logcases_diff_sd = seasonal_decompose(covid_ja_nn['log_cases'].diff(1).dropna(),
model='additive', period=7,
two_sided=True)
## 描画
fig, ax = plt.subplots(4, 1, figsize=(8, 8), sharex=True)
logcases_diff_sd.observed.plot(ax=ax[0], lw=0.8)
ax[0].set_ylabel('原系列')
logcases_diff_sd.seasonal.plot(ax=ax[1], lw=0.8)
ax[1].set_ylabel('季節変動')
logcases_diff_sd.trend.plot(ax=ax[2], lw=0.8)
ax[2].set_ylabel('トレンド変動')
logcases_diff_sd.resid.plot(ax=ax[3], lw=0.8)
ax[3].set_ylabel('不規則変動')
plt.suptitle('時系列の分解')
plt.tight_layout();【実行結果】
きれいな季節変動の描画を得ました!
トレンド成分はかなりギザギザしています。

季節調整後のデータをプロットします。
### 季節調整後のデータ seasonal_decompose(移動平均) ※図3.8下に相当
ex_season = logcases_diff_sd.trend + logcases_diff_sd.resid
ex_season.plot(figsize=(9, 3), lw=0.8)
plt.xlabel('Time')
plt.ylabel('diff(log cases) ex-season');【実行結果】

第3章 後編へ続く
■次回の取り組みテーマ
・時系列単回帰分析(OLS回帰/GLS回帰、季節成分を考慮しない/する)
・ランダム切片モデル
・潜在成長曲線モデル
・中断時系列デザイン(線形回帰モデル、ポアソン回帰モデル)
次の記事
前の記事
目次
ブログの紹介
note で4つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
2.実験!たのしいベイズモデリングをPyMC Ver.5で
書籍「たのしいベイズモデリング」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learn と PyTorch の教科書です。
よかったらぜひ、お試しくださいませ。
4.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Python のコラムを不定期に綴っています。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
最後までお読みいただきまして、ありがとうございました。