
「Pythonではじめる異常検知入門」を寄り道写経 ~ 第8章「補足」Isolation Forestによる異常検知

第8章「補足」
書籍の著者 笛田薫 先生、江崎剛史 先生、李鍾賛 先生
この記事は、テキスト「Pythonではじめる異常検知入門」の第8章「補足」の 8-2 節「分岐ルールを作るアプローチ:Isolation Forest」の通称「寄り道写経」を取り扱います。
機械学習のアルゴリズムでおなじみのランダムフォレストのお友達「Isolation Forest」を用いた異常検知に取り組みます。
ではテキストを開いて異常検知の旅に出発です🚀

このシリーズは書籍「Pythonではじめる異常検知入門」(科学情報出版、「テキスト」と呼びます)の異常検知の理論・数式とPythonプログラムを参考にしながら、テキストにはプログラムの紹介が無いけれども気になったテーマ、または、テキストのプログラム以外の方法を試したいテーマを「実験的」にPythonコード化する寄り道写経ドキュメンタリーです。
はじめに
テキスト「Pythonではじめる異常検知入門」のご紹介
テキストは、2023年4月に発売された異常検知の入門書です。
数式展開あり、Python実装ありのテキストなのです。
Jupyter Notebook 形式のソースコードと csv 形式のデータは、書籍購入者限定特典として書籍掲載のURLからダウンロードできます。
引用表記
この記事は、出典に記載の書籍に掲載された文章及びコードを引用し、適宜、掲載文章とコードを改変して書いています。
【出典】
「Pythonではじめる異常検知入門-基礎から実践まで-」初版、著者 笛田薫/江崎剛史/李鍾賛、オーム社
記事中のイラストは、「かわいいフリー素材集いらすとや」さんのイラストをお借りしています。
ありがとうございます!
第8章 8-2 Isolation Forest
Jupyter Notebook 形式(拡張子 .ipynb)でPythonコードを書きます。
テキスト補足章の異常検知は、第7章のワインデータ & Isolation Forest です!
寄り道写経はテキストのコードに沿って進めたいと思います。

インポート
### インポート
# 数値・確率計算
import pandas as pd
import numpy as np
# 機械学習
from sklearn.datasets import load_wine
from sklearn.ensemble import IsolationForest
from sklearn.inspection import DecisionBoundaryDisplay
# 描画
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import seaborn as sns
plt.rcParams['font.family'] = 'Meiryo'
# ワーニング表示の抑制
import warnings
warnings.simplefilter('ignore')Google Colab をご利用の場合は「描画」箇所を以下のように差し替えてください。
!pip install japanize_matplotlib
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
import japanize_matplotlib
import seaborn as snsデータの読み込み
scikit-learn のデータセットに含まれる「wine」データセットを利用します。
UCI の機械学習リポジトリから取得することも可能です。
### データの読み込み
# scikit-learnのwineデータセットを取得
wine = load_wine()
# 説明変数をデータフレーム化
df = pd.DataFrame(wine.data, columns=wine.feature_names)
# 目的変数をデータフレーム化
target = pd.DataFrame(wine.target, columns=['class'])
# 説明変数データの表示
print('df.shape: ', df.shape)
display(df.head())【実行結果】
説明変数データは 13 説明変数、標本サイズ(行数)178です。

■ 利用する変数
この記事では2つの説明変数「magnesium」「color_intensity」を用いて異常検知に取り組みます!
### 異常検知に用いる2変数を選択
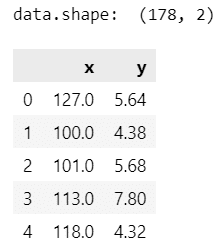
data = (df[['magnesium', 'color_intensity']].set_axis(['x', 'y'],axis=1))
print('data.shape: ', data.shape)
display(data.head())【実行結果】
x は magnesium、y は color_intensity です。
データ標準化は行いません。
データの可視化
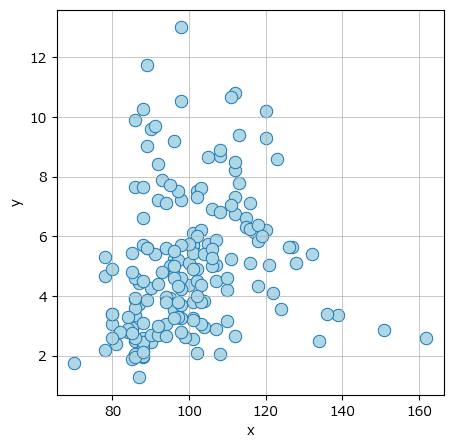
散布図を描画します。
seaborn の regplot で作画した回帰直線付きの散布図です。
テキスト図7-4に相当します。
### MagnesiumとColor_intensityの散布図の描画
plt.figure(figsize=(5, 5))
sns.scatterplot(data=data, x='x', y='y', s=80,
color='lightblue', ec='tab:blue')
plt.grid(lw=0.5);【実行結果】
データは「L字型」の形状に見えます。
Isolation Forest の学習
■ 学習の実行
Isolation Forest の学習を行います。
Isolation Forest のパラメータにはテキストと異なる値を設定しました。
引数 n_estimators は決定木の数、contamination はざっくり異常値の割合です。
### 2変数x,yでIsolation Forestによる異常度を算出
# Isolation Forest 分類器の設定
clf = IsolationForest(n_estimators=5, contamination=0.022, max_features=2,
random_state=123)
# 学習
clf.fit(data)
# 予測
pred = clf.predict(data) # -1: 異常値, 1: 正常値
# 決定境界からの距離を算出
dist = clf.decision_function(data)【実行結果】なし
学習データのうち、異常に分類されたデータの個数を確認します。
### 学習データのうち異常判定されるデータの個数
print('異常データの数: ', (pred == -1).sum())【実行結果】
178 データ点の中から 4 点が異常判定されるモデルのようです。
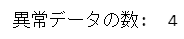

■ 閾値の評価
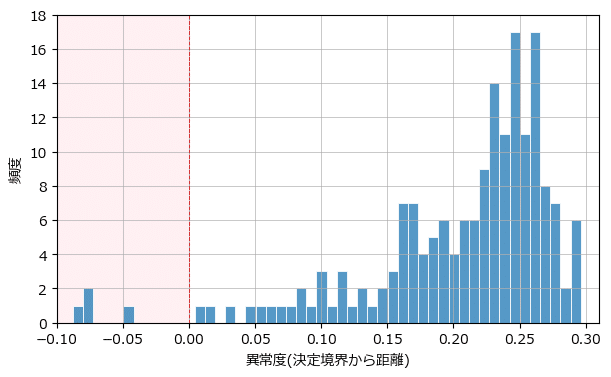
正常/異常の分布を確認します。
decision_function にて算出した「決定境界からの距離」をスコアに見立てています。
### 異常スコア(決定境界からの距離)ヒストグラムの描画処理
# ビンを0.01間隔で設定
bins = np.arange(-0.17, 0.26, 0.01)
# 描画領域の設定
fig, ax = plt.subplots(figsize=(7, 4))
# 閾値=0の垂直線の描画
ax.axvline(0, color='tab:red', ls='--', lw=0.7)
# 異常の領域(閾値未満)の塗りつぶし描画
ax.fill_between([-0.17, 0], 0, 18, color='lightpink', alpha=0.2)
# 異常スコアのヒストグラムの描画
sns.histplot(x=dist, bins=50, ec='white', ax=ax)
# 修飾
ax.set(xlabel='異常度(決定境界から距離)', ylabel='頻度', xlim=(-0.1, 0.31),
ylim=(0, 18))
ax.grid(lw=0.5);【実行結果】
薄赤色のゾーンが「異常」です。
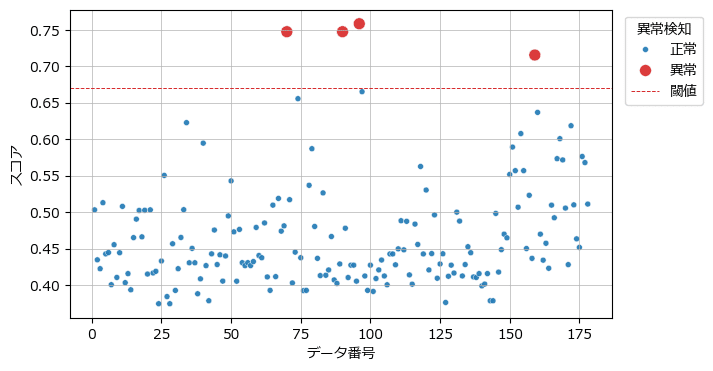
続いて異常度スコア score_samples を算出して、管理図ライクな図を描画してみましょう。
スコアは -1 を乗じて正負反転させています。
### 異常度スコア(スコア)による異常検知の可視化
## 描画用データの作成
# 異常度スコアの算出(算出値×-1)
score = clf.score_samples(data) * -1
# 異常度の閾値の取得(オフセット×-1)
thres = clf.offset_ * -1
# x軸の値の設定
xval = np.arange(1, len(score) + 1)
## 描画処理
# 描画領域の設定
fig, ax = plt.subplots(figsize=(7, 4))
# 正常データの散布図の描画
sns.scatterplot(x=xval, y=score, hue=pred*-1, size=pred*-1, alpha=0.9,
palette=['tab:blue', 'tab:red'], ax=ax)
# 閾値の水平線の描画
ax.axhline(thres, color='tab:red', lw=0.7, ls='--', label='閾値')
# 凡例
handles, labels = ax.get_legend_handles_labels()
ax.legend(handles=handles, labels=['正常', '異常', '閾値'], title='異常検知',
bbox_to_anchor=(1.18, 1))
# 修飾
ax.set(xlabel='データ番号', ylabel='スコア')
ax.grid(lw=0.5);【実行結果】
なかなかいい感じの閾値です!
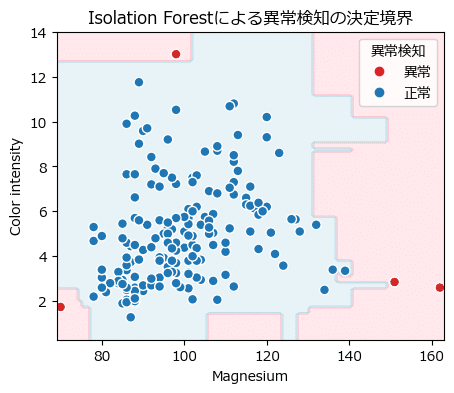
正常と異常を分割する「決定境界」を示した散布図を描画します。
scikit-learn の DecisionBoundaryDisplay で決定境界を描画します。
### 決定境界の描画
# 色の設定
cmap_bound = ListedColormap(['lightpink', 'lightblue', ])
cmap_point = ListedColormap(['tab:red', 'tab:blue'])
# 描画領域の設定
fig, ax = plt.subplots(figsize=(5, 4))
# 決定境界の描画
disp = DecisionBoundaryDisplay.from_estimator(
clf, data, response_method='predict', cmap=cmap_bound,
xlabel='Magnesium', ylabel='Color intensity', alpha=0.3, ax=ax)
# 散布図の描画
scatter = ax.scatter(data.x, data.y, c=pred, cmap=cmap_point, ec='white', s=50)
# 修飾
ax.set_title('Isolation Forestによる異常検知の決定境界')
# 凡例表示
handles, labels = scatter.legend_elements()
plt.legend(handles=handles, labels=['異常', '正常'], title='異常検知');【実行結果】
5つの決定木で推論する Isolation Forest の決定境界はカクカクしていますね!
決定木の数(引数 n_estimators )を変えて、決定境界の形状の変化を楽しみましょう。
テキスト図8-10に相当します。
### 図8-10 決定木の数による決定境界の変化の可視化
## 決定木の数の設定
n_estimators_list = [3, 5000]
## 色の設定
cmap_bound = ListedColormap(['lightpink', 'lightblue', ])
cmap_point = ListedColormap(['tab:red', 'tab:blue'])
## 描画
# 描画領域の設定
fig, ax = plt.subplots(1, 2, figsize=(10, 4))
# 2回、Isolation Forestの学習・予測と描画を繰り返し処理
for i, n_est in enumerate(n_estimators_list):
## Isolation Forestの学習と予測
# Isolation Forest分類器の設定
clf_sim = IsolationForest(n_estimators=n_est, contamination=0.022,
max_features=2, random_state=123)
# 学習
clf_sim.fit(data)
# 学習データの予測(異常検知)
pred_sim = clf_sim.predict(data)
## 描画処理
# 決定境界の描画
disp = DecisionBoundaryDisplay.from_estimator(
clf_sim, data, response_method='predict', cmap=cmap_bound,
xlabel='Magnesium', ylabel='Color intensity', alpha=0.3, ax=ax[i])
# 散布図の描画
scatter = ax[i].scatter(data.x, data.y, c=pred_sim, cmap=cmap_point,
ec='white', s=50)
# 修飾
ax[i].set_title(f'n_estimators={n_est}')
# 全体修飾
fig.suptitle('Isolation Forestによる異常検知の決定境界')
plt.legend(handles=handles, labels=['異常', '正常'], title='異常検知');【実行結果】
決定木の数(引数 n_estimators )が大きいと滑らかな境界になります!
異常データが変わっていないことには、少々驚いてます。

未知データの異常検知
未知データを作成して、異常検知してみましょう!
第7章②のときに使った未知データを使用します。
異常検知アルゴリズムが変わることで、異常データが変化するのでしょうか???
■ 未知データの作成
### 未知データの作成
data_new = np.array([[80, 7], [80, 5.5], [120, 2.5], [125, 2.5], [140, 10]])
print('未知データ:')
print(data_new)【実行結果】
5つのデータを作成しました。


■ 異常検知の実行
それでは!📯
未知データの異常検知を実行します!
学習済みの分類器「clf」を用います。
パラメータ値は「n_estimators=5, contamination=0.022」でした。
### 未知データの異常検知
# 学習済モデルclfによるクラス予測 1:正常値、-1:外れ値
pred_new = clf.predict(data_new)
print('正常・異常ラベル : ', pred_new)
# 決定境界からの距離の算出 負は外れ値
score_new = clf.decision_function(data_new)
print('決定境界からの距離: ', score_new)
## 異常度(スコア)の算出
score_samples_new = clf.score_samples(data_new)
print('スコア : ', score_samples_new)【実行結果】
5つのデータの正常・異常ラベル、決定境界からの距離、スコアです。
異常ラベル=-1が異常ですので、異常データはありません!


■ 異常検知結果の確認
決定境界を示した散布図で未知データがどの位置にあるか確認してみましょう。
### 決定境界の描画
# 予測ラベルの変更 正常:0、異常:1
pred01 = np.where(pred == -1, 1, 0)
pred_new01 = np.where(pred_new == -1, 1, 0)
# 色の設定
cmap_bound = ListedColormap(['lightpink', 'lightblue', ])
cmap_point = ListedColormap(['tab:blue', 'tab:red'])
# 描画領域の設定
fig, ax = plt.subplots(figsize=(5, 4))
# 決定境界の描画
disp = DecisionBoundaryDisplay.from_estimator(
clf, data, response_method='predict', cmap=cmap_bound,
xlabel='Magnesium', ylabel='Color intensity', alpha=0.3, ax=ax)
# 観測値の散布図の描画
scatter = ax.scatter(data.x, data.y, c=pred01, cmap=cmap_point, ec='white', s=50)
# 未知データの散布図の描画
scatter2 = ax.scatter(data_new[:, 0], data_new[:, 1], c=pred_new01,
cmap=cmap_point, ec='orange', s=200)
# 修飾
ax.set_title('Isolation Forestによる異常検知の決定境界')
# 凡例表示
handles, labels = scatter.legend_elements()
plt.legend(handles=handles, labels=['異常', '正常'], title='異常検知');【実行結果】
大きな青点が未知データです。
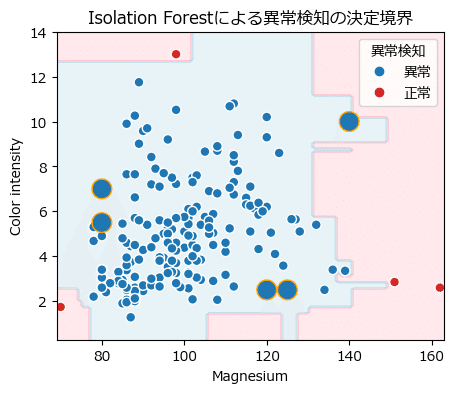
5つの未知データは青い正常の領域に位置しています!
下図の第7章②「One-Class SVM」では、赤点線の決定境界のもとで、1・4・5番目が異常判別されました。
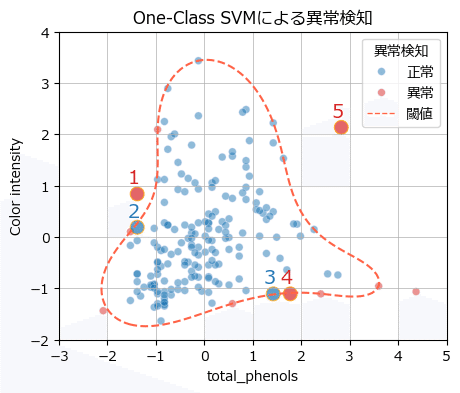
アルゴリズムによってさまざまな決定境界が構築されます。
データの特性や利用目的などに応じて、適切なアルゴリズムを選択する必要がありそうです。
第8章の寄り道写経は以上です。
テキストの第8章は最終章です。
寄り道写経も今回が最終号です。
ご清聴ありがとうございました。

シリーズの記事
次の記事

前の記事
目次
ブログの紹介
note で7つのシリーズ記事を書いています。
ぜひ覗いていってくださいね!
1.のんびり統計
統計検定2級の問題集を手がかりにして、確率・統計をざっくり掘り下げるブログです。
雑談感覚で大丈夫です。ぜひ覗いていってくださいね。
統計検定2級公式問題集CBT対応版に対応しています。
Python、EXCELのサンプルコードの配布もあります。
2.実験!たのしいベイズモデリング1&2をPyMC Ver.5で
書籍「たのしいベイズモデリング」・「たのしいベイズモデリング2」の心理学研究に用いられたベイズモデルを PyMC Ver.5で描いて分析します。
この書籍をはじめ、多くのベイズモデルは R言語+Stanで書かれています。
PyMCの可能性を探り出し、手軽にベイズモデリングを実践できるように努めます。
身近なテーマ、イメージしやすいテーマですので、ぜひぜひPyMCで動かして、一緒に楽しみましょう!
3.実験!岩波データサイエンス1のベイズモデリングをPyMC Ver.5で
書籍「実験!岩波データサイエンスvol.1」の4人のベイジアンによるベイズモデルを PyMC Ver.5で描いて分析します。
この書籍はベイズプログラミングのイロハをざっくりと学ぶことができる良書です。
楽しくPyMCモデルを動かして、ベイズと仲良しになれた気がします。
みなさんもぜひぜひPyMCで動かして、一緒に遊んで学びましょう!
4.楽しい写経 ベイズ・Python等
ベイズ、Python、その他の「書籍の写経活動」の成果をブログにします。
主にPythonへの翻訳に取り組んでいます。
写経に取り組むお仲間さんのサンプルコードになれば幸いです🍀
5.RとStanではじめる心理学のための時系列分析入門 を PythonとPyMC Ver.5 で
書籍「RとStanではじめる心理学のための時系列分析入門」の時系列分析をPythonとPyMC Ver.5 で実践します。
この書籍には時系列分析のテーマが盛りだくさん!
時系列分析の懐の深さを実感いたしました。
大好きなPythonで楽しく時系列分析を学びます。
6.データサイエンスっぽいことを綴る
統計、データ分析、AI、機械学習、Pythonのコラムを不定期に綴っています。
統計・データサイエンス書籍にまつわる記事が多いです。
「統計」「Python」「数学とPython」「R」のシリーズが生まれています。
7.Python機械学習プログラミング実践記
書籍「Python機械学習プログラミング PyTorch & scikit-learn編」を学んだときのさまざまな思いを記事にしました。
この書籍は、scikit-learnとPyTorchの教科書です。
よかったらぜひ、お試しくださいませ。
最後までお読みいただきまして、ありがとうございました。