
統計|JASP で構造方程式モデリング

この記事は完全にメモです(他記事もだけど)。
普段,分析の際には SPSS か JASP を使っていて,SEM の時だけ Amos を使っている。ただ,諸事情で「やっぱり JASP で SEM もできるようになっておきたい」と思い,今後のためのメモとしてアップした。
構成を考えずに書いてて読みづらい記事になっているからあとで直すつもり。
前半で JASP の Data Library にあるデータでコードの書き方,後半に JD-R モデルを例に適当に作ったデータで結果の見かたをざっくり説明する。今回は JASP 0.18.3.0 を使用した。
R を使えない人なので,R ユーザーから見たら「その程度のこと」かもしれんけど優しく見守ってほしい。
各パスの書き方
各パスはこのように書く。
# 測定方程式 reflective
=~
# 構造方程式 strucural path
~
# 相関 correlation
~~
# 複数の独立変数や相関のある変数をまとめる
+
例1)尺度 A の項目が4つあるとき
A =~ item1 + item2 + item3 + item4
例2)B と C → A にパスのとき
A ~ B + C
例3)A と B,C に相関があるとき
A ~~ B + C

モデルを使った実践<入力>
JASP の Data Library → 14. SEM → Political Democracy のデータを使う。
開くとそのままコードが書かれていて,結果も出てくるため,ここでは軽い説明だけする。なぜかたまにコードも結果も出ないことがあるから一応以下に示す(この黒いコードの画面使いたいだけ)。
# measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60
# residual correlations
y1 ~~ y5
y2 ~~ y4 + y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y8上記の内容を打ち込んで,Ctrl + Enter をすると結果が出力される。そのままだとパス図が見られないのでチェックを入れて表示する。手順は Fig タイトル,もしくは後半の結果編に記載あり。
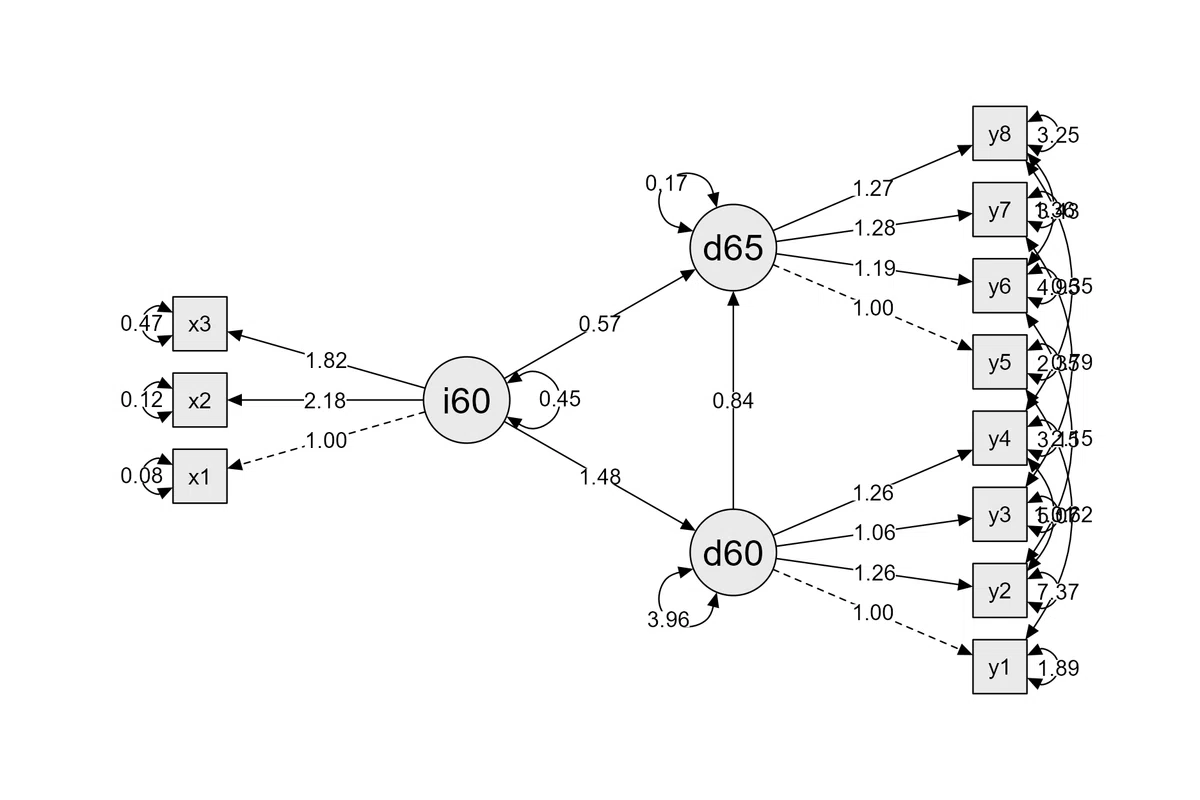
潜在変数の書き方
# measurement model
ind60 =~ x1 + x2 + x3
dem60 =~ y1 + y2 + y3 + y4
dem65 =~ y5 + y6 + y7 + y8ind60 =~ x1 + x2 + x3 は,x1, x2, x3 を観測変数,ind60を潜在変数としている。左辺に潜在変数の名前(任意)を置き,右辺に観測変数を「+」で羅列する。潜在変数と観測変数の関係にある場合は,左辺と右辺を「=~」でつなぐ。
dem60,dem65 も同様。
パスの書き方
# regressions
dem60 ~ ind60
dem65 ~ ind60 + dem60dem60 ~ ind60 は,パスが刺さるほうを左辺,パスが出るほうを右辺としている(dem60 ← ind60)。
dem65 ~ ind60 + dem60 は,ind65 と dem60 から dem65 にパスが刺さっていることを示している。
相関(共分散)の書き方
# residual correlations
y1 ~~ y5
y2 ~~ y4 + y6
y3 ~~ y7
y4 ~~ y8
y6 ~~ y8y1 ~~ y5 は,y1 と y5 間で相関を設定していることを示している。
y2 ~~ y4 + y6 は,y4 と y6 が y2 と相関を設定していることを示している。
ちなみに「#」はコメント機能(メモ)で,あとでみたときにこの部分は何を書いているとか示すために使う。
モデルを使った実践<結果>
ここからは JD-R model を例に挙げて分析をする。分析モデルは以下の図とした。使ったダミーデータもその下にあげた(一応 JASP ファイルも)。
雑作成なので変数名とか得点とか専門の人から見たらいろいろ気になる点はあると思うけど,今回はあくまで SEM の練習なので無視してほしい。

分析は以下のコードを実行した。
engagement ~ resources
demands ~~ resources
stress ~ demands + resources
health ~ stress + engagement結果を見る前に
以下を最低限チェックして右側の結果を確認する。
▼ Output options の以下をチェックする。
☑ Additional fit measures
☑ R-squared
☑ Standardized estimates
☑ Path diagram
☑ Show parameter estimates
☑ Modification indices
☑ Hide low indices
モデル適合度の見かた
☑ Additional fit measures
☑ R-squared
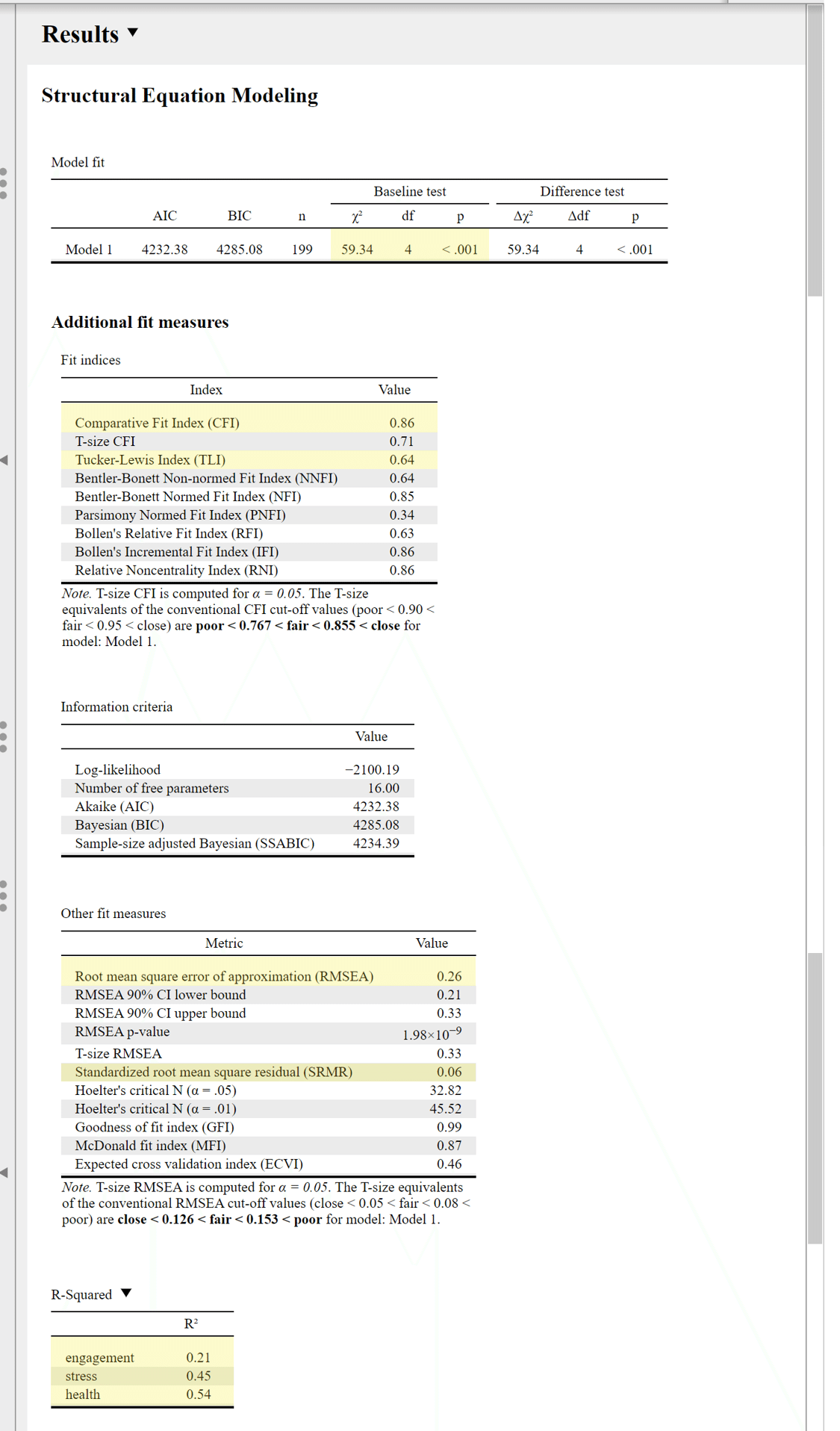
まずは今回分析したモデルの適合度の見かた(最低限)を説明する。出力結果の「model fit」「Additional fit measures」「R-squared」を確認する。黄色いのは論文に記載する内容。
うーーん,CFI と TLI がなかなか適合度が悪い,まあ即席作成データなのでそれはさておき。R² を見ると,このモデルでは「Health」を 54% 説明できているという結果だとわかった。
係数の見かた
☑ Standardized estimates
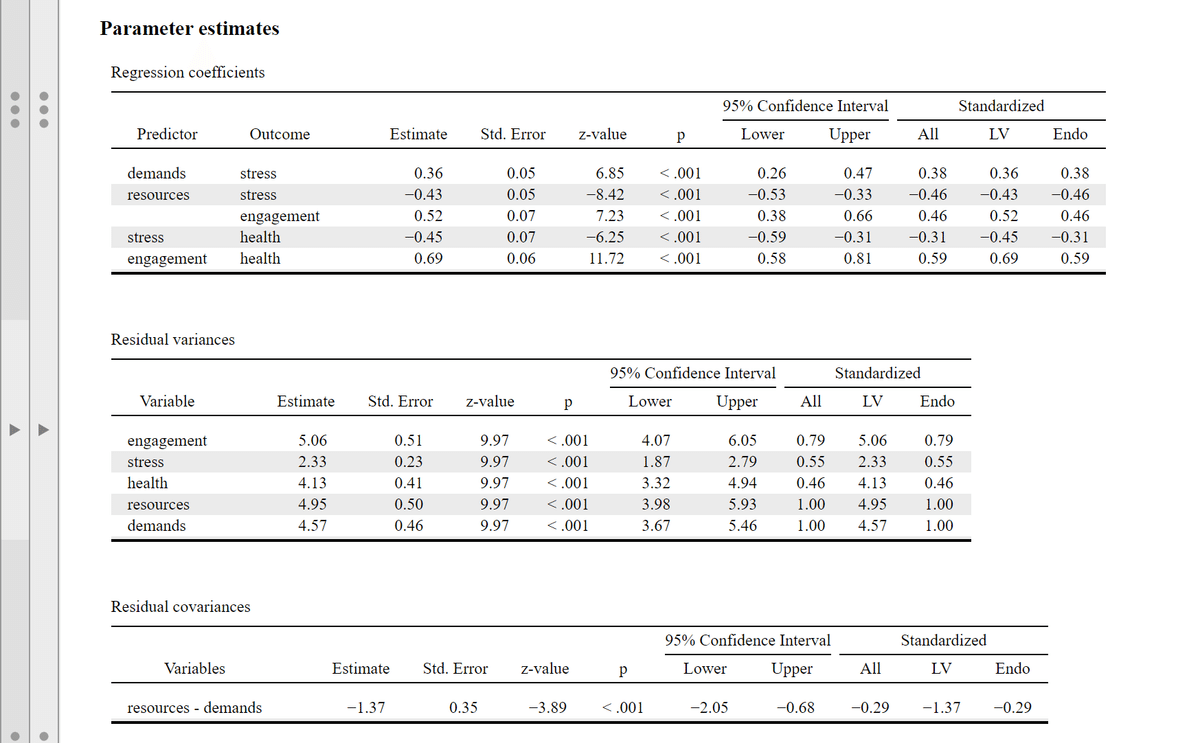
つづいて各パス係数,共分散の値について説明する。出力結果の「Parameter estimates」を確認する。☑ Standardized estimates をチェックすると,結果の一番右側に「Standardized」という列が出る。
「Reguression coefficients」はパス係数,「Residual variances」は誤差変数(e),「Residual covariances」は共分散の値を示している。
パス図の見かた
☑ Path diagram
☑ Show parameter estimates
パス図について説明は…いらないか。以下が出力された図。
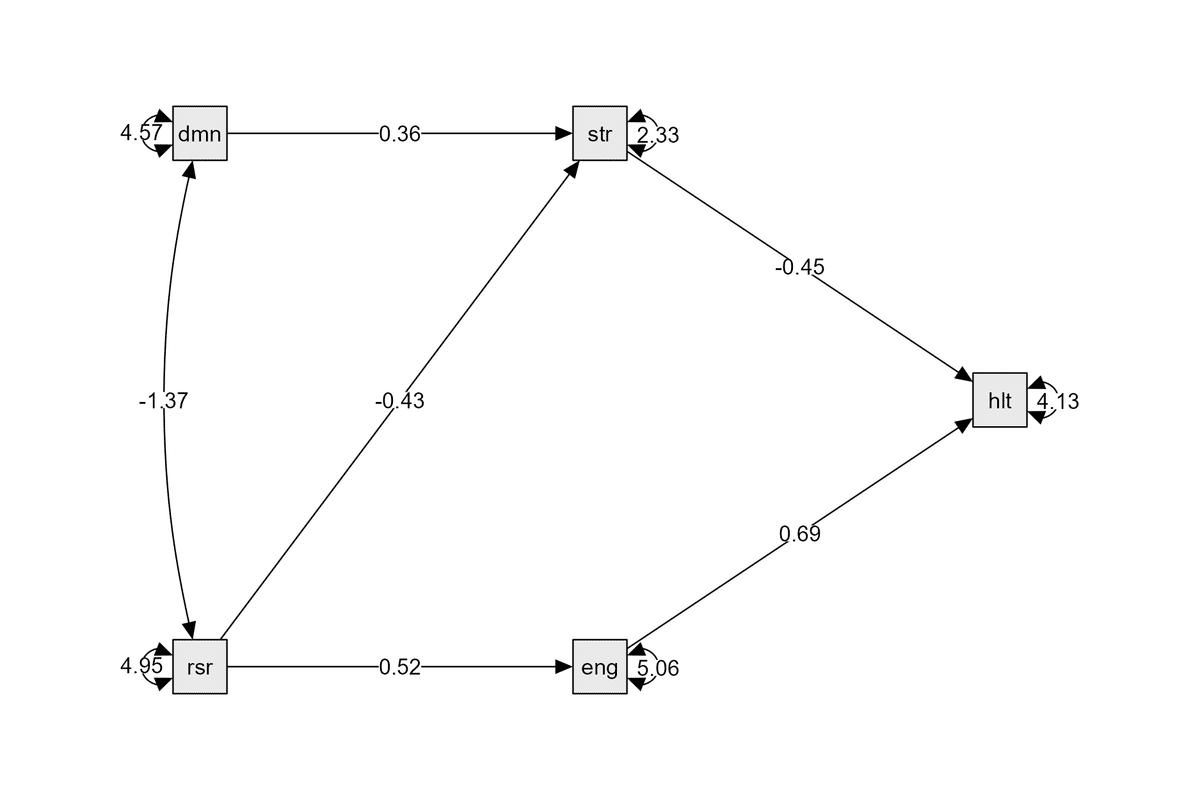
かなり以前のバージョンでは標準化偏回帰係数を示してくれてたみたいだけど,今は出してくれないらしい。不便。
図を作るときは係数の出力結果を確認しながら入れていくことになる。
モデルの修正指数の見かた
☑ Modification indices
☑ Hide low indices
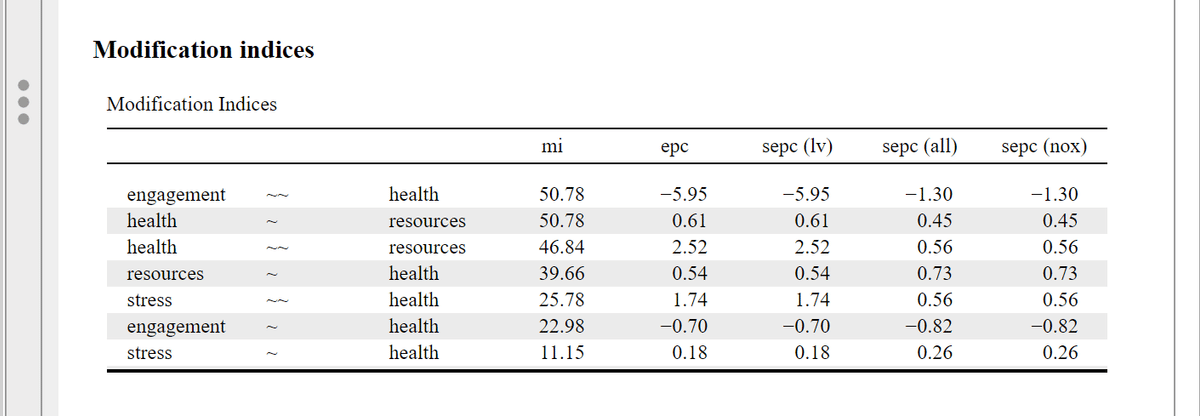
今回は修正しないが,一応モデルの修正について説明する。出力結果の「Modification indices」を確認する。「mi」が修正指数で,それに従って修正するとどのくらい変わるのかが右以降に書いてある。
修正指数いくつ以上を表示するという設定も可能で, ☑ Hide low indices をチェックして,その下の Threshold に任意の数値を入れる。デフォルトでは 10 が入っているはず。修正指数がいくつ以上のものを修正する,的なことを書いてた文献をどこかで見たんだけど忘れたのでまた今度。基本的には内容的に妥当か(解釈可能か)が問題だと思うけど。
まとめ
以上,JASP で SEM をやる方法についてざっくりまとめた。正直まだわからない部分が多くて説明を逃げたところもあるけど,のちのち調べて追記していきたい。
正規性の検定でもこの間困ったので余裕があったらまとめる予定。
なにか問題点,修正点がありましたらご連絡ください。
おまけ
JASP の引用について,HP で確認できる。
SUPPORT → FAQ → How do I cite JASP?
(先日なぜか見つからなかったので。)
< 文献 >
Bakker, A. B., & Demerouti, E. (2007). The Job Demands-Resources model: State of the art. Journal of Managerial Psychology, 22(3), 309–328. https://doi.org/10.1108/02683940710733115
JASP Team (2024). JASP (Version 0.18.3)[Computer software].
Schaufeli, W. B., & Bakker, A. B. (2004). Job demands, job resources, and their relationship with burnout and engagement: A multi-sample study. Journal of Organizational Behavior, 25(3), 293–315. https://doi.org/10.1002/job.248