
データエンジニアリングの基礎 輪読会で得た知見 後編

みなさんこんにちは!ワンキャリアでデータエンジニアをやっている野田(Github:tsugumi-sys)です!
社会人になってからお酒にハマっております。最近はめっきり暑くなってきて、ビールの美味しい季節ですね。弊社のデータだけでなく、私の体重データもエンジニアリングする必要がありそうです。さて、私のわがままボディの話はこれくらいにして本題に入っていきましょう。
はじめに
本記事は前回記事の続きになっております。輪読会の開催背景等に関しては、ぜひ前編を読んでいただけると嬉しいです!
前編では、データエンジニアリングの概要の共通理解を進めつつ、データの生成・保存に関わる技術やアーキテクチャに関する基礎知識を網羅的に押さえることができました。
後編では、まず本書の7章以降の内容を簡単にまとめます。その後、輪読会で得た知見を実際に業務に応用してみたので、そのエピソードについて共有できればと思います。
輪読会の説明
輪読会は前編と同様、以下の形式で行いました。
頻度:週1回・30
分量:2章分を目安
規模:6名
内容:担当者が持ち回りで発表。フォーマット等は自由
他チームと兼任しているメンバーも多いことから、負担にならない程度のボリュームで運用することとしました。また、初めての輪読会開催だったため、簡単なルールで楽に運用できる形を採りました。
後半(7章以降)の学び
後半では、データの取り込み・モデリング・提供までのライフサイクルに関連する基礎的な知識や技術の話がメインでした。個人的に学びになった部分を抽出し、共有します。
データの取り込みから提供まで
データの取り込み・提供するアーキテクチャを設計する上でデータの利用形態・コスト・信頼性・セキュリティの観点が重要になります。その上で、基礎的な技術(圧縮技術・ストレージ・クエリツール・アナリティクス・機械学習 etc…)を理解し、トレードオフに基づいて適切な意思決定を行う必要があります。
データ利用形態:ユースケースを明確に定義すること
開発・運用にかけるコスト:提供パイプラインやデータプロダクトを自分たちで一から構築するのか・マネージドサービスを使うのか慎重に検討すること
データの信頼性:データの信頼性を担保できるか、完全に担保できないならどう対処すべきか検討すること
セキュリティ:データを提供する上でのリスクを把握し、適切に対処すること
データモデリングについて
データエンジニアリングにおけるモデリングとは、データ分析者と生データの間を取り持つ表現と考えられます。したがって分析ユースケースに基づいたモデリングを設計する必要があります。
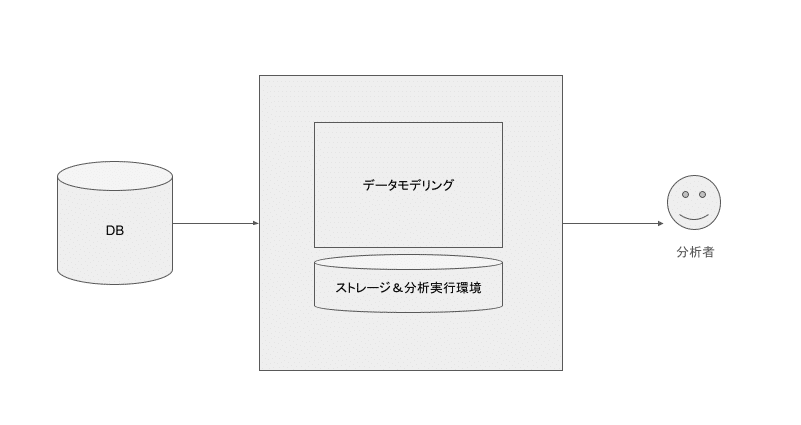
個人的な整理として、データモデリングにおける重要な関心ごとは以下の3つにまとめられると考えます。
データが利活用しやすい形で提供されること
データ処理のパフォーマンスが最適化されていること
データの変更に対して頑健であること
上記の関心ごとを達成するために、いくつかのモデリング手法が提案されています(Inmon, Kimball, Data Vault)。それぞれの手法の具体的な内容は割愛しますが、技術選定における注意事項として、各モデリング手法が考案当時のストレージ・コンピューティング環境に強く依存していることを挙げておきます。モデリング手法は利便性と信頼性・メンテナビリティの間で振り子のようにトレンドが移動していると、個人的には思います。本書に記載されていた情報を元に、以下のような歴史をたどってきたと解釈しています。
RDBMS初期からデータモデリングは考えられていた(Inmon・Kimball)。分析に向かないRDBMS上で効率的にクエリを処理しつつユースケースを満たすデータモデリングの構築が盛んに行われた。
NoSQLやDWHの登場によって初期のデータモデリング手法の流行は去った。一方で、無秩序に作成されたテーブルは利便性・信頼性を欠き、データスワンプとなってしまった。
再びデータモデリングが注目されるようになった(Data Vault)。次の関心ごとは信頼性・メンテナビリティであり、データ活用のアジリティを高めること。
本書のまとめ
技術トレンドの移り変わりが激しいデータエンジニアリング領域においては、今後も変わらないものと変わる可能性が高いものを正しく認識できることが重要となるかと思います。
本書では、基礎かつ本質的な部分はしばらく変化しないとしており、具体的には以下が挙げられています。
データエンジニアリングのライフサイクル
クラウドが提供するマネージドオープンソース・データコネクタ(Fivetran, Airbyte等)
データをやりとりするための標準化されたデータAPI
オブジェクトストレージの重要性
新世代のファイルフォーマットの登場
オーケストレーションツールの進化(IaCとコードデプロイ自動化)
ライブデータスタック(ストリーミング)
一方で、変化する可能性が高いものとしては、以下が挙げられていました。
MLエンジニアとデータエンジニアの境目、ソフトウェアエンジニアとデータエンジニアの境目
データのリアルタイム処理
現在:DWHをベースとした内部向けの分析やデータサイエンス(モダンデータスタック)
未来:データプロダクトは必然的にライブで動作するようになる(低レイテンシ・高速クエリ処理・自動化・アナリティクス・ML)
データとアプリケーションの融合
現在:アプリケーションとデータレイヤ(MLやアナリティクス)は別々のレイヤ
未来:アプリケーションスタックとデータレイヤスタックが一つになる
スプレッドシートとクラウドOLAPの融合
つまり基礎技術を深く理解し、ある程度未来を見据えることで、流行り廃りに惑わされずより良い意思決定ができることが求められます。本書では取り扱っていませんでしたが、LLMの登場によってデータのライフサイクルに発生しうる変化(特にデータガバナンスと提供方法は強く影響しそう)についても押さえておくと良さそうです。
実践:課題の整理
本書を一通り読み終わった上で、実際にデータチームのメンバーで、自社のデータエンジニアリングに関する課題の洗い出しと対応の優先順位付けを行いました。
輪読会を通じて学んだことをアウトプットするだけでなく、改めてチーム全体で課題の整理・共通認識を目的に実施しました。
まずは各個人が感じている課題を、以下の4つの観点に基づいて言語化してもらいました。
課題の概要
現時点で考えうる解決策
解決にかかるざっくりコスト
解決によって得られるざっくりリターン

本書ではデータによって付加価値を生み出すこと(ROIを最適化すること)が繰り返し述べられていたため、課題の洗い出し時点でROI観点も一緒に考えることとしました(あくまで練習。厳密さは求めない)。輪読会によってデータエンジニアリングに対する解像度がグッと向上したため、課題の洗い出しはサクサク進みました。最後に、洗い出した課題を整理しROIの観点に基づいて優先順位付けしました。
結果として、以下の課題が浮き彫りになりました。
組織・事業拡大に対して現在のデータの提供・利用方法が適していない。
提供:BIツールに負荷がかかっており、分析体験が悪化していること
利用:データ利用の複雑化・高度化により、分析が属人化していること
提供という観点では、BIツールのパフォーマンス悪化が具体的な課題として挙げられました。弊社ではエンジニア・非エンジニア問わず、社員のデータ活用が非常に活発に行われており、メインのBIツールとしてRedashを利用しております。下図は月毎のRedash上でのクエリ作成数のグラフです。今年に入ってからは社員1人あたり毎月3〜4個ほどのクエリを作成している計算になります。
直近の組織の拡大に伴ってデータ活用者も増加し、BIツールのパフォーマンス悪化が顕著となっていました。

利用観点では、事業拡大に伴ってデータ利用の複雑化・高度化が進んだことで属人化していることが課題として挙げられており、その結果、アナリストに分析・クエリ作成依頼が集中している状態となってしまいました。このままだと、社員がクエリを書いてデータドリブンに意思決定する文化がスケールできず、溜まっていくデータの付加価値を高めることができないと認識しました。
実践:解決策
上記の課題を整理したことで、ますます高まるデータ活用のニーズとそれを満たせていない現状をチーム全体で把握することができました。これを踏まえて、それぞれの課題に対する解決策の検討を行いました。
まず、我々が目指すデータアーキテクチャの理想像を言語化しました(普遍的な内容にはなりますが、チーム全体で共通言語で認識できていることが重要だと考えています)。
欲しいデータに簡単にアクセスできること。発見が容易で、簡単なクエリで取得が可能であること。
アクセスするデータは信頼できること。
上記によってエンジニア・非エンジニア問わずクエリを書いて自ら分析する文化を保ちつつ(あるいはさらに向上させつつ)、組織はスケールできること。
次に、上記で洗い出した課題を元に、解決策をチームで検討しました。それぞれデザインドックを作成しながら要件定義から比較検討、技術選定までを行いました。
BIツールのパフォーマンス改善
現状:組織拡大に伴うデータ活用者の増加&クエリ実行数の増加
課題:クエリパフォーマンスの悪化&分析体験の悪化
解決:クエリ整理&Redashのパフォーマンス改善
データマートの構築
現状:事業拡大に伴うデータ利活用の複雑化・高度化
課題:分析の属人化・信頼性低下・データ活用スピード低下
解決:データマートの構築。GCP Dataformを用いて低コストで運用できるデータマートを高速に構築する
すでに多くの利用者に影響が出ていることから緊急度が高いと判断し、BIツールのパフォーマンス改善から最優先に着手しました。検討の結果、我々の分析ユースケースにマッチしていることやROIが高いことから、現状のRedashのパフォーマンスを改善することを決めました。他のBIツールに乗り換えなかった理由として、追加コストが高くつくこと、要件を満たせないこと(無料版だと権限管理機能がない等)が挙げられました。一方でRedashの開発は盛んではないため、常に他ツールへの移行を見据えつつ現状の運用を改善していくと判断しました。
次にデータマートの構築に取り掛かることとしました。低コストで開発・運用できることと、データテストができること、(他業務と並行しながら)最速でリリースできることを判断基準とし、GCPのマネージドサービスであるDataformを採用することとしました。メタ情報を適切に管理することで、Geminiのサポートを受けながらクエリを作成できる点も大きなメリットでした。こちらは現在、より詳細な設計を行っており今後開発予定です。
まとめ
本記事では、書籍「データエンジニアリングの基礎」の後半の内容と、輪読会で得た知見を実際の業務へ落とし込んだ事例について共有しました。
データチームが発足してすぐのタイミングで、本書の輪読会ができたことは非常によかったです。また輪読会でのインプットとアウトプットをシームレスに繋いで、実践にまで落とし込めたことも大きな収穫でした。個人の感想をいくつかピックアップしたので共有します。
データエンジニアリングに対する解像度は格段に向上した。解像度が向上したことによって、弊社のデータエンジニアリングに対する課題の洗い出しがより具体的になった。
基礎的な内容を押さえつつ、比較的新しいツールや技術についても本書内で紹介・議論されているため一石二鳥だった。ツール選定を行う際に本書で得た学びが大いに役立った。
本書はシステムインフラやソフトウェア設計に関する知識が一定求められる。バックエンド/インフラエンジニアとデータサイエンティストが輪読会に同席することで、相互理解はより深まった。
この記事では、具体的な解決策に関する技術的な検討や結果については深く議論しませんでした。こちらは次回以降のテックブログで改めて紹介できればと思っております!ぜひお楽しみに!
「データエンジニアリングの基礎」はこれにて終了です!最後までお付き合いいただきありがとうございました!良いデータライフを!
▼ワンキャリアのエンジニア組織のことを知りたい方はまずこちら
▼カジュアル面談を希望の方はこちら

▼エンジニア求人票