
【統計学】トレンドがある時系列データの相関係数に騙されるな!

1.概要
2つのデータセットの関係性を知るうえで、相関係数は便利な道具である。
相関係数は計算が簡便で、分かりやすそうな統計量である反面、使い方次第では分析者を容易に誤った解釈へと導きうる。
本記事では、トレンドがある時系列データの相関係数を計算するとどのような特徴が現れるのか、検証する。
2.検証
Excelでランダムに発生させた以下の時系列データ(変数1、変数2)の相関係数を計算すると、0.01であった。


次に、先ほどの変数1と変数2に同じトレンド項を加えることで、変数3と変数4を作成する。
そして、変数3と変数4について相関係数を計算すると、0.89であった。
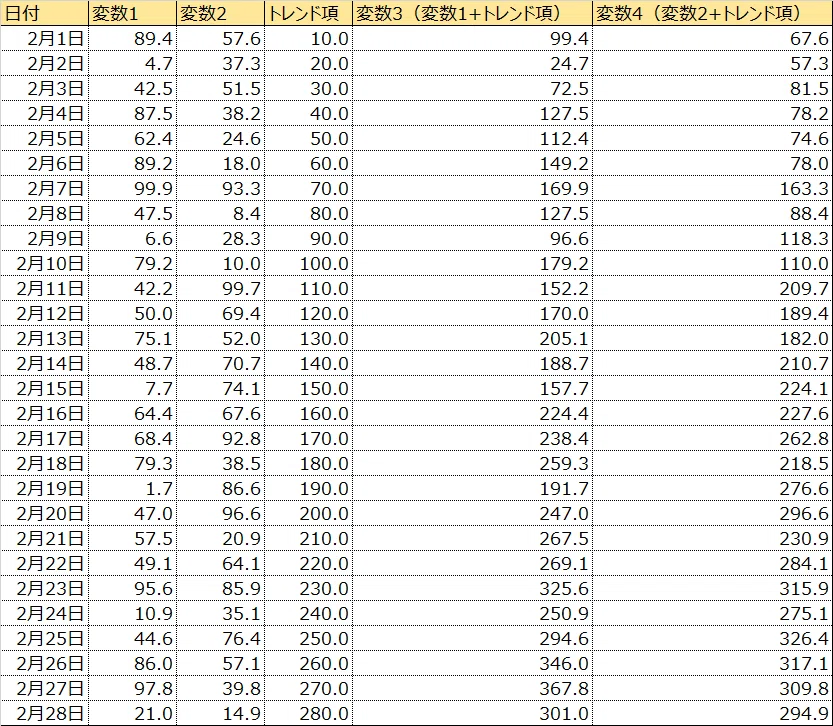

今回はやや極端な例であったかもしれないが、無相関に近い2つの時系列データに対して、同質のトレンド項を加えるだけで、相関係数が高い数値となったことが分かる。
3.結論
実験から分かるように、本質的にはほぼ無関係な時系列データであっても、外部から何らかのトレンド項が加えられるだけで、相関係数が高く見えてしまうことがある。
もう少し現実に沿った例で、アイスクリームの売上と水難事故の数が同じ時期に増加する傾向があったとしよう。これら2つのデータには高い相関があるように見えるかもしれないが、実際には直接の因果関係はなく、共通の要因である「気温の上昇」というトレンドが両方の増加を引き起こしている可能性もあるわけである。
このような相関の特性を、統計学の言葉で「擬似相関」という。ひとたび相関係数を算出してしまうと、その結果に擬似相関がどの程度影響しているのかは表面的には見えにくい。したがって、トレンドがありそうな時系列データを扱う際には、本当にそのまま相関係数を見てよいものなのか、注意を払う必要がある。
詳しくは時系列の定常性という概念を学ぶ必要があるのだが、東大の修士や博士レベルでも、このような重要な論点を無視して分析をしてしまう者は案外いる。
一見権威がありそうな者でも、いい加減な結果を出してくる者は少なくないので、安易に「定量的な分析」というものに騙されないように気をつけていただきたい。