
Amplify gen2 × prismaを利用した開発基盤

今年よりJOINしたエンジニアの上野 伸一といいます。フルスタックエンジニアで、クラウド・ネイティブな構成を積極的に採用しています。
要求分析・設計時にはアリスター・コーバーンのユースケースをベースとし、データドリブンなアプローチを好んでおり、TH-Model、TM(T字形ER) などをプロジェクトに応じて適用度を検討する、データモデリングから開発がチョットデキル人です。
Amplify gen2 × prisma を利用した開発基盤
私がはじめてAmplifyを利用したのは、gen 1、CLIがver 3(4, 5年前)でした。何も指定がなければ、Azureを採用(PaaS寄り)する事が多いのですが、AWSという指定があったのでAmplifyでもやってみるかと思い採用しました。
・・・が、エンタープライズで利用するのは早計だったと感じました。当時のAmplifyはリリースして日が浅いという事もあり、致命的なIssueの数が膨大で開発コストの7割近くをAmplify固有の環境Issueに費やす事になりました。
当時の公式GitHub Issueの中には、『解決できない問題が発生したら、一度すべて削除して環境を作り直せ』という、銀の弾丸的な解決方法が紹介されており、なかなかのインパクトでした。(gen1であれば、今でもたまにやるのが悲しいところ)
gen2では、IaC周りの刷新とSandboxによる独立した開発者用環境が利用できる点に魅力を感じ、これなら五月雨での開発において、開発者体験を下げずにうまく運用が回るかもしれないと感じました。
実際にとあるエンタープライス・システムで適用し、十二分に使えると感じたので、ちょっとしたソリューション例を交えて紹介します。
今回の例では、以下を利用します。
gen2 による変更点
gen2 では CLI 本体も変更となり、コマンドはこちらになります。
大きな変更点としましては以下となります。
amplifyコマンドから、ampxコマンドへ
IaCがマークアップからスクリプトへ ( backend.ts )
クライアントからデプロイするコマンドの廃止(sandboxのみ)
特に後者二つの採用に踏み切った事が、開発者体験の向上につながっていると感じます。クライアントから 共有環境へデプロイする機能が廃止された代わりに、sandboxという新規の隔離された環境が追加されました。開発者は ampxコマンドを利用し、個人用のsandbox環境へデプロイします。
npx ampx sandboxsandboxでは運用環境と同等の環境が新規構築され、ホット・リロードによる差分デプロイもサポートされます。ホット・リロードという単語から推察できるように、環境構築のIaCはbackend.tsというコードベースで記述するように変更になりました。
gen 2によるIaC周りの公式DOCはコチラになります。
sandboxが正常に構築されると、プロジェクトルートにamplify_output.json が生成されます。中身はsandbox環境への接続に関する情報です。gen 1の頃のaws-exports.jsに該当します。
クライアントから本ファイルを読み込む事で該当環境へ接続します。またファイルを本番やステージング、他の開発者が準備したamplify_output.jsonに差し替える事で、異なる環境に接続する事が可能となり、切り替えや共有も容易です。
├── amplify <== IaC用のディレクトリ。backend.ts などもココ
├── src <== 任意のクライアント
├── amplify_outputs.json <== 接続情報の唯一のファイル
├── package.json
└── tsconfig.jsonPrisma
PrismaはTypeScriptと相性の良い次世代のORMで、型安全なデータベース操作が可能です。特に以下の点が気に入っています。
スキーマの作成や変更に伴うmigration用のSQLを自動で生成し、接続先毎にどこまで適用しているのかを管理して実行する。
アグリゲート(集約エンティティ)の事前定義を行わず、データ取得時に条件を記述する事で、型セーフにアグリゲートを定義できる。
後者についてモデル図を元に簡単なサンプルを示します。
サンプルの概念モデル図は以下です。
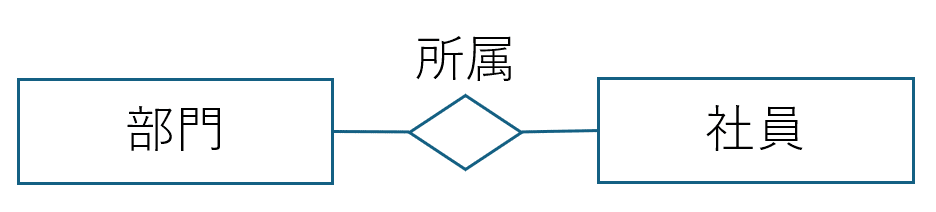
上記の論理モデル図は以下です。(ツールや表記などは好きなものを選択して良いと思います。)
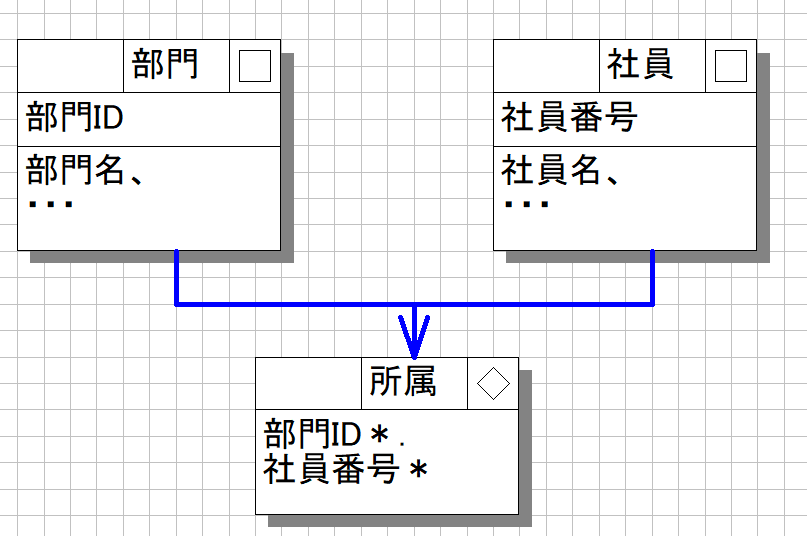
本モデル図は、部門と社員というリソース・エンティティと、それを紐付ける所属という関連エンティティ(対照表)の三つを示しています。
上記の設計を元にprismaで、物理モデル定義を行います。(スネークケースは ホスト先RDBMSがpostgreSQLを想定)
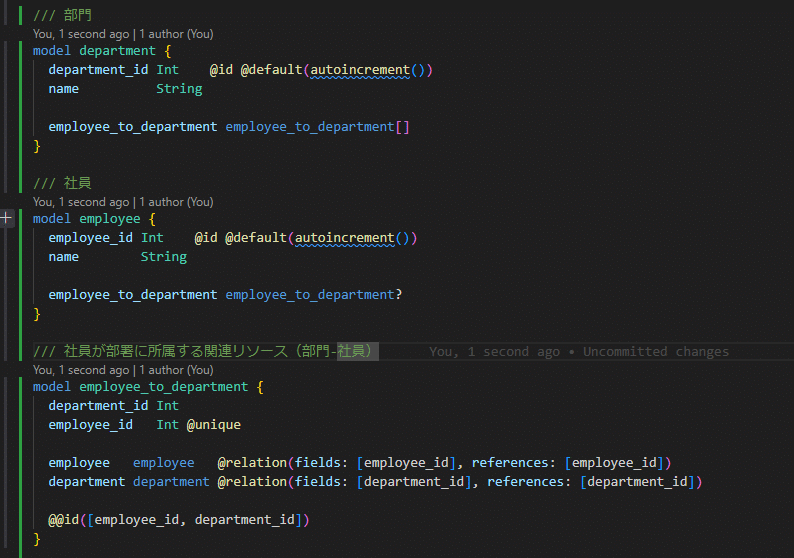
このコード例では、departmentに 二つの属性のみ(department_id、name)を持ちます。employee_to_departmentというのは属性ではなく、prismaのリレーション宣言となります。自動生成されたpostgreSQL上の物理テーブルにも、カラムはdepartment_idとnameしか表示されません。
定義からは、部門には複数の社員が所属し、社員は単一の部門にのみ所属できることが読み取れます。(社員が複数の部門をまたがる場合は、リレーションや制約を変えます)
なお、prismaは、CLIやエディタの拡張機能によって、定義に誤り ( リレーションや制約がDDLとして成立しない等 ) がある場合はエラーを表示してくれます。この定義ではエラー無しです。
型定義が成功すると、バックエンド側でデータアクセスを記述できるようになります。部門を検索する関数をTypeScriptで型セーフに記述する例を示します。
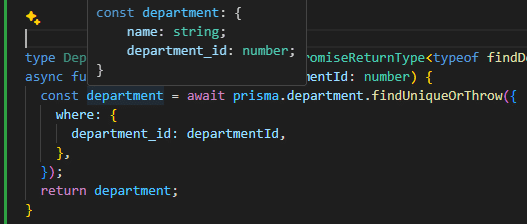
見た通り、条件に部門IDを指定し、取得した戻り値にはdepartmentの属性(nameとdepartment_id )のみが列挙されています。
次にincludes句を利用し、リレーション上で紐つくデータを含める宣言を行うと、戻り値に型セーフに所属と、所属に紐つく部門が追加され、アグリゲート(集約エンティティ)のベースが完成します。
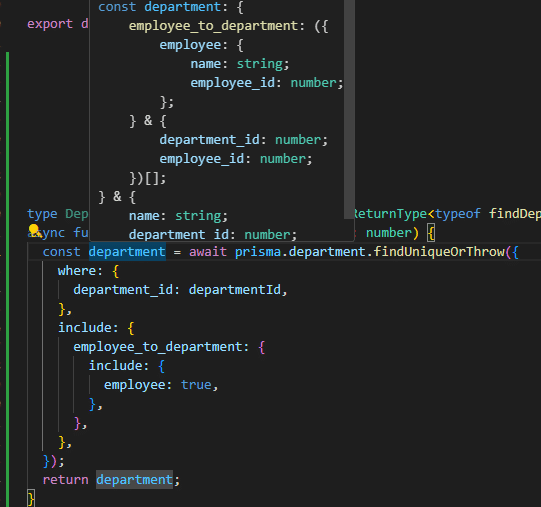
最後にクライアントに返す際に見やすく射影すると完成です。
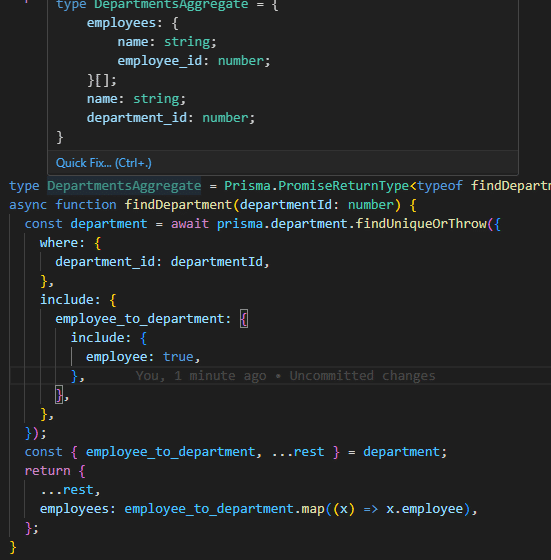
RDBMSを利用する上で、複数に分かれたテーブルのデータをどのように取得しクライアントへ返すのかが一つのポイントになります。本事例のように prismaを利用する事で、DynamoDBのようなスキーマレスなデータ構造体を、型安全にクライアントへ返す事ができます。
Prisma × Amplify gen2
prismaでは以下の二つのライブラリを利用します。
https://www.npmjs.com/package/prisma
CLIの役割があり、devDependenciesにインストールしますhttps://www.npmjs.com/package/@prisma/client
prismaファイルに記述したシステム固有のスキーマが動的反映されるので、 dependenciesにインストールします
注意点として、後者は静的なライブラリではなく、prismaファイルに記述した業務固有のスキーマを保持する役割があり、prisma CLIのコマンドを通じて中身が動的に生成されます。生成物や実行エンジンはnode_modules/.prisma/client配下に配置されます。
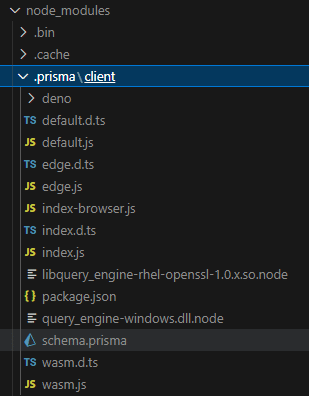
このような構成のためlocalでは動くけど、SaaSでは動かないという環境課題が発生します。そこで、AmplifyのBackend側、lambdaで利用する際にはLayerを利用した集約配置をお勧めします。以下にbaackend.tsのCDK記述例を示します。
import * as lambda from "aws-cdk-lib/aws-lambda";
const prismaDynamicAssemblies: lambda.AssetCode = lambda.Code.fromAsset(
"node_modules/.prisma/client"
);
const layerVersion = new lambda.LayerVersion(
backend.createStack("prisma-layer-stack"),
"prismaLayer",
{
code: prismaDynamicAssemblies,
}
);利用するlambda.FunctionのaddLayersメソッドを呼び出す事で、lambdaから利用できるようになります。
trpcLambda.addLayers(layerVersion); // lambda に 上記のレイヤーを追加最後にLambdaがレイヤーに配置されたモジュール群を参照できるように、環境変数を指定します。
PRISMA_CLI_BINARY_TARGETS: "native,rhel-openssl-1.0.x",
PRISMA_QUERY_ENGINE_LIBRARY: "/opt/libquery_engine-rhel-openssl-1.0.x.so.node",CI/CDでデプロイする際には、常にPrisma CLIを利用してスキーマを最新化した後に、レイヤーへ配置されるように適宜 ビルドパイプラインを構成してください。
ここまではprismaを利用したサーバー側での例になります。
次にクライアント側から利用する際に型セーフなアクセスを実現するライブラリが、trpcになります。
trpc
バックエンド側で定義した関数をジェネリクスを通じて透過的にクライアントで参照できるライブラリになります。型指定シンタックスの恩恵によりクライアント側は、あたかもバックエンドで定義した関数を直接呼び出しているように扱えます。
今回の開発構成は以下となります。
AWS Amplify ( Lambda:Node.js )
Prisma
zod
バリデーション
React / react-hook-form
バリデーションライブラリも各種ありますが、npmトレンドや利便性を鑑みた上でzodを選択しました。
trpc周りは以下です。(すべてver 11.x。rcとか喜んで使っちゃう派です。)
使い方は公式などを見ると分かりますが、ちょっとしたテクニックをいくつか紹介します。
trpc - Brotli 圧縮
Lambdaを、公式DOCの手順通りに作成すると提供されているawsLambdaRequestHandlerを利用してレスポンスをセットする実装になります。
import { awsLambdaRequestHandler } from "@trpc/server/adapters/aws-lambda";
export const handler = async (
event: APIGatewayProxyEvent,
context: Context
) => {
try {
const ctx= { event };
return await awsLambdaRequestHandler({
router: appRouter,
createContext: () => {
return ctx;
},
onError: (opt) => {
const { error, type, path, input } = opt;今回は背後のデータアクセスにprismaを利用する事で、大量データを高速にクライアントへ返す事が可能となりました。具体的にはlambdaのレスポンス制約の6MBにおいても1 sec以内にレスポンスを返す程度です。
(大量のデータを返す意味についてですが、Autocompleteの 遅延ロードによる サーバー通信ではなく、1秒ですべて読み込めるなら、マウント時に全件取得しクライアントに完結した絞り込みを実現するなど、UXが向上するパターン等があります)
そこで、returnする前にレスポンス・データに対してBrotli compression圧縮を行いました。圧縮レベルはパフォーマンスと圧縮率を鑑みて、5で設定しています。
レスポンスのヘッダーに"Content-Encoding": "br",と記す事で、クライアント側は特に意識する事なく、圧縮されたデータを復元してくれます。
サイズは1/6程度まで圧縮され、パフォーマンスへの影響は微々たるものでした。レスポンスを返す際には、Brotliを介すのはお勧めです。
Brotliや様々な圧縮アルゴリズムに関する比較などは検索するとヒットすると思いますので、調べてみてください。
trpc - superjson
永続化先のRDBMSでは日付型をサポートするものが多くあります。Prismaもサポートしています。しかしクライアントに伝播するとJSONを通じて文字列型に置き換わってしまいます。
そこで、trpcのtransformerミドルウェアを利用し、superjsonを間に入れる事で、バックエンドで日付型だったデータがクライアントでもそのまま日付型として扱えるようになります。
trpc周りのバックエンドは以下のようになります。
/** --- _trpc.ts --- */
const t = initTRPC.create({
transformer: superjson,
});
export const router = t.router;
export const publicProcedure = t.procedure;
/** --- _trpc.ts --- */
/** --- findDepartmentSchema.ts --- */
export const findDepartmentSchema = z.object({
/** 比較企業のUIDリスト(必須) */
departmentId: z.number().min(0),
});
export type FindDepartmentParams = z.infer<typeof findDepartmentSchema>;
/** --- findDepartmentSchema.ts --- */
/** --- departmentRouter.ts --- */
const departmentRouter = router({
find: publicProcedure.input(findDepartmentSchema).query(async ({ input }) => {
return await findDepartment(input);
}),
});
/** --- departmentRouter.ts --- */
/** --- appRouter.ts --- */
export const appRouter = router({
department: departmentRouter,
});
export type AppRouter = typeof appRouter;
/** --- appRouter.ts --- */クライアント側は↑のAppRouterを型指定します。
export const trpc = createTRPCReact<AppRouter>();AppRouterを経由する事で、最初の例でバックエンド側に定義しました findDepartment関数にクライアント側から(例ではReact)透過的にアクセスできるようになります。
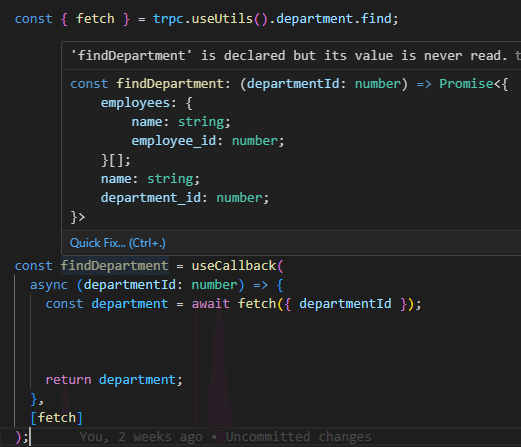
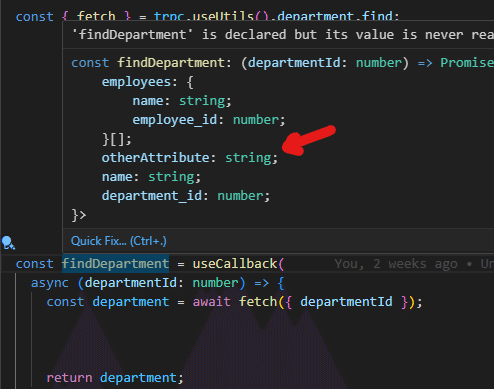
ちなみにバックエンド側のfindDepartment関数に適当に属性(otherAttribute)を追加したとして・・・
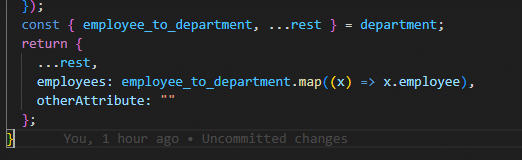
ジェネリクスで参照しているため、利用するクライアント側も属性が追加されています。
まとめ
APIからクライアントまでを一気通貫して型セーフに開発できるライブラリとして、Prisma, trpcをAmplify gen2と組み合わせる事で、開発者体験の向上を実現しました。
今回は大枠について簡単に紹介いたしましたが、細かい対応(各環境毎に RDBMS のスキーマをすみ分けるパイプライン等)もあり、機会があれば紹介いたします。
長文にお付き合いいただき、ありがとうございました。
最後に、このような新しい環境や取り組みについて前向きに検討し、情報発信する機会を与えていただいた シェルパ・アンド・カンパニーに感謝を述べさせていただきます。
次は、マーケティングの小川さんです!お楽しみに⛰️🧗