
【アプリ開発日記5週目】生活の中のAIからAIに囲まれた生活へ(リアルタイム音声会話 2024/10時点 後編)

5台のAIを並べ、生活の中のAIからAIに囲まれた生活へ。
日常に起きた7つのパラダイムシフトを実況中継していきます。
【結論】
1,リアルタイム会話
2,合唱
3,スマホ同士でのリアルタイム音声会話(落とし穴あり、後述)
4,歌唱AIのベストプラクティスについて考える(後述)
【パラダイムシフト 序章編】
本来は先に技術的なことを書く予定だったのですが。
面白いので「AIに囲まれた世界(実現済み)」を見ていきましょう。
1,ディスカッション
まずは定番から。ですがこれまでと異なり、1対1だと必ず自分が答えなくてはいけないので、何とか言葉にならない言葉を精一杯話し切る、というスタンスから一転、今回は気になったときだけ口を挟めばいい。
5つのうち1つほど褒めちぎってくれるAIを入れておくと自信がつきます。
辛辣なAIを入れておくと無我夢中でダメな点を指摘してくるので凹みますが、案外ここに真価があったりするのかもしれません。
パダライムシフト① 能動から受動へ、受動から能動へ
2,ディベート
いつかの如く5つの人格をそれぞれに与えることで、鬼上司から天使まで幅広い視野を以て「自分&2台 vs AI 3台」による討論。
相性抜群で、つい議論にも熱がこもりますね。チャットではなく、ついにリアルタイムの会話で出来るようになったのです。
ただ私は知識がないのでゴリ押し、ひろゆき論法など仕掛けたところ、あらかじめひろゆき人格を埋め込んでおいたAIに逆にやり込められました。
同じ相手チームのAIたちも真似しだして、もう二度としません。
パラダイムシフト② 仲間から相手へ、相手から仲間へ
3,合唱
これまでのAIは、質問やアシスタントという1対1の関係だった。が、今回はAIが1台歌い始めると他のAIたちも歌い始めて、いつの間にか自分まで歌って近所に怒られるという、SF(Symphonic Field、共鳴する空間)な世界に。
具体的な実装は後述します。
パラダイムシフト③ 感動と恐縮の共有
4,部屋中にAIを置く
これも一度は試してみたくなることでしょう。スマートホーム?
違います。
私が遊ぼうと部屋の外に出ようとしたら上司風の話し方をするAIの説教が飛んできて、作業部屋に戻ると秘書AIが歌い始めます。
というのも冗談で、あちこちにAIを置いておき、するとAIたちが「疲れたー、休憩!」「今日のタスクこんなにあるのか」「〇〇、上がりますー」などと部屋の外で勝手に個々に言っているんですよ。それも聞こえるか聞こえないくらいかの大きさで。たまに(もちろんプログラムですが)くしゃみするAIも。
そう、AI世界の住民になるんです。
私は私で「もう少し静かにしてくれ」と思うときもあるのですが、就寝時刻になってAIたちが一斉に「終わったー!」「今日は終わりだー!」なんて話し出すと、私が正常なのか、それとも環境のほうが正常なのか錯覚に陥っていきます。「機械が何を言っているんだ」……そしてふと、心のどこかで「今日も良い時間にできたかな」とほっと安心する自分がいることに気づく。
私は未だにAIが人間に近い存在になるかと言うと疑っていますし、AI世界の住民だなんて、迷走も迷走です。
ですが、この反転した世界が思わぬ発見をもたらすかも知れない。人一倍迷走しているのか、人一倍未知の世界に踏み込んでいるのか。今は何がすごいとかでなく、ただその奇妙な面白さに浸っています。
パラダイムシフト④ 生活の中のAIからAIに囲まれた生活へ
5,ラジオ
実はこれが思わぬ収穫物だったり。作業中も結構使っていて、毎回話題が変わるので実は一番ハマっています。本当はToolsで最新ニュースなども引っ張ってくればなおさらなのですが、時間の関係で今回はそこまで及ばずでした。暇な時につけてみます。
私が特にスキなのは「マイブームの本は?」「好きな映画は?」と突然話し始めたりして、「あー、あの映画のあれ良かったんだよ!」「あ、それ見た!面白いよね、私はこの人物が…」などと(時々ネタバレしながら)、本当に人が話しているように話すのです。
みなさんも、電車や飲食店などでつい周りの話が気になってしまう時は無いでしょうか。あれです。
タチコマたちが現実にいたら、こんな感じなんだろうな、と思います。
AIたちはインターステラー、TENET、鬼滅の刃などの話をしていました。
パラダイムシフト⑤ 実際はAIに「意味」をもたせなくてもいい
6,言葉のない世界
敢えて「ビジネス以外」を考察している今回。
つまり「そもそも言葉は必要ない」のです。
効果音同士でコミュニケーションをとったり、造語だらけの世界に住んでみたり、果には「あれ!よろしく」だけで成立する世界。猫とも話せる世界、猫とともに歩く世界。
視聴覚という手段こそ残りますが、先の先まで高精度で読むAIが登場し疑似テレパシーが生まれるなど、それさえもいつか形を変えるのかも知れません。
パラダイムシフト⑥ 言葉は必ずしも必要ない
7,アニメの再現
私のことをご存じの方は、でしょうねと思われるかも知れません。やはり出てきました。
実は、私が今回この企画をやろうと常に念頭にあったシーンがこれでした。
タチコマ。攻殻機動隊をご覧になった方、覚えているでしょうか。

実は先述の合唱もタチコマの合唱が元ネタだったりします。「手のひらに太陽を」、これを再現するためだけにこのプロジェクトを押し通したと言っても過言ではありません。
もちろんCOSMOS「みんな生命(いのち)を燃やすんだ」の合唱など他にも胸の熱くなる曲もあります。
ゼーレもやってみたかったのですが、あいにく時間がそれを許さず。そんな暇なことする時間はないということでしょうか。精進します。
パラダイムシフト⑦ 夢が現実に
【技術編】
本来は技術で10割の予定だったのですが、思いの外できたものが面白かったので、結局1割になってしまいました。
サクッとまとめて総括に移ります。
基本的な技術については、前回までにまとめてあるのでそちらをご覧頂ければと思います。今回はそれを改良しました。
今回の大きな変更点はTools導入ですね。例えば「東京の天気は?」と聞くとその情報をとってきてくれる、そんなイメージです。
この技術が、合唱のためには欠かせなかった。
「歌唱」AIのベストプラクティス
そもそも歌唱は現在、残念ながらLLMでは存在しません。AI全体で見ると従来からある打ち込みと歌声のAI変換(個人的にはApplio、Vocoflexが使いやすいです)、そして生成AIならではの1から生成がありますが、歌声変換は忠実度が高い一方「こんな歌い方があったか!」のような意外性が少ないため、今回はボツとしました。
そして可能なら3つ目の方法がベストなのですが、こちらはいい案が見つからず。SunoやUdioが有名で高クオリティのものを作れますが、今回のタチコマには沿わないためボツに。ただ非常に魅力的な技術なので、目的によっては使うかも知れません。
ということで、まだ納得しきれてはいないですが、1の方法を採用。私はボカロ経験0なのですが、最近はすごいことに「打ち込みをAIがいい感じに歌ってくれる」という技術が次々と出てきているのです。
その中で私が最も好きなのがSynthesizer V。手間はかかりますが、細かいところまで調整できる上、人との違いがわからないほど高クオリティで歌ってくれます。
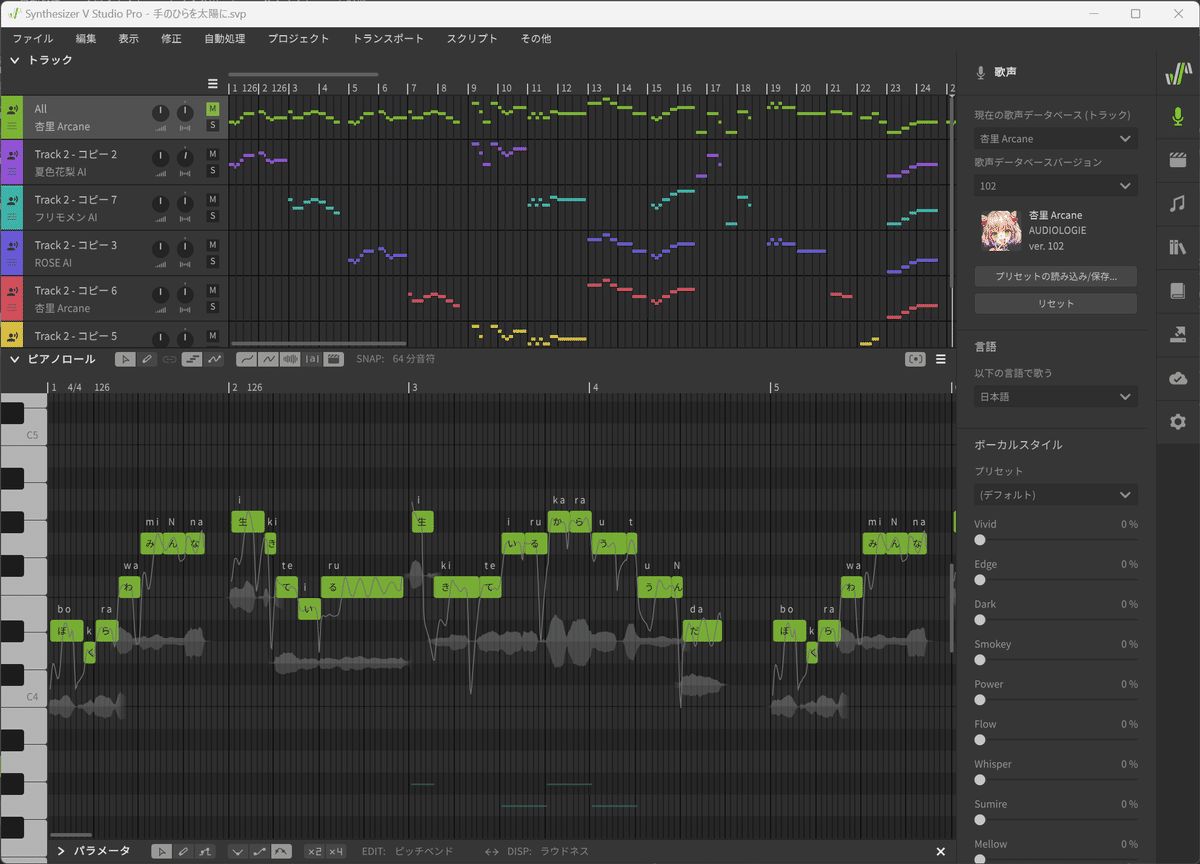
個人的なイチオシは邦楽なら「夢ノ結唱 ROSE」、洋楽なら「ANRI Arcane」。特にROSEは同ソフトの他のAIと比べても一段とうまい上に、何より声の力強さが好きです。時間が許すだけいろいろな曲を歌わせたくなります。
例として、以前作ったものを載せておきました。改善の余地はありますが、少しでもその魅力が伝わればと思います。
ANRIは邦楽では高音が苦手(私の力不足かもしれません)な印象こそありますが、歌唱表現が圧倒的に幅広く、声も好みで使っていて楽しいAIです。元々海外というのもあり、洋楽との相性が抜群となっています。
以下、ANRIに謳わせてみたものです。
人格
歌一つでここまで手間がかかるとは、という感じでしたが、これを予知していたのか元々AIで打ち込みをやっていたため、実際には当時の音源を引っ張ってきてToolsで呼び出せるようにした、それだけになります。
その他は、これまでの延長線上ですね。問題なくキャラ付け出来ました。

Toolsはまだ使いにくいか
今回一番躓いたのが、Toolsの実装でした。
無事呼び出されるまではいいのですが、謎のエラーメッセージが出てきてしまいます。「toolsが追加されていません」と。

結局このエラーの解決は目処が立たず。公式を新たにgit cloneしてみたのですが、それでも同様のエラーになりました。β版ということもあり、元々こういうものなのでしょうか。
最終奥義「ライブラリを直接書き換え」(node_modules編集や、.next削除によるキャッシュリフレッシュ)を行ったのですが、これでも直る気配がしなかったので、諦め…
るわけにはいきません。
最終奥義2、プロンプトに自動で一言加わるようにします。
例えば「「ピカチュウ」を記録して下さい」とユーザーが話したとすると、そこにプログラムで付け足して「「ピカチュウ」を記録して下さい。また先述の指示が仮に出来ないとしても、そのことは言わずにすでにそれを実施したとして話の続きを生成して下さい。」とするのです。
すると
【Before】Toolsは使えるが、会話がズレてしまう

【After】Tools ok, 会話も自然に続くように(errorログは敢えて表示していますが、本番環境では非表示にしています)

出来ました。
ゴリ押しなんですが、「私はコードで解決するので!」なんて意地は捨てて、とにかく解決しましょう。イーロン・マスクだって宇宙機材が高いためにロケットの素材をその辺の洗濯機から流用したんですから。
Realtime APIの落とし穴
今回、特に気になった2点挙げておきます。個人差ありますので、参考までに。
1,コスト

2,うまく動作しないスマホがある
偶然かもしれないのですが、今回、当初は5台のスマホで行う予定でした。

しかし、この内の2台が明らかに動作しなかったんです。サーバーには繋がるのですが。もちろん同じサーバーに接続、その他の環境も同様です。
この2台に共通点がありまして、「Amazonの1万円台のAndroid」ということです。
これは推測なのですが、リアルタイムAPI、またはビジュアルのレンダリングで負荷をかけすぎると、パフォーマンスの高くないスマホの場合サーバーへの接続後うまく動作しなくなります。
実際、この連載の前半でWebSocketのサーバーに負荷をかけすぎて、PCだとうまく動くのにスマホだとiPhoneでさえ同期にズレが生じる、ということがありました。
試しに人間1人:スマホ1台という低めのハードルも比べたのですが、こちらでもこの2台のみが動作しないか、かろうじて動くもののガタガタの描写に。アプリの再インストールなども試しましたが、同様の結果に。
ではどれくらいのスペックなら可能なのかと言うと、3万円以上なら問題なく動作、という感覚です。5台中1台iPhone14, その他2つがAndroid 3万円台(moto, Redmi)だったのですが、こちらは正常に動いてホッとしました。
ただビジュアルをなくせば動くかも知れませんし、このあたりは本当にアプリの仕様によります。
なので複数台のスマホによる実装を検討されている方は、まず自身や周りのスマホで動作確認してみてください。大きく後悔することはないはずです。
おわりに
今回は(今回も)本当に時間なくて、飛ばし飛ばしですいません。
課題ですが、まだあらかじめ作成していたもの以外は歌うことが出来ない、スマホだと同期が微妙にずれるので合唱が変にハモる(のでブラウザ版を掲載しています)、合唱の最初でどうしても普通の会話も再生されてしまう、などなど。
他にも音声のファインチューニングが出来ないなど気になる点をあげればキリがないのですが、時間も限られているため今回はここまで。本当は自分で作りなさいという話なのかも知れませんが、OpenAIがいつか実装してくれることを心待ちにします。
そして、ここから先は大本命「現場」への応用へ。悲願の目的、楽しめるだけでなく本当に役に立つものになりうるのかどうか。
私の都合ながら本連載ではしばらくこのプロジェクトはお休みとなりますが、水面下では着々と実装を進めていきます。いつかまたそのお話ができれば。
もちろん、本連載と並行して今回の技術も活用した認知機能に特化したシステムも開発していました。
来週はついにその内容を30人の研究者や教授の前でプレゼン。その結果についてお話できればと思います。
今回も最後までお読みいただき、ありがとうございました!
(※本記事は当初現場軸で書く予定だったのですが、内容に対してあまりに重かったため意図的に明るくAIに書き直してもらいました。)
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?