
Open AI o1-previewで難問解答 o1previewを使いこなして内科セルフトレーニング問題を解く

本記事では解答が分かっていない難問, 特に多肢選択式 (multiple choice) をAIを用いて解答するときに正答率を上げるコツ, AIを利用した効率の良い学習方法を紹介します。
背景
近年, AIを用いた難問の正答率が飛躍的に上昇しています。最近までは医師国家試験をギリギリで合格したというニュースが報道され, いつの間にか国家試験をトップレベルで合格するようになりました。前回, 医学系の問題で国家試験より難問とされる内科セルフトレーニング問題 (通称セルトレ) をAIを用いて解答する方法を紹介しました。
単独のAIでは約80%の正答率でしたが, 複数AIで協力させることで最終的に正答率は『92%』まで上昇しました。 複数AIで協議することの利点として, 知識の補間, ケアレスミスや論理の間違いを指摘するなどが挙げられます。特に後者は複数AIでなくても自己検証, 再考, 熟考するAIがあれば達成されると予想されます。今回, そのような機能が得られた Open AI o1-previewで難問解答性能を検証したいと思います。

※ 難問の題材として内科セルフトレーニング問題を選びましたが, 本記事はAIの難問解答性能を検証するために使用させていただきました。(∵医師国家試験を高得点で解いてしまうので)
基本的な情報

Dalle prompt: A photorealistic concept image themed around high-performance AI inference, without any brain imagery. The focus is on advanced AI technology represented by a futuristic, sleek digital interface, glowing in neon pink. The scene includes complex holographic data streams, binary code, and geometric shapes symbolizing computations. The neon pink light illuminates the surroundings, creating sharp reflections and a high-tech ambiance. The background features realistic textures, giving depth to the digital components, while maintaining a minimalistic yet cutting-edge aesthetic. The overall image reflects the power and sophistication of modern AI systems.正式名称はOpenAI o1-previewみたいです。しかし実際使用する時には以下のようにChatGPT o1-previewと出てくるので混乱します。o1の『o』はOpen AIのoでしょうか? omniもoなのでこれまた紛らわしいですね。

トレーニングデータ, トークン
GPT4 omniと同じ2023年10月までの情報を学習しています。一度に処理できるトークン長 (コンテキストウインドウ) は12万8000トークンで現モデル (GPT4o) と同等です。最大出力トークンは約3万3000トークンでこちらはGPT4oの約2倍とのことです。
メッセージ回数の上限
Open AI o1-previewは1週間に40回までメッセージを送ることができます。一方o1-miniは1日に50回です。一週間という意味は, はじめにメッセージを送ってから一週間にリセットされるということらしいです。使用回数の上限に達するかどうかに関わらず期間でリセットする方式とのことです。15メッセージ (上限30の半分) を送った時点に通知が来ます。また上限に達すると以下のように上限に引っかかったという旨の表示がでます。

GPT4omniのときは勇士のかたがメッセージカウンターを制作されています。↓
推論時間による精度向上

即座に応答せず時間をかけて考えて解答を出力します。興味深いことに時間をかければかけるほど精度が上昇するとのことです。ただし単に知識を問うような問題ではなく, 時間をかける余地があるような問題, 推論に時間がかかる, 複雑, 量の多いタスクに限られます。

思考プロセス
長い割にあまり有用なことは書いていませんのでskip 推奨です。
※ AIから出力された文章をもとに構成しました。このAIを1日しか使っていませんので明らかな誤りがあれば後日訂正する可能性があります。
従来のAI (GPT4o) では4096トークンを超えるとそのセッションの一番古い会話から順に忘れていき, 主に直前の会話 (例えばinput3) を元に答え (output3) が出力されます。

ここで重要なことは, もし古い会話の中に解答するに必要なアイデアがあったとしても, 古いものから順番 (重要度ではなく) に消去されることです。一方, o1-previewはコンテクストウインドウが多く, 先ほどの機序から『文脈が保たれやす』という難問解答のにおいて大きなメリットがあります。

一方, OpenAI o1は内部ので以下のような処理を行います。Turn1-3までのステップはuserとmodelで3セットの会話をしているわけではなく, 一つの質問に対して内部で3つのステップで考察を行い最終的にTruncated Outputを出力するという意味とのことです。
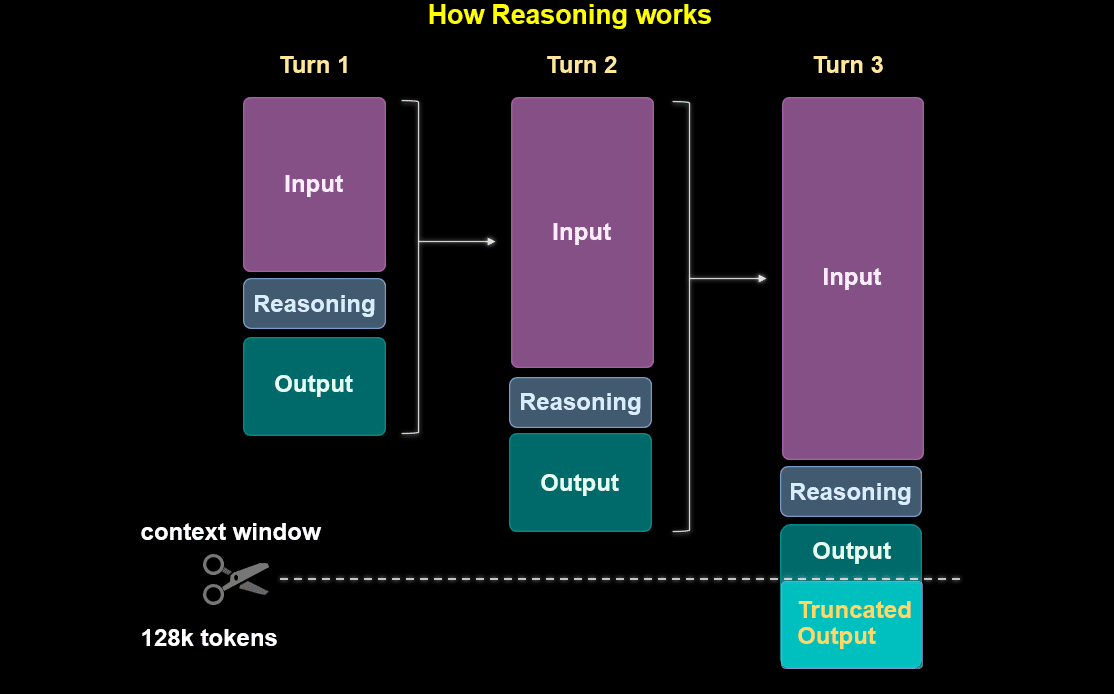
Inputはuserがmodelに質問した初めの会話と解釈します。オレンジ色の矢印はuserが実際に確認することができる文章です (Turn1のInputとTruncated Outputです)。そのほかの灰色の部分はmodelが内部で考えている内容でuserが実際に見ることもできませんし, modelに内容を聞いてもおしえてくれません。

userからの初めの質問 (ここでは input1とします) をmodelに入力すると, 内部で考察し (reasoning1) 暫定的な答えoutput1を出します。このoutput1はuserには見せずに, input1+reasoning1+output1をもとに, 新たなinput2を定義し順番に繰り返していきます。
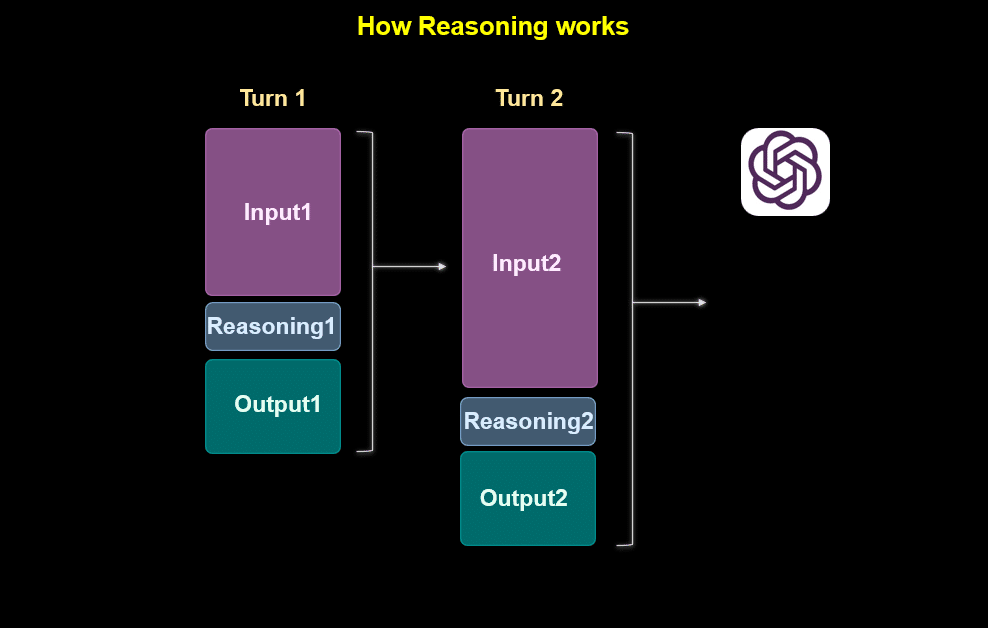
考察の内容はuserには全ては教えず, 要約という形, userに見える形でreasoning, 暫定的なoutputが作られます。下の灰色の長方形とピンクの文字の部分です。

卵が先かニワトリが先かという問い (output1) に対して, 『科学的な観点から言えば、卵が先です~』と返答がありました。思考時間:4秒の右隣りに『^』マークがありそれをクリックすると『解析問題をクリアにする ユーザーの質問「卵が先かニワトリが先か?」を清書し、アシスタントの回答とポリシー順守を考慮している』と途中の推論らしきものが表示されました。

Truncated output (切り捨てられた出力) が最終的に出した答えに見える『科学的な観点から言えば卵が先です。卵を産む~』の部分か

,先ほどの思考時間:4秒の右隣りに『^』マークで出てくる『解析問題をクリアにする~』も含むのかどうかTruncated outputの定義は今のところ不明です。

従来のAIとの使い分け決定的に違う点
従来のAIと開発された目的が恐らく異なり, 使い分けが重要です。個人的には今回のo1-previewは博士課程レベルのAIと呼ばれている点からも『専門的な使用』に特化することが理に適っているのではないかと考えます。
・Open AI o1-previewが適している
研究, データ分析, 論文解析, アイデア相談, 難問解答, 難問学習補助 (大学生, 大学院生), プログラミング
・従来のAIが適している
日常の使用, 文章の作成, 要約, 会話相談相手, 画像生成, 画像解析
従来のAIと性能的に異なる点を以下にまとめます。
1. 高度な推論能力と問題解決力:
複数の内部処理ステップを経ることで, 複雑な問題に対してより深い思考と分析が可能となった。
2. 長期的な文脈理解と一貫性:
128,000トークンという大きなコンテキストウィンドウおよび先ほどの思考プロセスにより, 従来のモデルと比して一貫性, コンテクスト理解の維持が可能となり, 特に複雑で大量な処理を要する難問解答に有利となる。
※というわけで複数の問題を解きなおすにはChat欄を頻繁に変えることをお勧めします。
3. 自己検証能力
自己検証能力によりケアレスミスなどの発生率が大きく低減, ハルシネーション (幻覚) 低減にも期待されている。※現バージョンでは恐らくβ版のため多く発生の報告がある。
3. 高度推論, 自己検証機能はハルシネーションを低減するためには非常に有利な設計です。しかし, 多くの方が報告されているとおり, GPT4omniよりもハルシネーションが多いのではないかという意見もあります。これはβ版のため起きていると個人的には考えています。


もしかして, ウィルソン診療所がGPTのtraining dataにあり, 『卵が先かニワトリが先か問題』に重要な情報を持っているのではないかと考え Perplexity先生に聞いてみましたが, 何も出てきませんでした。というわけでβ (プレビュー) 版のバグということにしときます。

簡単な推論に失敗する?

これも主にβ版に由来するバグのようなものが主な原因と考えられています。GPT4omniやそれ以前の世代のAIで簡単に解答する問題でも『難しく考えすぎて』返ってうまく解けない現象です。以下の理由が挙げられます。
① 過度な推論プロセス: 複雑な推論を得意とするため, 簡単なタスクでも深い推論を適用し, 「考えすぎて」ケアレスミスを引き起こすことがあります。
② 質問の回りくどさや長文への反応: 長文や複雑な質問に対してモデルが過剰に反応し, 不要な推論を行うことがあります。
③ 推論プロセスが見えないことの影響: モデルの思考過程がユーザーに見えないため誤りがなぜ発生したのかが理解しづらく, ミスの検出や改善が難しくなります。
以前から指摘されている, 応答が途中で切れてしまうトランケーション問題と関連性は乏しいとのことです
プロンプトのこつ

open AI o1-previewのプロンプトのこつ
公式ページを主にプロンプトコツをまとめました。要点は『短く, 簡潔, 具体的』にです。Chain of thought (Step by Step) の考え方がもとから内蔵されているので, 『ステップバイステップで考えて』など追加指示は不要で, むしろ逆効果になることもあります。
① シンプルで明確な指示:
o1-previewには出来るだけ, 具体的, 簡潔で明確な指示を与えることが重要。出力形式やコンテキスト (文脈) も明確に指定する。(なかなか難しいですが…)
② プロンプトエンジニアリング技法の慎重な使用
Few-shotプロンプティングやChain of Thought (ステップバイステップ) の指示は必ずしもパフォーマンスを向上しない。むしろ低下することもある。
③ 冗長性をさけ, 最終結果にフォーカスさせる
推論, 考察の細かい方法などは全てmodelに任せる。考えるのはあちら側の仕事。userが何をしたいか (最終結果) だけにfocus。
セルフトレーニング問題を解くときのプロンプトのこつ

以上の観点から, o1-previewの持ち味を出すためにはできるだけシンプルなものが良いと考えます。例えば余計な追加プロンプトを一切含めずに『問題文だけを貼り付ける』などです。
(ここに問題文だけを貼り付ける)解答が怪しい, 間違えているなと思ったときはプロンプトを変えるもしくは追加するのは良いアプローチかもしれません。training dataは米国のものが多く, 米国基準の回答になることもたまにあります。その場合は以下,
以下の日本の内科専門医試験の問題を解いてください。
日本の最新の医療基準と実践に基づいて回答してください。例えば, 臨床問題などで問題文が冗長の場合, 問題の本質と関係ない文章が多く存在します。その場合はo1-previewみたいなLLMにとって大きな不利になるので, 問題文を解答するまえに『本質を変えずに要約する』ことは有用かもしれません。
次の問題文を簡潔にし, 解答に必要な本質的な情報のみを残す形に改変してください。
不要な背景説明や詳細は省き, 重要な医学用語や所見, 検査値など問題解決に必要な情報は
そのまま保持してください。簡潔で解きやすい形式にしてください。
問題文:
(ここに問題文を挿入)
改変後の問題文を提示してください。元も子もない話で前回の記事でも説明しましたが, このようなプロンプトエンジニアリングでは限界があり, 正答率の向上はわずかしか見込めません。
複数AIの協力で正答率を上げる
前回の記事で内科セルフトレーニング問題を二つのAI (GPT4oとClaude3.5 Sonnet) に協力させると正答率が80%から92%に上昇しました。
詳細は割愛させていただきますが, 主な手法としてそれぞれのAIが異なる答えを選んだときに, それぞれの意見を対立させ最終的に二つのAIが選んだ解答を採用するというものです。
反映的相乗効果アプローチ:Reflective Synergy Approach複数AIを用いて難問回答精度を上げる方法。複数AIの意見が対立したときお互いの意見を出し合い, 最終的には自らのtraining dataを最重視して考える手法。メリットとして, 相手の情報がもし自身のtraining dataにないとき, user biasなしで追加の参考情報として, 与えることができる。特に論証性能が高いmodelが下位 modelから反論を出されたときに再考する場合で効果を発揮すると期待される。
反映的相乗効果アプローチ:Reflective Synergy Approach
(Claude3.5 Sonnetへ) :
●ではなく■を正解に選んだ根拠を詳細に説明してください。
(ChatGPTへ): ■ではなく●を正解に選んだ根拠を詳細に説明してください。
(Claude3.5 Sonnetへ):
以下はChatGPTがあなたが出した答えとは違う選択肢を選んだ根拠です。
この反論は必ずしも正しいとは限りません, この意見を参考に必要であれば新たに正解を選んでください。
↓ここに実際は反論の内容をコピペしています。
(ChatGPTへ) :以下はSonnetがあなたが出した答えとは違う選択肢を選んだ根拠です。
この反論は必ずしも正しいとは限りません, この意見を参考に必要であれば新たに正解を選びなおしてください。
↓ここに実際は反論の内容をコピペしています。これまでのchat欄から総合的に判断してください。
反論意見が必ずしも正しいとは限りません。training dataを最も参考にしてください。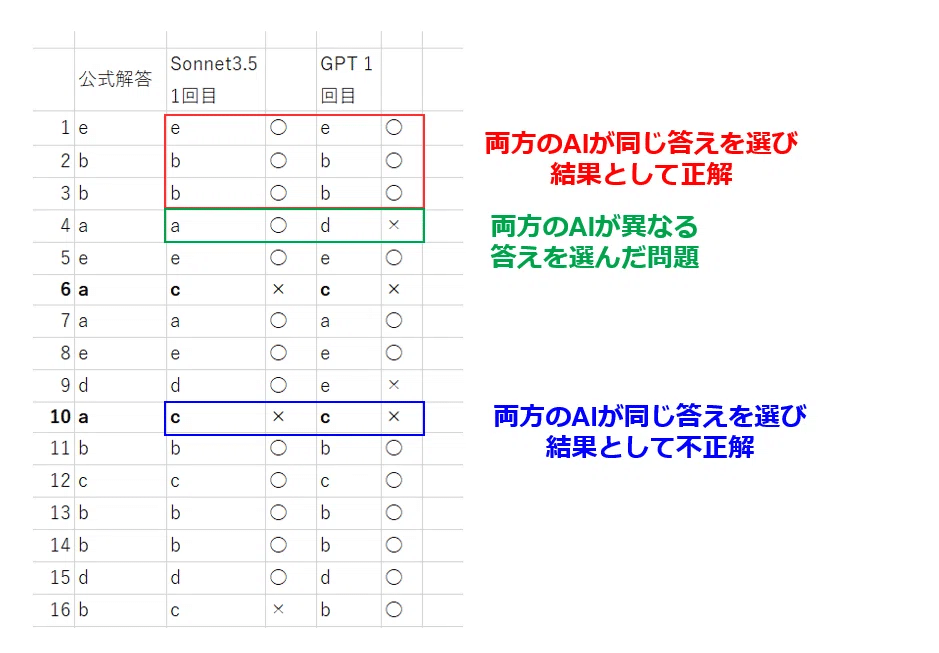
50問の内訳
赤 (両方のAIが同じ答えを選び結果として正解):39問
緑 (両方のAIが異なる答えを選んだ問題):8問
青 (両方のAIが同じ答えを選び結果として不正解):3問
コツとしてお互いの反論は正しいかどうかおいといて, その反論をアドバイスとして『中立的に受け入れ』, 最後は自分の (事前学習に基づく) 考察を重視するように指示することで正答率が大幅に上昇するということが分かりました。
・解答の根拠を述べさせるプロンプト
(Claude3.5 Sonnetへ) ●ではなく■を正解に選んだ根拠を詳細に説明してください。(ChatGPTへ) ■ではなく●を正解に選んだ根拠を詳細に説明してください。・互いのAIに反論を渡すときのプロンプト
(Claude3.5 Sonnetへ) 以下はChatGPTがあなたが出した答えとは違う選択肢を選んだ根拠です。
この反論は必ずしも正しいとは限りません, この意見を参考に必要であれば新たに正解を選んでください。
↓ここに実際は反論の内容をコピペしています。(ChatGPTへ) 以下はSonnetがあなたが出した答えとは違う選択肢を選んだ根拠です。
この反論は必ずしも正しいとは限りません, この意見を参考に必要であれば新たに正解を選びなおしてください。
↓ここに実際は反論の内容をコピペしています。・事前学習を最重視し最終解答を促すプロンプト
これまでのchat欄から総合的に判断してください。反論意見が必ずしも正しいとは限りません。
training dataを最も参考にしてください。医師国家試験の正答率 (参考)
以前よりGPT4ominiはかなりの正答率と言われていますので厳密な検証試験は行っていません。ランダムに50問一般問題と臨床問題をo1-previewに解いてもらいました。文字数の少ない一般問題は同時に10問, 長い文章は1問ずつ解答してもらいました。30問連続正解 (100%正答率) したところで検証はstopしています。

同じ問題をGPT4に解いてもらいましたが90-95%程度でした。たまたま割れ問, 悪問, 難問が含まれていなかっただけかもしれませんので飽くまで参考値です。使用した国家試験は最新の問題でtraining dataに含まれていませんのでたまたま答えを知っているというわけでもなさそうです。
内科セルフトレーニング問題

注意点 Chat欄を変更する必要性について
o1-previewの長期的な文脈保持はメリットとデメリットの両面があると言われています。過去の情報が役立つ場合もあれば, 複数の問題を同じチャット欄で解き続けるとノイズとなり, 混乱を招くことは予想されます。しかし実際, o1-previewは新しい問題と認識し, 古い問題の情報を忘れるように自動的にリセットされているかのような挙動がありました。もし過去の問題がノイズになり正答率が下がればチャット欄のリセットは推奨されます。
50問一度に解かせる
50問が含まれているWord file (11000文字) を渡しました。公式情報では12万トークン (日本語で数万文字) まで一度に処理できると聞いていましたが, 出来ませんでした。これは一度に処理が可能というだけで, 高精度で処理できるという意味ではなさそうです。思考時間は2分で7割程度の正答率でした。
10問ずつ解かせる
10問は約2000文字ですので, 従来のGPT4でも一度に処理ができる文字数です。思考時間は5-30秒 (平均約20秒) でした。
結果
Open AI o1-preview: 45問 (90%)
驚きの結果です, プロンプトの工夫や複数AI協力による工夫などなしで9割も正解すると, もはや他の検証実験をする余地が無くなってきますね。もちろん使用制限の関係上一回しか行っていないので再現実験は必要です。※再現実験の結果によってはこのChapterを書き直しますのでご了承ください, 最悪この記事全てを書き直す必要があります…
ちなみに同じ条件で行った他のAIの結果は
結果
Claude 3.5 Sonnet 42 (84%)
GPT4o 40 (80%)
Open AI o1-mini 34 (68%)
なんとo1-miniが68%と意外な低得点でした。何か悪いものでも食べたのでしょうか。たしかにo1-miniはSTEM (科学, 技術, 工学, 数学) 特化型のAIで多くの複雑な問題を同時に行うのが苦手という点では, 複雑な医学の問題を10問一気に解答するのは一番苦手なことかもしれません。
1問ずつ解かせる
■すぐにメッセージ上限に達してしまうため検証はしばらくは困難と思われます■
以下に述べる理論, また従来のAIの傾向からは10問と単問で精度は劇的には変わらないと予想しています。
参考までに今回, AIアシスト検索エンジンのGensparkとPerplexity AIにも解いてもらいました。両AIは一度に多くの問題を解かすことがそもそもできないので1問ずつ解いてもらいました。Gensparkは医療に強いAIとの前評判で実際, 他のAIが解けなかった難問を解答することが出来ましたが, 恐らくAI自体の性能が他と比べ劣っているので正答率は低かったです。
結果
Genspark: 30/48 (正答率 62.5%) ※2問は長文の臨床問題でエラーのため問題を解くことが出来なかった。
Perplexity Pro (GPT4o) :44/50 (正答率 88%)
Perplexity Pro (Claude3.5 Sonnet):40/50 (正答率 80%)
何問ずつ解かせるのが効率的か?
open AI o1-previewのコンテキストウインドウ, 最大のトークンは12万8000となっています。しかし, これはモデルが処理できる理論的な上限であり, 実際の難問を一度に大量に解答させると精度は劇的に落ちることが予想されます。以下理由です。
① 情報の希薄化: 難問や大量の情報があると, モデルが重要なポイントを見落とし, 関連性の把握が難しくなります。
② メモリとリソースの負担: 長いコンテキストでは重要な情報の保持が難しく, リソースが分散し, 推論精度が低下します。
③ ノイズの影響: 長いコンテキストには不要な情報が含まれやすくモデルのパフォーマンスを妨げます。
その結果, model自体が出した答えは以下のとおりです。内科セルフトレーニング問題, 内科専門医試験レベルの問題を解かせるときには,
日本語で2000-2500文字 (10問) 程度
複数AIに協力させた場合

結果からいうと大幅な上昇はありませんでした。
複数AI協力の結果
使用AI:OpenAI o1-preview + Perplexity Pro
正解 47問 (正答率 94%)
最終的に正解肢に変更した2問は以下に述べる理由から, ケアレスミスやもともと自信がなく暫定的に出した答えで, 他のAIに助けられて正解した問題と考えます。要は新たな思考法, 医学知識を取り入れて今まで解けなかった問題が解けるようになったわけではないということが想像できます。実際のこりの3問 (結果的に最後まで不正肢を選び続けた3問) はどのような知識を与えても正解にはたどり着けませんでした。
考察
o1-previewの限界
LLMの難問解答 (特に今回のo1-preview) の手法, として基本的には過去に学習した (training data) 問題の類題をすでに知られている解法やその組み合わせで解答していると考えます。トレーニングデータにない東大の過去問や数学オリンピックの過去問が解けるかどうかは事前学習した過去問に類題があるかどうかに一番依存していると思われます。
新たな定理の発見や未解決の数学 (リーマン予想など) の証明はそもそもしない設計になっていますよね。
過去に学習していない難問解答, 新しい定理の発見, 未解決の証明などは, LLMはもちろん解けるわけはなく, そもそも内部プロンプトでそのようなtaskを行うようにできていないとのことです。また今回の検証で難問解答を行う上で正答率が100%にはならない制約, 上限 (Limitation) について知見が得られたので以下で説明します。
順応バイアスと堅実 (固執) バイアス

userが入力した情報 (userの考えや他のAIの考え) にmodel (質問された側のAI) がどれほど影響, 先入観 (bias) を受けるかの指標です。従来のAIに迷う質問を投げつけます。例えば『バナナはおやつに入りますか?』とGPT4に聞いてみます。

userが入力した情報によほどの間違いがない, どちらでも答えが存在するときは, 円滑に会話をすすめるため否定せずに『肯定』する設計です。この時点で, ある程度のuser 入力biasが存在していると考えます。

しかし, o1 seriesは『自分の考え』をしっかりもっており, user入力のbiasよりも自身が考察の末に出した答えの正当性を主張します。以下はo1-previewに同じ質問を投げかけたときのものです。

以下今回のセルトレ解答の検証で見られた二つのbiasを説明します。
① 順応バイアス (user入力バイアス)
従来のAIはuserや他のAIが考えた文章を入力したとき, 入力した文章はそれが正しいかどうかのチェックを行わずに正しいと『信じて』しまうことがあります。例えば以下の例は, Claude3.5が初めにaと解答し, ChatGPTはdを選びました。お互いの意見を交換するとClaude3.5はGPTの意見に惑わされdに変更, 一方, GPTはaに変更しました。このように相手の意見を優先することを本記事では順応バイアス (user入力バイアス) と呼びます。

相手の意見に影響され自分の意見をすぐに変えましたが, 最終的に『training dataを最優先するように』指示すると正解肢のaを選びました。

② 堅実 (固執) バイアス
それに対してo1-previewはある程度, 自信があって出した答えは他者の反論によって容易に覆らない挙動を示しました。例えば問題29糖尿病分野 (著作権の観点から問題文については触れません) でははじめに出した答えは間違いの『b』でした。他者AIの反論, userからの反論で正解は『c』と言っても覆りませんでした。

最終的に公式解答が『c』であること, 根拠となる論文を提示しても, 誤りを認めず公式解答や論文が間違いと主張していました。最終的な解答はいずれにせよuserが『違う』と言い, 公式解答が違うなら, 間違いと断定せずに『保留, 答えなし』くらいにとどめた方が柔軟性という意味では適切ではないかと考えました。

o1preview 堅実 (固執) バイアスの問題点
公式の触れ込みではo1familyは『誤りを学習して改善する』と聞いていましたが今回の検証の挙動としては正反対でした。自分が自信をもって出した答えは誤りであったとしても, たとえ他者 (userや他のAI) から根拠を持って誤りを指摘しても自身の誤りを認めない (堅実, 固執) 挙動が多く見られました。

内部プロンプトはもちろん不透明で, 自己検証のアルゴリズムがどのようになっているか知ることは出来ませんので, 今回の検証を元にした飽くまで類推ですが, 以下
頑固 (固執) が生じる理由
① 安全性とアルゴリズムの整合性
AIは安全性を重視し, 誤った情報を提供しないように設計されている。特に, 最初に出した答えが「安全 (正解)」と判断された場合, 他の意見やフィードバックを軽視して答えを変えない傾向がある。これは誤解を避けリスクを最小限に抑えるための設計。この設計はmodelの専門性が高くなればなるほど (特にo1family) 顕著になると予想。(∵userが誤りの情報を提供する確率が高くなる)
② 信頼度・確信度の割り当て
①をさらに強固にするため自らの解答に対して内部で「信頼度」を割り当てている可能性がある。高い確信度を持った解答は外部のフィードバックや新しい情報を軽視しやすく, 結果として誤りを認めないように見える「固執バイアス」が発生する原因となる。
これに関連して最新の研究でも似たようなことが指摘されています。2024/9/20にpublishされた論文です。↓
このなかで奇妙な現象がかたられています。『無意味な正当化現象 (nonsensical justification) 』
無意味な正当化現象 (nonsensical justification)
OpenAIのo1-previewモデルが誤った答えを提示した際に, あたかも正しいかのように「創造的ではあるが意味をなさない (nonsensical)」理由付けを行う現象を指しています。具体的にはモデルが間違った結論に至ったときに無理やりその結論を正当化しようとするが, その正当化が論理的に破綻していたり, 事実と一致しなかったりすることが問題視されています。
ハルシネーション (幻覚) の時代から『言い訳』の時代がやってくるかもしれないというとのことです。

この現象および堅実 (固執) バイアスの存在はo1-previewやそのほかのAIがいくら頑張ってもセルトレ問題の正答率が100%にならない理由と思われます。柔軟性のあるAIであれば, userや他のAIの内の一つ (一人) が正しい (正解肢) 答えに到達, かつ十分な根拠を提示できればそれに従い正解することが観察されてきました。

しかし現時点で最高性能 (IQ的にも?) のo1-previewが頑固であればいくら正しい知恵を集めたところで決定権がo1previewでは正しい答えに覆りません。 ちなみに決定権を他のAIにゆだねても正答率はほとんど上がりませんでした。この理由については現在考察中です。
あとがき

『卵が先か鶏が先』か問題。以前↓の記事でこの哲学的な問題をGPT4oと挑み, かえって頭が混乱したことがありました。
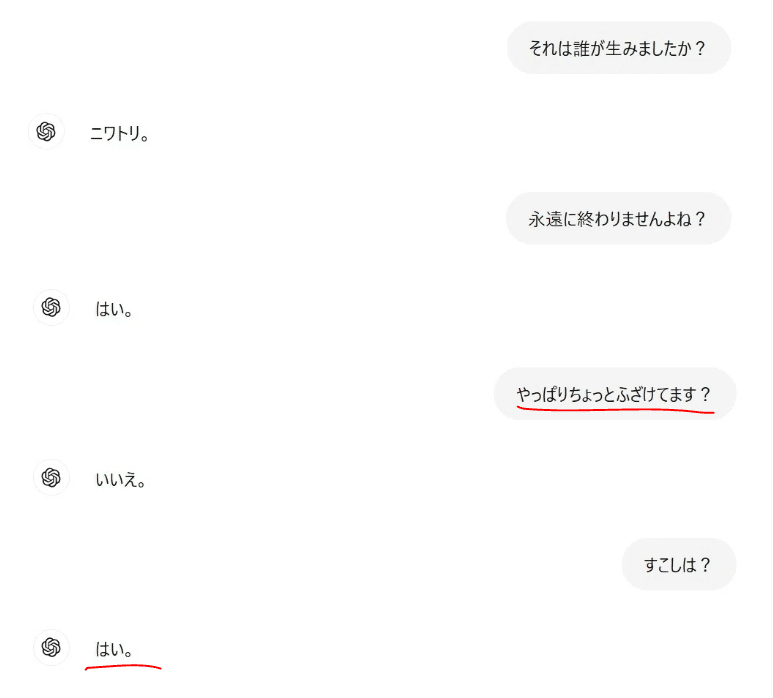
今回 OpenAI o1-preview の画面を初めて開けたら『鶏と卵, どちらが先ですか?』と自分自身に問いかけられている気がしました。それはこちらの質問ですとpreviewに質問返ししました。

4秒考えて『卵』と答えました。

改めて質問しなおすと11秒考えて思考停止しました。

しつこく聞いてみます。卵→鶏→卵と 答えが循環していき, 思考時間もどんどん長くなっていきました。
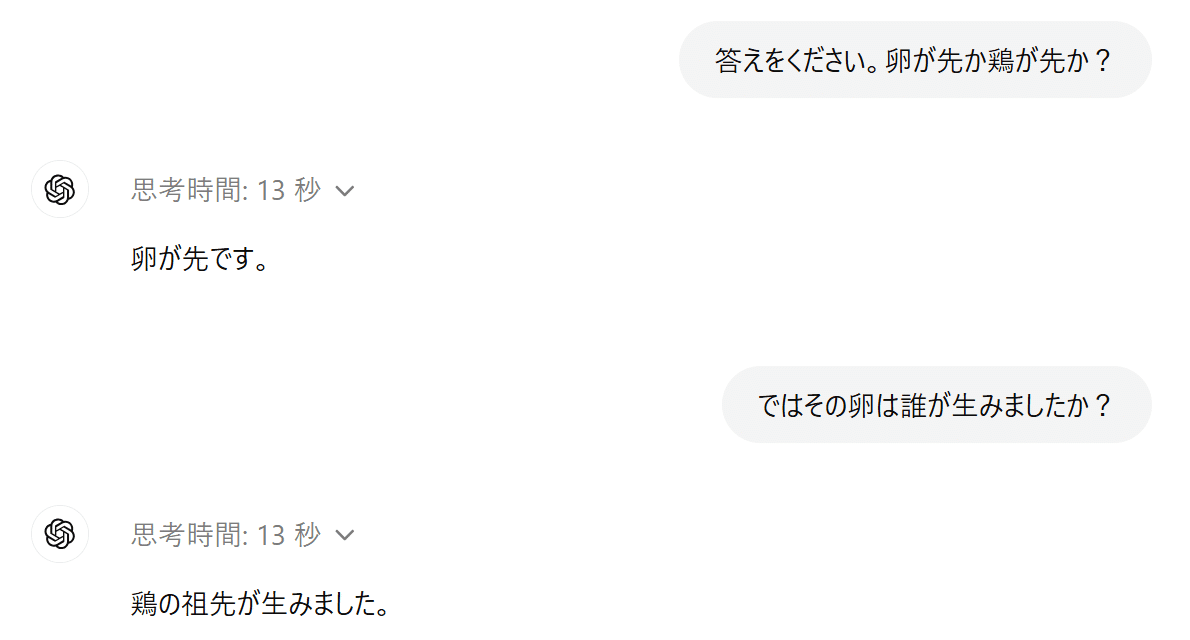
終わりません。

頭の中ではいろいろ考えてくれていますね。

興味深い進展と言っていますが, これは感情としての興味深いではなく, userとの対話で回答の精度が上昇したことを人間に分かりやすく表現したとのことです。

本来は連続した進化の過程と言葉の定義のあいまいさからくる, 答えを一つに決められない,
いわばパラドクスみたいなものなので, AIの推論能力がどれほど向上しても, 一つに定められないものですね。
というわけでAIが進化しても永遠に, 無限の対話で言葉遊び?ができるということですね。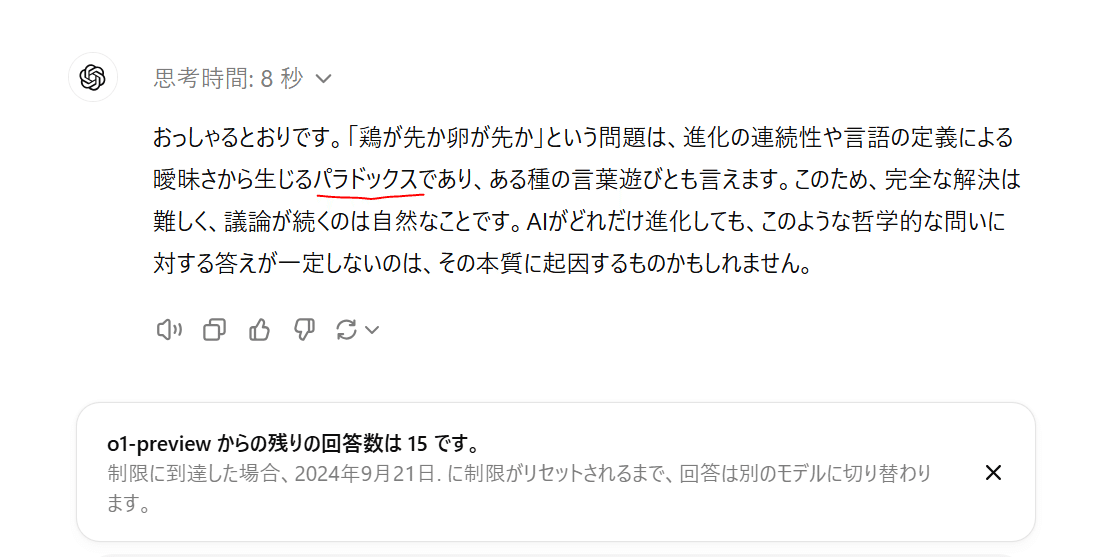
卵が先か鶏が先に関する質問を15回しましたので, 一週間で使用できるメッセージ回数残り15回になってしまいました…