
【生成AI】入門者としておさえておきたい「大規模言語モデル(LLM)の現状の全体感」(2/3)

世間では、生成AIの話でもちきりになっている。企業内では、誰も彼もが生成AIを話題にする。だけれども、ニュース記事やスタートアップ企業のニュースリリース、今を時めく某研究者のコメントなど、局所的な取り組みについての話ばかり。
これから生成AI、その中でも大規模言語モデル(LLM)について理解したい人にとっては、「木を見て森を見ず」のような説明ばかりで、まったく全体像が理解できない。局所的な話ばかりで、互いの説明が矛盾しているように思えてしまう。
まずは、大規模言語モデル(LLM)に関する話の全体感をおさえておかないと、誰の話に注目したほうが良いのか、今後のトレンドを踏まえて、何に注力していくべきかわからない…
そこで、大規模言語モデル(LLM)に関する最近のサーベイ論文を読んで見て、全体感を整理してみる。全3回にわたり紹介したい。今回はその第2回目。
前回の記事はこちらを参照
大規模言語モデル(LLM)構築方法を概観してみよう!
前回同様に、大規模言語モデル(LLM)の全体感をおさえるために、次のサーベイ論文をarXivからピックアップして、頭の整理をしています。
Shervin Minaee et al. "Large Language Models: A Survey", arXiv:2402.06196v2 [cs.CL] 20 Feb 2024
さて前回は、大規模言語モデル(LLM)とはどのようなもので、どのような主要LLMがあるか、事例とともに全体感を紹介しました。今回は、入門者であっても、LLMの構築方法の全体感をおさえておいた方が良いと考え、構築の流れの大枠を整理してみました。
LLMを構築するためのプロセスを記載します。LLMに使用されるモデルのアーキテクチャが選択されると、LLM構築のための主な手順は、次の通りとなります。

大きく分けて、LLMを構築するためのデータに関するプロセスとして、
・データの準備 (収集、クリーニング、重複排除など)
・トークン化
・位置エンコーディング
があります。
その後、モデル・アーキテクチャを選択したうえで、LLMの学習プロセスとして、
・モデルの事前学習 (自己教師あり学習方式)
・微調整と命令チューニング
・アラインメント
があります。
そして最後に、テキスト生成のプロセスとして
・デコード戦略
が挙げられます。
このように一口にLLMを構築するといっても、複数のプレセスで複雑な作業が必要となるものとなります。以下、これら各プロセスについて、概要を整理します。
データの準備
データの品質は、データ上で学習された言語モデルのパフォーマンスにとって非常に重要なものです。そのため、フィルタリングや重複排除など、データ・クリーニング手法が考えられており、それらを適切に実施できるかにより、モデルのパフォーマンスは大きく影響されます。
・データ・フィルタリング
データ・フィルタリングは、学習データの品質と学習済みLLMの有効性を向上させることを目的とするものです。一般的なデータ フィルタリング手法には次の表のようなものがあります。
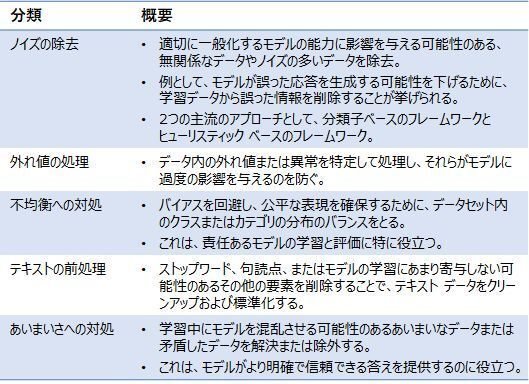
・重複排除
重複排除とは、データセット内の重複インスタンスまたは同じデータの繰り返し発生を削除するプロセスとなります。
モデルは同じ例から複数回学習する可能性があるため、データ ポイントが重複するとモデルの学習プロセスにバイアスが生じ、多様性が低下する可能性があります。そのため、特定のインスタンスでの過剰適合につながる可能性があるのです。
トークン化
一連のテキストをトークンと呼ばれる小さな部分に変換するプロセスです。最も単純なトークン化ツールは、単に空白に基づいてテキストをトークンに分割するだけですが、ほとんどのトークン化ツールは単語辞書に依存します。
辞書の適用範囲を広げるために、LLM に使用される一般的なトークナイザーはサブワードに基づいており、トレーニング データには見られない単語やさまざまな言語の単語など、多数の単語を結合して多数の単語を形成します。

位置エンコーディング
位置エンコーディングには、絶対位置埋め込み、相対位置埋め込み、回転位置埋め込みなどがあります。

モデルの事前学習(自己教師あり学習方式)
事前学習は、大規模な言語モデルの学習パイプラインの最初のステップです。LLM が基本的な言語理解能力を獲得するためのプロセスとなります。なお、事前学習中、LLMは大量の (通常は) ラベルのないテキストに対して、通常は自己教師付きの方法で学習されます。
次の文の予測などの事前学習に使用されるさまざまなアプローチがあり、最も一般的な 2 つは「トークン予測 (自己回帰言語モデリング)」と「マスクされた言語モデリング」です。

微調整と命令チューニング
事前学習された初期の言語モデルは、特定のタスクを実行できないことが多いものです。そこでこれら基礎モデルを有効にするために、ラベル付きデータを使用し、特定のタスクに合わせて微調整する必要があります。
なお、最近のLLMは、微調整を必要としないものも出てきましたが、タスクまたはデータ固有の微調整により、より性能を高めることができます。
LLMを微調整する重要な理由は、プロンプトを通じて指示を与えるときに、人間が抱くと思われる期待に応答を合わせるためです。いわゆる命令チューニング。この命令のチューニングという文脈では、命令はLLMが実行するタスクを指定するプロンプトであることを理解することが重要です。
アラインメント
AIのアラインメントは、人間の目標、好み、原則に向かってAIシステムを導くプロセスです。上述した命令チューニングにより、LLMが調整に一歩近づきますが、多くの場合、モデルの調整をさらに改善し、意図しない動作を回避するための追加の手順を含めることが重要となります。
RLHF (人間のフィードバックからの強化学習) と RLAIF (AI フィードバックからの強化学習)等の方法があります。

デコード戦略
デコードとは、事前学習されたLLM を使用したテキスト生成のプロセスを指します。入力プロンプトが与えられると、トークナイザーは入力テキスト内の各トークンを対応するトークン ID に変換します。次に、言語モデルはこれらのトークン ID を入力として使用し、次に可能性の高いトークン (または一連のトークン) を予測。最後に、モデルはロジットを生成し、ソフトマックス関数を使用して確率に変換します。
様々なデコード戦略が提案されており、最も一般的なもののいくつかは、greedy search、 beam searchのほか、top-K、top-P (Nucleus sampling) などのさまざまなサンプル手法があるようです。

効率的な学習/推論/適応/圧縮のアプローチ
ここまで、LLMを構築するための全体的な流れを紹介してきました。基本的にはこの流れで構築していくわけですが、研究開発の競争が激化するに従い、より効率的にLLMの学習を進めよう、より軽量なLLMを構築しようなどといった、新しい工夫・アプローチも出てきています。
以下に、その一般的なアプローチをいくつか紹介します。
最適化された学習
LLMの学習の最適化のためのフレームワークは数多く提案されています。以下に、代表的なものを示します。
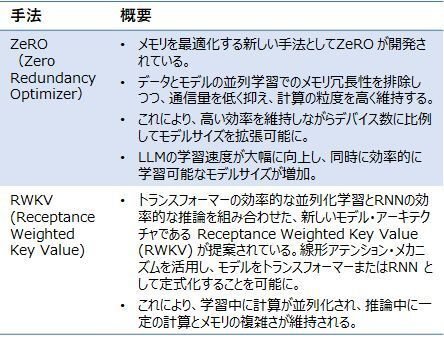
特に、RWKV(Receptance Weighted Key Value)は、トランスフォーマーの効率的な並列化学習とRNNの効率的な推論を組み合わせた、新しいモデル・アーキテクチャとして論文などで注目され、話題となりました。この論文だけだと、入門者には、LLM構築のどの部分の課題解決策なのか、いまいち、ピンとこないかと思いますが、上述したLLM構築の流れの中では、「モデル・アーキテクチャの選択」「モデルの事前学習」にかかわるアプローチであることが分かります。
低ランク適応 (LoRA)
低ランク適応は、学習可能なパラメータ数を大幅に減らす軽量学習手法を指します。低ランクの行列によって、少ないパラメータ数でモデルを適切に近似することになります。
このLoRAを使用した学習ははるかに高速でメモリ効率が高く、生成されるモデルの重みが小さく(数百 MB)、保存や共有が容易になります。
画像生成AIを使っている方はLoRAというキーワードを見たことがあるかと思います。意味も分からず見ていた…という人も多いかもしれません。
知識の蒸留(Knowledge Distillation)
知識の蒸留は、大きなモデルから、学習を行うプロセスを指します。既存の複数モデルの知識を、小さなモデルに抽出するアプローチとも呼ばれます。なお、知識は、応答の抽出、特徴の抽出、API の抽出など、様々な形式の学習によって伝達可能といわれます。
応答の抽出は、教師となるモデルの出力のみに関係し、教師と正確に、または少なくとも教師と同様に(予測の意味で) 実行する方法を生徒モデルに教えるもの。
特徴の抽出は、最後の層だけでなく中間層も使用して、生徒となるモデルの適切な内部表現を作成するもの。
APIの蒸留は、API(通常はOpenAIなどのLLMプロバイダーから提供される)を使用して、より小規模なモデルをトレーニングするプロセス。
量子化(Quantization)
モデルの重みの精度を下げ、モデルのサイズを縮小し、高速化するプロセスとなります。このプロセスは量子化と呼ばれ、様々なフェーズで適用可能です。
モデルの量子化の主なアプローチは、学習後の量子化と量子化を意識した学習に分類でき、学習後の量子化は、動的および静的という2つのよく知られた方法で量子化された、学習済みモデルに関係します。動的な学習後の量子化は、実行時に量子化の範囲を計算するものであり、静的な量子化と比較すると低速となると言われます。
量子を意識した学習は、学習に量子化基準が追加され、学習プロセス中でモデルが量子化されます。
本稿の1回のリンクと、3回の予告
【生成AI】入門者としておさえておきたい「大規模言語モデル(LLM)の現状の全体感」として、第1回はすでに公開済み。また、第3回では下記の整理をする予定です。
第1回:大規模言語モデル(LLM)とは何か
第3回:大規模言語モデル(LLM)の制限、大規模言語モデル(LLM)の使用方法と拡張方法、大規模言語モデル(LLM)の課題と今後の方向性
資料
本稿でまとめた内容をPDF形式で整理した資料を下記に添付します(有償)。大規模言語モデル(LLM)について、入門者として、全体感を整理したい方はご利用ください。
ここから先は
¥ 200
この記事が気に入ったらチップで応援してみませんか?