
「Dify」でRAG遊び!OSSを活用してワークフローを作ってみよう!

先日、XでDifyのRAG機能を使って遊んだり実験するのに、おすすめの方法を投稿したところ、想像以上の反響をいただいたので、今回はその詳細をnoteにまとめてみます!
DifyでRAG遊び・実験をするのに個人的におすすめの方法を紹介します!
— ぶんかい@AIで遊ぶ人 (@bunkaich) May 16, 2024
意外とDifyのナレッジ機能を試したいけど「そんな大量の文章データ何入れる?」みたいなことありませんか?
そこでおすすめなのが、OSSのリファレンスでRAGを構築してみる方法です!… pic.twitter.com/FvCLADWjPB
OSSのドキュメントでRAGの実験環境を作る!
Difyにはknowledgeという機能が実装されていて、大量の文章を取り込みベクトル検索DBを簡単に構築することができます。
これを使うと、最近よく見かけるようになった?RAGというシステムをDify上で構築することができます。しかも構築だけならめちゃ簡単です。
しかぁし!笑
「そもそもknowledgeに読み込ませたいそんな大量のテキストなんてみんな手元にあるかしら?」と思ったところから上記のXの投稿に至ったわけですが、反響を見るとあながち間違った仮説ではなかった?のかもしれません。
ということで、本題に入りますが、
ぼくがおすすめしたいのは、OSS(オープンソースプロジェクト)の公式ドキュメントをRAGの学習用テキストとして使う方法になります。
今回は、「Dify」の公式ドキュメント(英語)を使って、日本語で質問できるエージェントワークフローを作る手順を紹介しようと思います。
※ワークフローのDSLファイルも公開していますのでぜひお使いください。
手順を解説
手順は大きく分けて3つ!
Dify(対象のOSS)のドキュメントを一つのファイルにまとめる
Difyにknowledgeとして登録
ワークフローを構築(今回はチャットフローで実装)
1. Difyのドキュメントを一つのファイルにまとめる
ドキュメントはGithub上で「docs」みたいなディレクトリの中に「*.md」形式で各ページ作られていることが多い?みたいです。
なので、元々は、このディレクトリごとDLして、ディレクトリ内の全部の「*.md」ファイルを一つに繋げていくというPythonスクリプトを書いて一つのファイルにまとめていました。
ですが、今回noteでご紹介するにあたり、説明が増えるのでHuggingFace SpaceにGradioでUIを作って使えるようにしてみたので使ってみてください!
使い方はGithub上のdocsディレクトリまで遷移して、そのURLを赤枠のところにコピペして「Submit」を押すだけです!

たとえば「Dify」のDocsなら下記のURLです。(英語のドキュメント)https://github.com/langgenius/dify-docs/tree/main/en
(Fletってなんやねんって感じかもですが、FletのDocsなら下記のURLです)
https://github.com/flet-dev/website/tree/main/docs
そしたら勝手にGithubのリポジトリから該当のディレクトリをDLして、1つの.mdファイルにまとめてくれて右側のUI上でファイルをDLできるようになります。(たぶん動くんですが、difyとfletくらいしか試していないので他で動かないときはすみませぬ・・・)
2. Difyにナレッジとして登録
DLした「〜.md」をDifyのナレッジからアップロードします。
「ナレッジ」→「知識を作成」→「テキストファイルをアップロード」で先ほどのファイルをドラックするか、参照するかして選択して、「次へ」をクリックします。
ここからがナレッジの試行錯誤のはじまりです。
ナレッジ機能の動作は、選択した文章を細かくチャンクという単位に分けてしまうのでチャンクがうまく作れていないとそもそもナレッジとして上手く機能しません。
Difyの公式ドキュメントの場合は大体350,000文字くらいありますが、これをたとえば500文字ごとに切り分けたときに、1チャンクにはどんな情報が入るかをイメージしてみてください。
その1チャンク部分しかLLMで参照できないとしたら、どれだけの回答精度が出せるでしょうか?
精度を出すにはこの工夫が必要になってきます。
一旦今回のドキュメントファイルの場合は下記のような設定で進めてます。

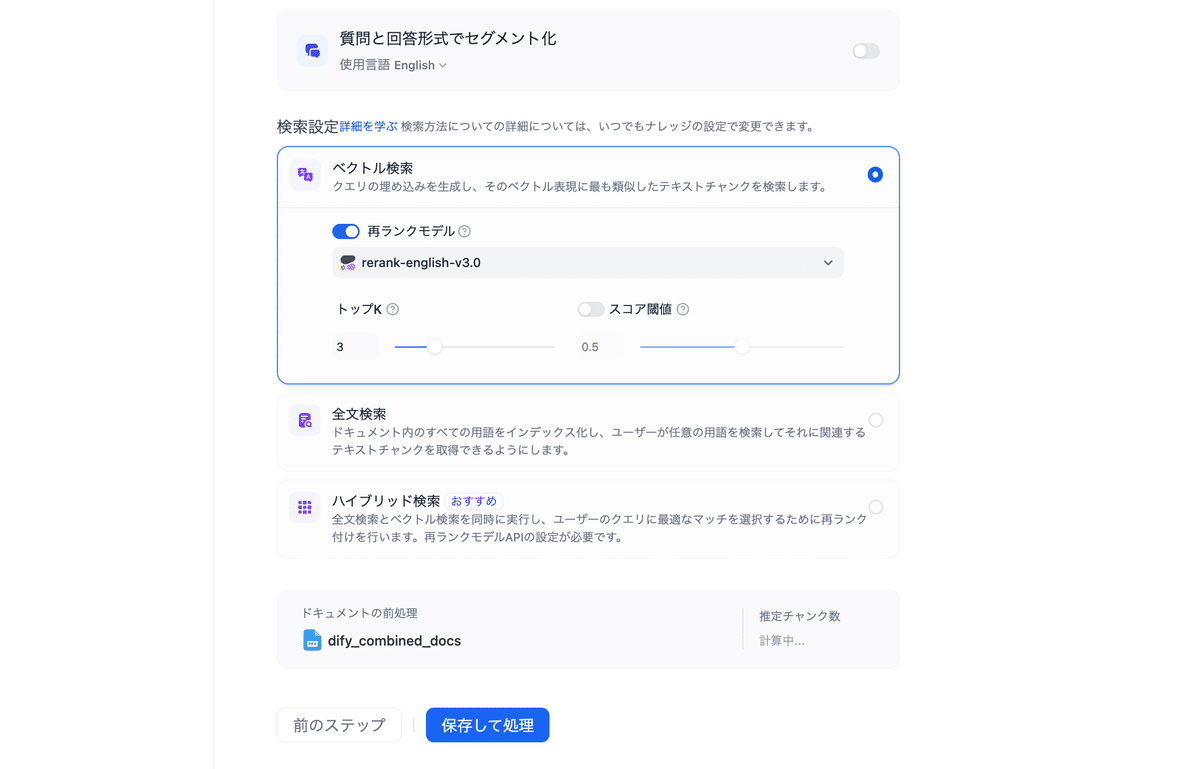
ベクトル検索の設定箇所は、cohereで無料のAPIを発行して、Difyに設定しています。
rerankの設定も使えるようにしておくことでどうしたらRAGの精度を上げられるのかを幅広く試行錯誤することができるので設定しておくと良いかと思います!
3. ワークフローを構築
いよいよ革新のワークフローをつくってきます!
といっても、Difyのワークフローは書き出してDSLファイルとして公開できるスーパーな機能がついているので下記からDLしてお使いくださいませ!
https://drive.google.com/file/d/1w8d7yyXwBfBw4GNWaFnEHxUBhRkZnueo/view?usp=sharing
なので、この章ではワークフローがなぜこの構造になっているのかを解説していこうと思います。
正直簡単な構造ですが、これからワークフローを構築しようとしている方の一助になれば幸いです!
ワークフローの流れは下記のようになってます。
(チャットフローで構築しています。)
日本語でプロンプトを受け付け
LLMで日本語のプロンプトを英語へ変換
ナレッジから検索して適切なチャンクを抽出
LLMに取得したチャンクを含めて日本語での回答を生成

OSSのドキュメントは英語なことが多いため、今回のワークフローはその想定で作っています。
ナレッジ機能では「Embedding」という技術を使って、チャンクに分割した文章をベクトルDBに保存し、セマンティックサーチ(意味検索)できるようにしています。
このEmbeddingがどういうものか素人ながらに勝手なイメージで解説しますと、膨大な言葉の意味と座標が対応している空間があって、そこにチャンクを投げ入れるとチャンクの意味に応じて、空間上の近い意味の座標付近にはりつくみたいなイメージです。(有識者の方間違っていたら指摘してください…笑)
なので、似た意味のチャンクは空間上の近い座標に集まり、意味が遠いものほど座標も離れます。
この空間にチャンクを並べてDBに保存しておく作業がDifyのナレッジの登録機能です。
そして、ユーザーが入力するプロンプトをここに投げ入れると同じくプロンプトの意味に応じて空間のどこかの座標にはりつきます。
その時に意味が近い順のチャンクを取得できるというのが意味検索の仕組みです。(Difyのナレッジ設定から取り出す個数や近さの閾値を調整できます。)
なので、意味の近さも重要ですが、文章の形が似ていることも重要で(たぶん)、そうすると英語で学習したチャンクに対して、日本語のプロンプトで検索をするよりは、英語に変換して形を似せてから検索する方が正確になる(はず)とこの形のワークフローになっています。
しかし、実際には意味で検索をできる仕組みではあるので、日本語のプロンプトで検索をしても、英語でも意味は似ていると判断できるのある程度必要な情報を取得可能でした。
今回はこういう仮説のもと、こんな組み方にワークフローならできるよー、という参考にもなるかもと思い、LLMブロックでの情報取得のための前処理をかましてみた設計になってます。
まとめ
これで、Difyやナレッジを切り替えれば英語のドキュメントを、日本語で質問できるRAGワークフローが作れます。
今回は手に入れやすいOSSのドキュメントという提案でしたが、このワークフローの構造でナレッジ部分とプロンプトを少し調整すればどんな英語の文章でも日本語で回答生成できる仕組みが作れます。
(・・・これからは当たり前になっていくのかもしれませんが、現状ノーコードでこれができてしまうDifyがやばいのです。笑)
ただ、今回採用している、「RAG」と言われる仕組みは、ナレッジから、いかに必要な情報を検索して取り出せるかが重要です。
ナレッジのチャンクをどう分割するかや、Embeddingに使うモデル、ロジック、プロンプトにどんな前処理をするか等々、試行錯誤ポイントがたくさん存在しています。
話は長くなりましたが、Xの投稿もこのnoteも、RAGにおいて重要なこの部分を試行錯誤して知見をためるために「何か良い文章データない?」という問いに、「OSSのドキュメントいいよ」と答えたいというのが結論でした。
もちろん、このワークフローは工夫次第でいかようにもできると思うのでぜひLLMブロックのプロンプト含めて精度を上げれるように改造してみてください!
そして何か良い知見があればぜひ下記のオープンチャットコミュニティでシェアいただけたら嬉しいです!!
ここからは「おまけ」の有料記事部分です。
もう今回のXの投稿部分に関することは書きたいこと書ききって、ワークフローのDSLファイルも無料部分でダウンロードできるので、ここから先は下記の目次の内容を知りたい方向け、また記事に対しての投げ銭をしてくださる方向けの「おまけ」と思って読んでいただければ幸いです_ _
おまけの目次
今回のワークフローのカスタム案(DSLファイル添付)
RAGの精度を上げる方法:過去クライアントに納品したシステムとそこでの事例、その他RAG Tips
RAGの課題(RAGにちょっと詳しくなれる話)
RAGの限界を突破する革命的な方法(RAGではなくなりますが精度めちゃでます!正直最近はこっちをメインで使ってます)
この文脈を踏まえて改めて、「Dify」の何が熱い?
ここから先は
この記事が気に入ったらチップで応援してみませんか?