
【AI×教育 論文紹介】 第2回 個別最適化学習への強化学習の応用

atama plusというAI×教育のスタートアップのアルゴリズムチームでエンジニアをしている安本@myasumotoです。
atama plusでは週に1度、世界的な技術トレンドのキャッチアップのため、「AI×教育」に関連する論文の勉強会を行っています。先日は、Deep Knowledge Tracing と呼ばれる論文を、以下noteで初めて発信しました。
AI×教育 論文紹介シリーズの第2回となる今回は、個別最適化学習への強化学習の応用について書かれている論文を複数紹介したいと思います。
論文紹介の前に、個別最適化学習について簡単にまとめます。
個別最適化学習(Adaptive Learning)とは、生徒一人ひとりの理解度・学習履歴・ミスの傾向などに合わせて、個別に最適化された学習カリキュラムを構築することで、効率的な学びを実現する学習方法のことです。atama plusが提供するプロダクトでも、AIを用いた個別最適化学習を提供しています。
ここから論文の詳細な紹介に入りますが、まず最初に、今回の論文の要点を簡単に説明します。
・強化学習とは、機械学習の手法の1つであり、タスクの目的と環境を用意すれば、明示的な教師データ(学習の手本となるデータ)がなくとも、環境との試行錯誤によって、目的達成の最適な方法を自律的に獲得できる手法である。
・強化学習には、長期的な目的を考慮できる、複数の異なる目的を組み合わせることができる、といった特徴があり、これを重要視するレコメンデーションの分野でも、近年よく使われるようになってきている(例:Youtube )。
・個別最適化学習(Adaptive Learning)の文脈でも、「短期的ではなく長期的な学力向上を目的とした出題戦略を学習させたい」、「学力だけでなく、例えばモチベーションを落とさないといった目的も含めた最適な出題をしたい」といった動機から、強化学習を使ったレコメンデーションの研究が近年行われている。
1. 強化学習
1.1 強化学習とは?
まずはじめに、強化学習についてご紹介します。
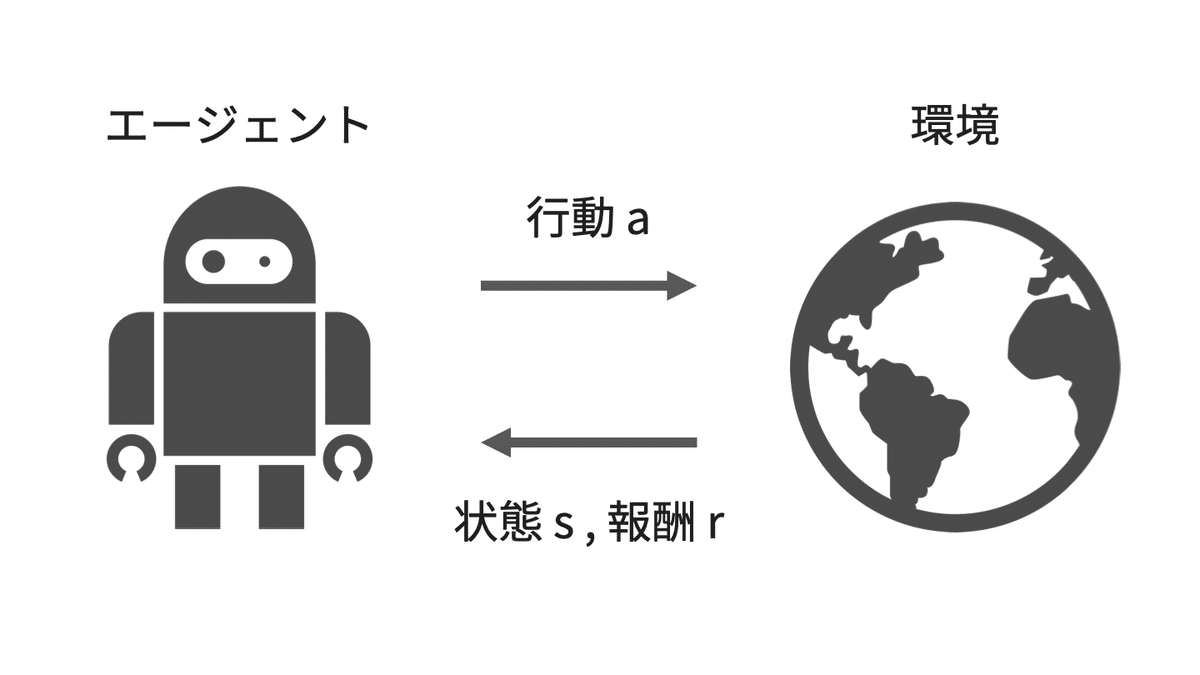
強化学習とは、エージェントが環境の中での試行錯誤を通して、よい行動方策を見つけていく手法です。ここでエージェントとは、学習の主体となるものを指します。
下の図は、強化学習の問題設定を簡単に図示したものとなります。エージェントは、現在の環境の状態($${s}$$)に基づいて、環境に対して何らかの行動($${a}$$)を行います。その結果として環境が変化し、エージェントは報酬($${r}$$)を受け取ります。
エージェントは通常、何も知識がない状態から学習を始めるため、最初はほぼランダムに近い振る舞いをし、結果として報酬を受け取ることは極めて稀です。ただその中で、たまたま報酬を受け取ることができると、そのときの行動はよい行動だった、と理解し、なるべくその行動を多くとるように行動を変えていきます。これを繰り返すことで、段々とより高い報酬を得ることができるようになっていきます。
これは余談ですが、人間の脳の一部である大脳基底核の動作は、強化学習モデルで説明できるのではないか、という研究も行われており、強化学習は人間が行う学習のアプローチに似ているとも言えます。
強化学習自体は昔から研究されている技術でしたが、近年、深層学習と組み合わせることで、解くことができるタスクの幅が大きく広がり、再度注目を集めるようになってきました。具体的には、状態として画像等の高次元情報を受け取ることができるようになり、エージェントがゲームの画面を見てプレイしたり、カメラからの情報をもとにロボットアームを制御したり、といったことができるようになってきています。
また、強化学習はレコメンデーションの分野でも応用されはじめています。Youtubeでは、お勧めの動画を提案するアルゴリズムに強化学習を使う研究を行っています。国内でも、ZOZO研究所にて、強化学習の1手法であるバンディットアルゴリズムを使った推薦アルゴリズムの研究が行われています。
レコメンデーションにおける強化学習の問題設定を簡単に図示したものが下図となります。エージェント、環境には、それぞれレコメンドシステムとユーザが対応します。レコメンドシステムは、ユーザの行動履歴(これまでの購買履歴やページ遷移履歴)をもとに、ユーザに対してアイテムを推薦します。その結果、ユーザが商品を購入すると、それが報酬となってレコメンドシステムの学習に使われます。

このように、強化学習の問題設定は様々なドメインに適用することが可能です。
1.2 Adaptive learningにおける強化学習
強化学習の問題設定をAdaptive Learningのドメインに適用した場合の一例が下図です。
エージェントと環境には、それぞれAdaptive Learningシステムと生徒が対応します。Adaptive Learningシステムは、例えば生徒の回答履歴といった情報をもとに、次にどの問題を出題すべきかを決定し、生徒に出題します。報酬は様々なパターンが考えられますが、例えばある時点で、これまでに学習した内容の確認テストを実施するとして、その時の点数を報酬として設定します。
この問題を解くことで、Adaptive Learningシステムは、確認テストでの点数が上がるように、適切な問題を出題できるようになることが期待されます。

Adaptive Learningにおける強化学習の問題設定は、前述したレコメンドシステムにおける問題設定と類似しているため、レコメンデーションの分野における知見を活かしやすいと考えられます。
1.3 強化学習の特徴
強化学習の特徴はいくつかありますが、ここではAdaptive Learningのドメインにとって特に重要と思われる、以下の2つの特徴について説明します。
(1)長期的な目的を考慮できる
強化学習では、行動をして報酬が得られた場合に、その行動を多くとるように学習する、と説明しました。では、この報酬がすぐに得られるのでなく、時間差をつけて得られるような場合はどうなるでしょうか。
強化学習では、このような時間遅れのある報酬にも対応できることが知られています。将来得られる報酬をどの程度考慮するか、というのを割引率で設定することができ、この値を高くすると、将来得られる報酬をより考慮して学習できるようになります。
例えばYoutubeでは、刺激的で人を一時的には惹きつけるような動画を推薦しておけば、ユーザの一時的な滞在時間は長くなるかもしれません。しかし、それでは長期的に見たときにユーザーの離脱が発生する確率が高まる可能性があるため、長期的な視野に立ったレコメンドが求められます。
Active Learningを例に考えてみましょう。例えば、常に新しい学習内容を生徒が学習していく場合、そのうち過去に学習した内容を忘れてしまい、最終的なテストの時には、最初の方に学習した内容をすっかり忘れてしまう、ということがあるかもしれません。知識を確実に定着させるためには、既に習得した内容の復習も織り交ぜていく必要があります。
強化学習を使うと、最終的なテストの点数を報酬として設定すれば、その時点での学力が最大となるように、予習と復習をうまく混ぜて出題することが可能になると期待できます。

(2)複数の目的を考慮できる
強化学習の問題設定に登場した報酬は、関数として自由に記述することができます。よって、例えば1つの目的だけでなく、複数の目的を組み合わせて1つの報酬関数として定義することができます。
Active Learningでは、一般的に最も優先度が高い目的指標はテストの点数ですが、それ以外にも、長期間にわたる持続的な学習習慣を身につけることが大事なのでれば、生徒のモチベーションといったものも報酬として加えることができます。
2. 論文紹介
それでは、1.3で紹介した強化学習の特徴を踏まえながら、Adaptive Learningに強化学習を適用した論文を3本紹介していきます。
Accelerating Human Learning with Deep Reinforcement Learning
Exploring Multi-Objective Exercise Recommendations in Online Education Systems
2.1 Accelerating Human Learning with Deep Reinforcement Learning
この論文では、強化学習の特徴1.3(1)で紹介した、新しい分野の学習と、既習分野の復習を、適切な割合・スケジューリングで出題する、という目的のために、強化学習がどの程度使えるかを実験しています。
まず、人間の記憶を、心理学などの分野で提唱された3つのモデルを使ってモデル化します。次に、これらのモデルをシミュレートするシミュレータを使って強化学習を行い、既存の従来手法と比較して、強化学習がどの程度パフォーマンスを発揮できるか、実験しています。
ここでは、記憶モデルのうちの1つである、Exponential Forgetting Curveについて紹介します。これは、人間の記憶モデルの1つで、以下の式で書くことができます。
$$
Z \sim \mathrm{Bernoulli} \left( exp \left( -\theta\cdot\frac{D}{S} \right) \right)
$$
ここで、$${θ}$$はアイテムの難易度、$${D}$$は最後に解いたときからの経過時間、$${S}$$は生徒の記憶の強度で、この論文ではこれまでに問題を解いた回数として定義しています。
強化学習の実験設定は、生徒の状態は、前回出題した問題に正解したか否かの2値、生徒に対して行う行動は、n個ある問題のうちどれを出題するか、報酬は、その時点で、n個ある問題のうちいくつに正解できるかと定義しています。
結果は下図のようになっており、黄色のTRPOと書かれている線が強化学習、Leitner、SuperMemoと書かれている線が既存のアルゴリズム、Randomがランダムに出題した場合、Thresholdはアルゴリズムで達成可能な上限値を表しています。これを見ると、3つのモデルのいずれにおいても、既存の手法とほぼ同等、あるいはそれを上回るパフォーマンスを達成できていることが分かります。

2.2 Exploiting Cognitive Structure for Adaptive Learning
この論文では、強化学習の特徴1.3(1)で紹介した、長期的な目的を考慮する、という点を利用しています。
Adaptive Learningシステムは、生徒に対して問題を連続して出題します。その中で、ある一定の間隔で試験を実施し、試験のスコアの向上幅を報酬として用います。
より詳しく説明すると、下図に示すように、最初の試験のスコアが$${E_s}$$だったとして、何回か問題を解いた後($${p_1}$$〜$${p_n}$$)、再度試験を受け、そのスコアが$${E_e}$$だった場合、向上幅$${E_\mathcal{P}}$$は下の式で定義されます。ここで$${E_{sup}}$$は、試験で取り得る最高得点を表します。

$$
E_\mathcal{P}= \frac{E_e - E_s}{E_{sup} - E_s}
$$
詳細な実験内容は省略しますが、2種類の異なる方法で構築された生徒シミュレータ(KSS、KES)を用いて、再試験後の成績向上幅$${E_\mathcal{P}}$$を評価した結果が下図となります。いずれのシミュレータでも、この論文で提案された手法「CSEAL」が、既存手法を上回る性能を達成していることが分かります。

2.3 Exploring Multi-Objective Exercise Recommendations in Online Education Systems
この論文では、強化学習の特徴1.3(2)で紹介した、複数の目的を考慮する、という点を利用しています。
具体的には、①Review & Explore、②Smoothness、③Engagementの3つの報酬関数を定義し、最終的な報酬関数はこれらの線形和として定義しています。
①Review & Explore
既に解いた問題の復習(Review)と新しい問題の探索(Explore)はトレードオフがあり、うまくバランスをとる必要があります。
1つ前の問題に間違えた場合は、次はなるべく同じ種類の問題を出すようにすべき、という復習の観点($${\beta_1}$$)と、新しい種類の問題を出題するようにすべき、という探索の観点($${\beta_2}$$)の2つの目的指標で報酬を構成し、それぞれの係数を調整することで、このトレードオフを調整できるようにしています。
$$
r_1=\begin{cases}\beta_1 & \mathrm{if} \quad p_t = 0 \quad \mathrm{and} \quad k_{t+1}\cap k_t = \emptyset, \\ \beta_2 & \mathrm{if} \quad k_{t+1} \backslash \left\{ k_1 \cup k_2 \cup \cdots \cup k_t \right\} \neq \emptyset, \\ 0 & \mathrm {else.}\end{cases}
$$
②Smoothness
生徒の知識習得は一般的に段階的なものであるため、問題を連続して出題する際には、そのレベルがなだらかに変化した方が望ましいと考えられます。
そこで、連続する2つの出題のレベル差(下図では$${d_t}$$、$${d_{t+1}}$$に相当)が極力小さくなるように、その差の小ささを報酬として定義しています。
$$
r_2 = \mathcal{L}\left( d_{t+1}, d_t\right) = -\left( d_{t+1} - d_{t} \right)^2
$$
③Engagement
生徒が常に楽しく問題を解いていられるというのは、学習において重要な要素の1つです。
例えば下の図は、あるレコメンデーションの例を示していますが、図中のJohnとEricは、レコメンドの結果に退屈しています。Johnにとっては「Set」の分野の問題が難しすぎるため、1つも問題に正解できず、一方Ericにとっては、どの問題も簡単すぎて全て正解できてしまうため、2人ともモチベーションが下がってしまったのです。
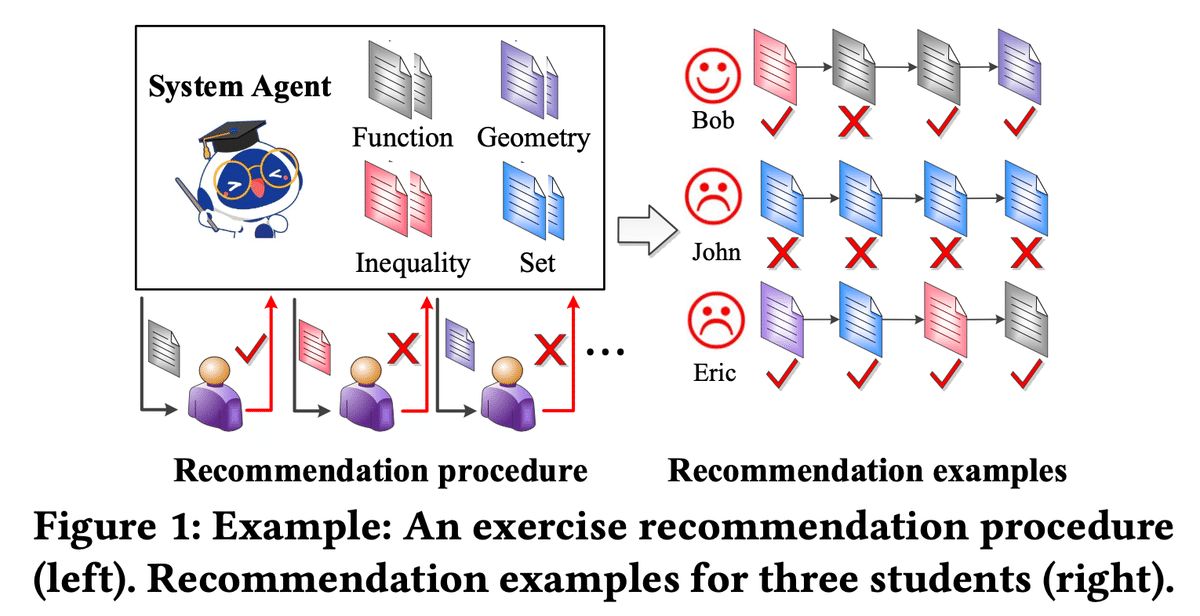
この例が示すように、簡単すぎる、あるいは難しすぎる問題の出題は、生徒のモチベーションの低下に繋がります。
そこで、正解が連続している生徒には少し難しい問題を、不正解が連続している生徒には少し簡単な問題を出すことで、Engagementを高めるための報酬を以下のように定義します。ここで$${g}$$は学習のゴールと呼ばれる要素で、生徒自身あるいはコーチによって設定されるものです。この報酬があることで、設定した$${g}$$の値に基づいて難易度が調整されます。
$$
r_3 = 1 - \left| g - \varphi \left(u, N \right) \right|, \quad \varphi \left(u, N \right)=\frac{1}{N}\sum_{i=t-N}^t p_i
$$
実験では、生徒のシミュレータを構築した上で、まずランダムに出題する場合(図中のRGに対応)と比較して、提案手法(図中のDRERに対応)が、より多い報酬を獲得できることを示しました。また、①〜③のそれぞれの報酬のみを入れた場合を比較し(図中のDRER-r1〜r3に対応)、結果として、①の報酬の影響が最も大きいことも分かりました。

また、①〜③の報酬が正しく機能しているかの実験も行っています。
①のReview & Exploreの報酬については、探索の係数(β2)の値を大きくすることで、問題として出題される概念のカバー率(図中縦軸のConcept Coverageに対応)の向上スピードが増加することが分かり、期待通りの動作をしていることを確認しています。

③の報酬については、$${g}$$(学習のゴール)の値を変化したときに、出題される問題の難易度がどう変化するかと、それに対して生徒の正誤がどう変化するか(黒色の点が正解、赤色の点が不正解を表す)を可視化しています。
$${g}$$を小さくすると難易度の高い問題が出題され、それに伴い生徒の正答率が下がり、$${g}$$を大きくすると難易度の低い問題が出題され、それに伴い生徒の正答率も高くなることから、③の報酬が期待通りの動作をしていることが確認できます。また、全体を通して難易度が劇的には変化していないことから、②の報酬が作用していることも確認できます。

3. 所感
レコメンデーションにおける強化学習の活用は昨今のトレンドであり、Adaptive Learningの文脈でも強化学習の特徴を活かした利用が行われていくのは自然な流れのように思えました。
一方で、多くの論文がモデルフリー強化学習のアプローチを採用しているため、レコメンドの精度はシミュレータの精度に大きく依存すると思われます。シミュレータの構築には、モデルベースや、データドリブンな方法がとられていますが、これらのシミュレータが現実世界とどの程度整合しているかは、実践的な観点からは課題になるだろうなと思います。
長期的な目的を考慮すべきといった点や、複数の目的を考慮すべきといった課題感については納得することも多く、手段を強化学習に限らずともこれらの課題について取り組んでいくことは、学習体験をより効率的・効果的・魅力的にしていくためには重要と感じました。
おわりに
atama plusでは、蓄積されるデータを基に、生徒の学習体験を日々改善しています。もし少しでも興味がありましたら、ぜひ一度お話させて下さい。
ご応募お待ちしております。