
Day4_経営判断と予測モデル・SUNABACO「AI人材育成講座」【備忘録】

※今回は質問フェーズのまとめは飛ばします。
というか、そこを書いているだけの僕の余力がありまへんでした。
内容はある程度、まとめていますが、誤りなどあったらごめんなさい!
(いつもよりもモデルのあたりで僕の理解が追いつかなかったです)
経営判断の集合体としての業務
判断の積み重ねが生む業務の本質
カンパ先生が語った本日の始まりは、「業務をどうやって数値化していくのか」というテーマ。
紹介された『ファスト&スロー』(後述で簡単に解説)には、「組織は意思決定を生産する工場である」という言葉があり、それを引用。
つまり業務の基本とは船の舵取りのような、さまざまな要因に対する判断の集合体なのです。
ビジネスという荒波の中で、人や組織は常に岐路に立ち、進むべき航路を選んでいます。時には逆風を受けながらも、成功と失敗を繰り返すことで、その航路は徐々に明確になり、知見という名の羅針盤が生まれる言えるでしょう。
しかし、この羅針盤が指し示す方向は常に一定ではありません。海の状況が刻一刻と変わるように、判断のための因子は絶え間なく出現し、その都度、新たな選択を迫られます。
因子の複雑さが経営判断を難しくする
現代のビジネス環境では、判断材料となる因子が嵐の中で舞う無数の落ち葉のように次々と現れては消えていきます。その中から適切なものを選び、正しい方向へと舵を切ることは、極めて難しい作業と言えるでしょう。この因子の多様さが、経営判断の難しさの核心なのです。
たとえば、顧客の動向や市場の変化、競合の動き、新たな技術の進展など、すべての要素が経営者の前に立ちはだかる考えれば分かります。これらの因子が生み出す情報の洪水の中で、正確な判断を下すことは容易ではありません。
ビジネスの基本方程式である「顧客数 × 購入頻度 × 単価」の各項を良化させるためには、膨大な選択肢の中から最善の手を打たなければなりません。この方程式は一見シンプルですが、その背後には深遠な思考と高度な判断力が隠されています。
プロ経営者の頭脳内の戦い
ここで考えてみてください。
プロの経営者たちは、この複雑な情報の渦の中で、どのようにして瞬時に適切な判断を下しているのでしょうか。
彼らの思考は、チェスの名人が次の一手を考えるように、膨大な可能性の中から最善の選択肢を見出す過程に似ています。その頭脳内では、経験と直感、知識が絶え間なく交錯し、最適な道筋を模索していると言えるでしょう。
たとえば熟練の経営者は一つの情報がもたらす影響を瞬時に計算し、それを基に次の一手を決定します。これが、初心者には決して真似できない、プロならではの技です。
経営の世界では、単なる論理的な計算だけでなく、過去の経験からくる直感や洞察も重要な役割を果たすのです。
AIがプロ経営者の思考を学ぶとしたら
では、もしAIにこのプロ経営者の思考を学ばせたらどうなるのでしょうか。
AIは、無限のデータを処理し、パターンを見出す能力に優れていますが、その判断がプロ経営者のように的確であるかは未知数です。
AIが経営者の経験や直感に基づく思考を学習することで、彼らと同等の判断力を持つことができるのか、それとも人間にはできない新たな次元の判断力を発揮するのか。それは興味深いテーマと言えるでしょう。
AIにプロ経営者の思考を学ばせる試みは、単なる技術の進化ではなく、経営の本質に迫る挑戦でもあります。最適な判断をするための因子を見極め、それに基づく最善の選択を迅速かつ的確に行う。このプロセスをAIがいかにして再現し、そしてどのように発展させていくのか。
これは、ビジネスの未来を左右する大きな問いとなります。
人類の知恵と機械の力が融合することで、新たな可能性の扉が開かれるのか、それとも未知の課題が立ちはだかるのか──その答えを見つける旅は、まだ始まったばかりなのかもしれません。
『ファスト&スロー(原題:Thinking, Fast and Slow)』
『ファスト&スロー(原題:Thinking, Fast and Slow)』は、ノーベル経済学賞を受賞した心理学者ダニエル・カーネマンによる著書で、私たちの「思考」について深く掘り下げた内容が特徴です。
この本は、人間の意思決定や判断に関する科学的な研究を基に、私たちの思考がどのように働くのか、特に「速い思考」と「遅い思考」の二つのシステムについて説明しています。
僕はこの本がとても好きで数周していますが、実は5年ほど前まで「ファスト&スロー」ではなく「ファスト&フロー」だと思っていました。よく考えればそのタイトルが変だというのは分かりますが、気付かずに人にもその名前で紹介していたのを今でも恥ずかしく思います。思い込みと先入観、まさにファスト&スローのファスト(作中におけるシステム1)に委ねていた事実に「ハッ」と気付かされた瞬間でした。
閑話休題。
では読んでいない方や忘れてしまった方に向けて少し解説。
思考の二つのシステム
カーネマンは、人間の思考プロセスを「システム1」と「システム2」の二つのシステムに分けて考えます。
システム1(ファスト)
システム1は、自動的で素早く働く直感的な思考です。意識的な努力を必要とせず、反射的に物事を処理します。これは日常生活の中で私たちがよく使う思考方法であり、例えば道を歩く時の注意、顔の表情から相手の感情を読み取ること、簡単な計算をすることなどに使われます。システム1は即座に反応し、ほとんどの場合において正確な判断をしますが、その反面、誤りを犯すことも多いのが現実です。特に偏見やステレオタイプに基づいた判断が典型的なミスの一例と言えます。システム2(スロー)
システム2は、ゆっくりで意識的な思考であり、論理的な分析や複雑な計算、慎重な意思決定に関わります。これは、注意を集中させ、意識的に考える必要がある場面で使われます。たとえば、仕事での戦略的な計画の立案、数学の問題を解く、重要な決断を下すときなどに機能します。システム2は、より正確で理性的な判断をするために不可欠ですが、その反面、エネルギーを多く消費し、疲れやすいという欠点があります。
システム1とシステム2の相互作用
『ファスト&スロー』では、私たちの日常の多くの判断がシステム1によって行われていること、そしてシステム2がその判断を監視し、必要に応じて介入するという仕組みが描かれています。しかし、システム2は怠け者であり、エネルギーを節約しようとするため、しばしばシステム1の直感的な判断に依存しすぎることがあります。この依存が、誤った意思決定や判断の原因となるのです。
僕が「ファスト&フロー」だと思い込み、そのタイトルの違和感に気付けずにそのまま脳死で人様に紹介し続けていたのもシステム2のサボりのせいということです(いや、それはオマエがバカなだけだろとは言わないで)。
ヒューリスティクスとバイアス
カーネマンはまた、「ヒューリスティクス」と呼ばれる直感的なルールやショートカットが、どのようにして人間の意思決定を助けるかと伝えています。その一方で、誤った判断やバイアス(偏り)を生むのかについても説明しています。たとえば、次のようなものが挙げられます。
アンカリング効果
最初に提示された情報(アンカー)が、後の判断に強く影響を与える現象。例えば、価格交渉で最初に提示された額が、最終的な合意額に影響を及ぼすことがあります。利用可能性ヒューリスティクス
人は自分が思い浮かびやすい情報に基づいて判断を下しがちであるという現象。例えば、最近ニュースで見た事件の印象が強ければ、それがその出来事の頻度や危険性に対する判断に影響を与えることがあります。代表性ヒューリスティクス
ある事象がどれほど典型的か、どれほど「代表的」に見えるかによって、確率や頻度を判断する傾向。たとえば、特定の服装をした人を見て、その人の職業を推測する際にステレオタイプに基づいた判断をすることがあります。
認知的な錯覚と限界
カーネマンは、私たちがどのようにして錯覚に陥るのか、またそれがどのように私たちの判断に影響を与えるのかを解説しています。人間の脳は複雑な状況を単純化する傾向があり、それによって誤った結論に達することがあります。
例えば、リスクの高い投資やギャンブルにおける「直感的な賭け」などが挙げられます。「儲かる」という短絡的な情報から判断を下してしまう事実を皆様も一度は経験しているでしょう。
これらはシステム1の典型的な罠であり、システム2の慎重な分析が介入しない限り、容易に誤った道に進んでしまいます。
『ファスト&スロー』の意義
この本は、人間の思考がどのように働き、なぜ私たちがしばしば間違った判断をしてしまうのかを理解するための重要な手がかりを提供しています。カーネマンは、これらの思考の罠を知ることで、より良い意思決定を行い、バイアスを避ける方法を学ぶことができると主張しています。
『ファスト&スロー』は、私たちの思考の仕組みを理解するための優れたガイドであり、ビジネスや個人の生活においても応用できる洞察を提供します。カーネマンの研究は、私たちの認知の仕組みがいかに驚くほどの能力を持つ一方で、いかに簡単に誤解や錯覚に陥るのかを示しており、その理解があなたの未来の判断をより良いものにするための鍵となるでしょう。
人間の限界とAIが拓く新たな可能性
人間の限界・複雑さに飲み込まれる判断力
カンパ先生は現代のビジネス環境では、多くの因子が絡み合い、それらを全て見通すことは難しいと言います。人間の脳は、限られた情報を同時に処理するように設計されていますが、それを超える情報が与えられると、混乱し、判断が曖昧になってしまいます。
例えば、画面上に点を増やしていくとします。
最初の1つ、2つ、3つまでは直感的に数を把握できますが、4つを超えた瞬間から、私たちは直感での認識を失い、点を数えるというプロセスが必要になります。
この現象は、私たちの脳の限界を示しており、複雑な要素が増えるほど、それをフラットに、バイアスなく見ることが難しくなることを教えてくれます。
AIの力・複雑な因子を整理し、最適な選択を支援する
こうした人間の認識の限界を補うのがAIの力です。
カンパ先生は、AIが膨大なデータを集め、複雑な決定因子を解析し、最適な選択を支援するツールとして機能できると述べています。
AIは何万、何百万ものデータポイントを一度に解析し、人間には不可能なほどのスピードで適切な判断の道筋を見つけ出すことができます。
例えば、経験の少ない人がプロの経営者のような高度な判断を求められるとき、AIはそのギャップを埋めるための架け橋になります。
AIが蓄積したデータと学習アルゴリズムによって、高い経験値と知見を持つ人の判断を模倣することが可能になるのです。これは、ただ教育や話を聞くだけでは身につけられない領域であり、実際の判断をトレースすることでしか得られないものです。
達人の領域、失敗と成功の積み重ね
カンパ先生は、達人の領域とは単なる天才の産物ではなく、過去の失敗と成功を重ねた結果だと指摘しています。
経験を重ねることで得られる知見や直感的な判断は、一朝一夕で手に入るものではありません。しかし、それをAIのアルゴリズムに落とし込むことで、初心者でも達人の知見を活用できるようになります。
これは熟練の陶芸家が長年の経験で得た手の感覚を、初心者に教えるようなものです。本来なら歳月をかけて学び続けて会得する知見と言えるでしょう。
しかし、AIを使えば、その伝授が瞬時に行われる可能性があります。陶芸家の手の感覚をデータとアルゴリズムの形で保存し、それを用いることで、初心者が即座にプロの技術を使用することが可能になるのです。
勿論、使用するだけで、初心者本人の陶芸技術が飛躍するという意味ではありません。
但し、この点もAIと機械という相乗の進化が用いられれば、陶芸用システム手袋といったドラえもんの秘密道具のようなものが完成する可能性もゼロではありません。
新たな可能性とAIがもたらす知見の民主化
AIがプロ経営者や達人の知見を学ぶことで、経験の少ない人々でも高度な判断力を持てるようになります。
これは単なる技術的な進歩ではなく、知見の民主化とも言えるものでしょう。かつては少数の人だけが持っていた特別な能力が、AIを通じて誰でも使えるようになるのです。
「AIは人類の新しい仲間であり、複雑さを解決するパートナーです」とカンパ先生は述べています。
この言葉は、私たちに新しい未来の可能性を示しています。
複雑な問題に直面するとき、AIと人間が協力することで、今まで見えなかった解決策が見つかるかもしれません。過去の経験とAIの力が融合することで、新しい知見と革新が生まれるでしょう。
AIと人間の協働が生み出す新たな知見
AIの学習の本質、それは人間の判断を模倣すること
AIの本質を「人間が行う決定木の判断を学習させること」と位置づけてみます。
決定木(けっていぎ、英: decision tree)は、(リスクマネジメントなどの)決定理論の分野において 決定を行うためのグラフであり、計画を立案して目標に到達するのに用いられる。 決定木は、意志決定を助けることを目的として作られる。 決定木は木構造の特別な形である。

AIは優れた決断者の思考プロセスを模倣し、それをもとに判断を行います。
たとえば、優秀な医者の選択や診断のパターンを学び、その判断を効率的に再現することで、診断のスピードと精度を向上させるというものです。
AIの学習は、これまで人間が経験を通じて培ってきた知識と直感をデータの形で取り込み、それを用いることで、人間の意思決定をサポートすることを目指しています。
優れた人の判断力とAIの補完的役割
しかし、カンパ先生はまた、「優れた船長ほど自動航路システムを鵜呑みにしない」とも語っていました。
AIがいかに優れていても、すべての判断を任せるわけにはいかないということを意味しています。真に優れた人間ほど、AIの判断を絶対視せず、常に自らの経験と知識でそれを検証する姿勢を持っています。
AIが提供する判断をそのまま受け入れるのではなく、優れた人間はAIがどこで間違えたのか、あるいはどこで判断が不十分であったのかを見極めることが可能です。このプロセスを通じて、AIはさらに学習し、強化されていくでしょう。
AIは人間の判断を模倣するだけでなく、より優れた判断を行うための手助けをするために、人間の批評的な視点を必要としているのです。
AIと人間の共進化と互いに高め合う未来
このような人間とAIの協働は、単なる補完的な関係にとどまらず、互いに高め合う「共進化」のプロセスを生み出します。
優れた人間がAIを使い、その結果として得られるフィードバックがAIの学習を強化することで、AIはさらに進化していくでしょう。
例えば、ある医者がAIの診断結果に対して異議を唱え、それが間違いであると判明した場合、AIはそのフィードバックをもとに次の診断で同じ間違いをしないよう学習することが出来ます。
同様に、優れた船長が自動航路システムの予測に疑問を持ち、自らの経験を基に判断を下すことで、AIの航路予測モデルがより精度の高いものへと改善されていきます。
但し、こういった優秀な人材が常に「AIの強化」を良しとするのかには疑問を挟む余地があるのかもしれません。
言ってみれば「自分の商売道具」を他に明け渡す可能性を示唆しているからです。この辺りの議論は今後も加熱していくことになるでしょう。
人間の直感と経験がAIを育てる
この優秀な決断者からさらに学んでいくプロセスを通じて、AIはただの道具ではなく、卓越した人間の知見と直感を取り込み、さらに強化される存在へと変貌していきます。
AIは「どこで間違えたのか」を学び続け、より正確な判断を行えるようになります。これは、AIが人間の経験と知識を吸収しながら進化していく姿を示していると言えるでしょう。
ある種、人間は拙いプライドを持ち、時に優秀な決断者の判断に対しても「オレの方が正しい」と意固地になることもあります。それらを踏まえると「間違いの修正」の能力はAIの方が圧倒的に優れているのかもしれません。
結局のところ、AIは人間の知識を学び、その知識に基づいて最善の判断を行おうとしています。
よって、最も重要な工程はその判断が絶えず人間によって評価され、フィードバックを受けることにあるのです。
AIが真に力を発揮するのは、優れた人々がその使用を通じて、AIの限界を見極め、改善を促すときであると言っても過言ではありません。こうしてAIと人間の協働によって、新たな知見と可能性が生まれるのです。
AIにおけるモデルの本質 — いずくね先生から学ぶ
現在は生成AIという言葉が飛び交い、誰もがその潜在的な可能性について話しています。今回の講義は「AIにおけるモデル」という概念について、いずくね先生の視点を通して学んでいくことになります。
AIの本質とその実装の重要性を探っていきましょう。
AIのモデル化とは何か?
これまでAIを「何かを入れると、何かが出てくる」箱のように考えるように伝えてきました。
たとえば、「赤」というデータを入れると、「合格」という結果が出てくるようなものです。
これをより専門的に説明すると、入れる側の情報(「赤」などのデータ)を「説明変数」と呼び、出てくる結果(「合格」などの出力)を「目的変数」と呼びます。
そしてAIのモデル化とは、現実の問題を解決するために、データを因子(説明変数と目的変数)に分解し、その関係性を理解するための数学的なルールやアルゴリズムを構築することです。
このプロセスでは、まずデータを収集し、AIが学習できる形に整える前処理を行います。
次に、データからパターンを見つけるための”モデルを選び”、トレーニングを通じてモデルが精度よく予測や判断を行えるようにします。
モデルが十分に正確であれば、実際の問題に適用し、よりよい意思決定を支援することが可能です。
AIのモデル化は、データの特定の要素を分析し、それに基づいて最適な予測を行うための仕組みを作ることで、複雑な現実の問題解決に役立ちます。
モデル化とは汎化を意味する
先のプロセスを「モデル化」と呼びますが、その本質は「汎化」にあります。
汎化とは、特定のデータセットに基づいて一般的なルールを見つけ出すことです。しかし、汎化のアプローチにはいくつかのパターンがあり、正誤判断の方法もそれぞれ異なります。
例えば、あるAIモデルは「大きいリンゴは甘い」と結論付けるかもしれませんが、別のモデルは「赤いリンゴは酸っぱい」と予測するかもしれません。どちらのモデルが正しいかは、データの質や量、さらにはその利用目的によって変わってきます。
AIの実装は自然な変化の中で
AIのモデル化がどれほど優れていても、それを現実の作業に組み込むことができなければ、その価値は半減します。
いずくね先生は、AIを実装する際には「作業の中に自然と組み込まれるようにする」ことが重要であると述べています。これは、AIの導入が「変化」として認識されない状態を目指すということです。
人は変化にエネルギーを要し、時にそれを拒むこともあります。だからこそ、AIが「知らぬ間に入っていた」ような形で導入すること、あるいは「それなしでは先に進めない」ような不可欠なツールとして位置づけることが重要だと語られています。
AIは道具、それとも仲間?
結局のところ、AIはただの道具であるのか、それともあなたの仕事や生活を支える新たな仲間となり得るのか。
それは、どのようにAIを理解し、実装するかにかかっています。
いずくね先生の考えは、AIをもっと身近で使いやすいものにするための一つのアプローチを示唆しています。彼の視点を通して、AIと共存する未来をより明確に描けるのではないでしょうか。
AIの世界を理解する | 回帰と分類
私たちが日々目にするデータには、無数の物語が隠れています。
それらのデータは、一見するとランダムで無意味な数字の羅列に見えるかもしれませんが、AIの技術を用いることで、そこから驚くべき洞察を引き出すことができます。
データの解読には「回帰」と「分類」という二つの主要な手法があり、これらの手法がどのように機能し、どのように使い分けられているのかを見ていきましょう。
回帰 — 未来を予測する直線
回帰は、連続する数値を予測するための方法です。
例えば、不動産の価格を予測する際に、過去の取引データを基に未来の価格を見積もる方法として使われます。
過去のデータ点を図にプロットし、それらをつなぐ「直線」を引くことで、未来の傾向を予測することが出来ます。この直線を引く手法を「線形回帰分析」と呼びます。回帰では、データの傾向やパターンを見つけ出し、それを基に将来の予測を行います。
分類 — データを分ける羅針盤
分類は、あるデータがどのグループに属するかを予測する方法です。
例えば、受信メールが「スパム」か「重要なメール」かを判別するスパムフィルタリングがその例です。分類は、データを仕分けるための「羅針盤」のような役割を果たします。
いくつかの分類手法には次のようなものがあります。具体例も記載しますが、実際に使えるかは自己判断で思考をお願いします。
また本来僕は「noteに講座スライドは使わない」を原則としていますが(自分の理解の範疇が明確にならないという理由)、今回は理解が及ばない部分もあり使っています、ご了承のほど。
決定木分析(Decision Tree Analysis)
意味: 決定木分析は、データの特徴に応じて「木」のように枝分かれしながら分類や回帰を行う手法です。データの中で最も重要な特徴を見つけ出し、それを使って予測や分類を行います。
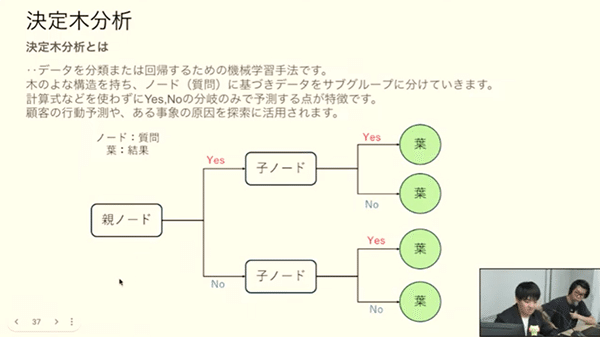
決定分析が使用可能だと考えられる具体例:
顧客セグメンテーション: 顧客の年齢、収入、購入履歴などに基づいて、どの商品を薦めるべきかを決定する。
医療診断: 患者の症状(発熱、咳、血圧など)を基にして、病気の種類(風邪、インフルエンザ、肺炎など)を判定する。
人材採用: 求職者の履歴書データ(学歴、職歴、スキル)に基づいて、どのポジションが最適かを判別する。
詐欺検出: クレジットカードの取引データを使用して、不正取引の兆候(異常な取引金額、場所、時間など)を検出する。
マーケティングキャンペーンの最適化: 顧客の過去の反応に基づいて、どのような広告やプロモーションが最も効果的かを予測する。
ランダムフォレスト(Random Forest)
意味: ランダムフォレストは、複数の決定木を組み合わせて、より正確な予測を行う手法です。各決定木が異なるデータのサブセットで学習し、その結果を統合することで、予測の精度を高めます。

ランダムフォレストが使用可能だと考えられる具体例:
株価予測: 過去の市場データや経済指標を基にして、将来の株価の動向を予測する。
患者のリスク評価: 医療データ(年齢、既往症、生活習慣など)を基にして、特定の疾患にかかるリスクを評価する。
製品需要予測: 小売業で過去の販売データを使用して、次の四半期の製品需要を予測する。
クレジットリスク評価: 顧客の信用スコアや履歴に基づいて、融資のリスクを評価する。
音声認識: 音声データを分類し、話者の声を識別するシステムで、言語モデルの構築に使用される。
SVM(サポートベクターマシン)
意味: SVMは、データを異なるグループに分類するための手法で、データの間に最適な境界線を引いて、それを基に分類を行います。特に、分類精度が高いモデルとして知られています。

SVMが使用可能だと考えられる具体例:
画像認識: 写真に写っている物体(例えば、犬や猫など)を認識して分類する。
メールのスパム判定: 受信メールを「スパム」か「重要」かに分類するフィルタリングシステム。
金融詐欺検出: 顧客の取引パターンを分析し、不正な取引を検出する。
音声コマンド認識: 音声データを解析し、発音された言葉やフレーズを認識して対応する。
遺伝子データ解析: 遺伝子のパターンを基に、特定の疾患に関連する遺伝子のグループを特定する。
K-平均法(K-means Clustering)
意味: K-平均法は、データをあらかじめ設定した数(k個)のグループに分けるためのクラスタリング手法です。各データ点がどのクラスタに属するかを繰り返し計算し、クラスタの中心からの距離を最小化します。

K-平均法が使用可能だと考えられる具体例:
顧客クラスタリング: 小売業で、顧客の購買行動に基づいて異なるグループに分け、ターゲットを絞ったマーケティングを行う。
都市計画: 都市データ(人口密度、交通流量、土地利用など)を用いて、都市の各区域をグループ分けし、計画を立てる。
画像圧縮: ピクセルの色や濃淡に基づいて画像をいくつかのクラスタに分け、画像データを圧縮する。
市場調査: 消費者の嗜好や行動パターンに基づいて、異なる市場セグメントに分ける。
ネットワーク分析: ソーシャルネットワークデータをクラスタリングし、影響力のあるグループや個人を特定する。
階層的クラスタリング(Hierarchical Clustering)
意味: 階層的クラスタリングは、データをツリー構造(デンドログラム)のようにまとめてグループ化する手法です。類似度に基づいて、データを階層的に結合または分割していきます。
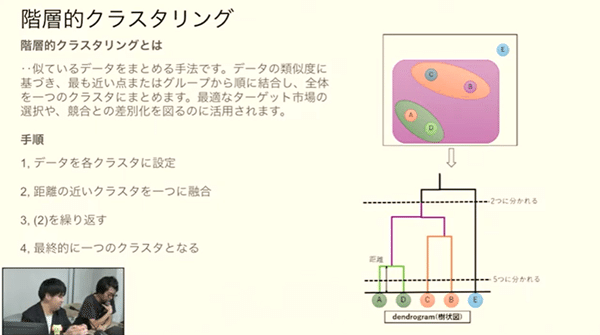
階層的クラスタリングが使用可能だと考えられる具体例:
遺伝子系統樹の作成: 遺伝子データを基にして、進化的にどの生物が近い関係にあるかをツリー構造で示す。
テキストクラスタリング: 複数の文書を内容の類似性に基づいて階層的に分類し、トピックやテーマを明確にする。
消費者行動分析: 消費者の購買履歴やフィードバックを分析し、共通の特徴を持つグループを階層的に特定する。
市場セグメントの明確化: マーケット調査で、複数の消費者属性に基づき市場を細分化し、各グループに最適な戦略を立てる。
文書の類似性分析: 多数の研究論文や記事を類似度でクラスタリングし、同様のテーマを持つ文書をまとめる。
主成分分析(PCA)
意味: 主成分分析(PCA)は、高次元のデータを簡略化する手法で、重要な特徴を抽出してデータの次元を減らし、理解しやすくすることを目的とします。

主成分分析が使用可能だと考えられる具体例:
顔認識システム: 顔画像の高次元データを低次元に圧縮し、計算効率を上げながら識別精度を維持する。
金融リスク管理: 多数の経済指標や金融データを少数の重要な指標に変換し、リスク評価を効率化する。
気象データ解析: 気温、湿度、風速など多くの気象データを圧縮し、天気予報モデルの精度向上に役立てる。
ゲノムデータ解析: 大量のゲノムデータを解析し、重要な遺伝子の特徴を抽出して、特定の疾患に関連する遺伝子を特定する。
品質管理: 生産ラインで多くの品質パラメータを少数の主成分に変換し、製品の不良率を減らすための対策に役立てる。
これらの具体例により、各手法の実際の使い方と応用範囲がより理解しやすくなると思います。
ニューラルネットワーク — 人間の脳を模倣する人工知能
ここで、生成AI技術の核心ともいえる「ニューラルネットワーク」に話を進めましょう。
ニューラルネットワークとは、人間の脳の神経回路を模倣した構造を持つAIモデルであり、データから学習し、予測や分類を行うための強力なツールです。まるで人間の脳が複雑な問題を解くために神経細胞(ニューロン)を使っているように、AIもまた「ニューロン」のような単位を利用してデータを処理します。

ニューラルネットワークは、主に三つの層から構成されています。「入力層」「中間層(隠れ層)」「出力層」の三層です。入力層はデータの受け口であり、中間層はデータを処理・変換する場所、そして出力層は最終的な結果を出力する役割を持ちます。
ここでの重要なプロセスは「伝播」と呼ばれるもので、データの値が層を通じて進む過程を指します。
ニューラルネットワークの伝播 — データの旅
ニューラルネットワークでの伝播プロセスを見てみましょう。
まず、データXが入力層に入ります。ここで、「重みW1」がデータXに掛け合わされ、中間層で変換されます。この変換後の値をYとします。次に、このYに「重みW2」を掛け合わせ、最終的に出力層Zに到達します。ここで「重み」というのは、データの重要度を示すバランスで、AIが学習を通じて最適な値を見つけ出します。
このプロセスを、料理の準備に例えてみましょう。
データXは、料理を始めるために台所に持ち込んだ材料だと考えてください。重みW1は、材料に最初に加える調味料のようなものです。この調味料を加えることで、材料(データX)は中間の段階である下ごしらえ(中間層Y)を経て、変化します。次に、下ごしらえした材料に、さらに別の調味料W2を加えて、最後の料理(出力層Z)が完成します。
この料理がうまくできるかどうかは、最初に選んだ材料と、どの調味料をどれだけ使うかにかかっています。同様に、ニューラルネットワークでは、入力データとそれにかける重みが重要で、それによって最終的な結果(出力)が決まるのです。
データ分析の選択肢を広げる — AIの活用
私たちは、回帰、分類、そしてニューラルネットワークという三つの異なる手法を理解することで、データの持つ力を最大限に引き出す方法を見つけることができます。
そして、これらの手法は単なる理論ではなく、実際にビジネスや日常生活の中で使えるツールです。
たとえば、決定木やランダムフォレストでデータを分類し、ニューラルネットワークでより複雑な予測やパターンの認識を行うこともできるのです。
もちろん、これらの手法をすべて詳しく理解する必要はありません。ChatGPTのようなツールに「決定木分析で作って」と頼むだけで、目的に合った分析をしてくれます。
この点は講座でGoogleColaboを利用して手を使って実施したので分かっていることでしょう。
大事なのは、これらの分析手法の存在を知り、それをどう使うかを考えることです。
モデルの種類や役割を覚えることも需要かもしれませんが、一番は「どういう状態を目指しているのか」を理解し、それに伴う必要な情報は何かを判断することです。
それが分かれば、後はそれに沿ったモデルが何かChatGPTに確認すれば選択肢をくれます。先のモデルの意味合いがある程度頭に入っていれば「ここは回帰で、このモデルを使おう」と判断可能になります。
知識として汎用性のあるものを会得し、細かい部分はAIに任せて覚えさせておくというのも、また一つ生成AIを使っていく方法と言えるのではないでしょうか。
データ分析の世界は深く、広がりがあります。
大海原を渡る船のように、どの手法を使うかで、どこにたどり着くかが変わってくるのです。
ビジネスにおけるモデルのマトリクス — 判別と回帰、予測と要因分析
ビジネスの世界では、意思決定を下すためにさまざまなモデルが使用されます。
これらのモデルは、データを基に未来を予測したり、過去のデータから原因を特定したりするためのものです。ここでは、ビジネスモデルを「判別」と「回帰」という二つの方法で縦軸に、「予測」と「要因分析」という目的で横軸にマトリクス化して考えてみましょう。それぞれの組み合わせが、どのようなビジネスの課題に対して役立つかを見ていきます。

左上:判別 × 予測 — 金融商品の購入顧客を予測
「判別」と「予測」を組み合わせたモデルは、特定のクラス(カテゴリー)にデータが属するかどうかを判別し、その結果を基に未来の行動を予測するものです。
例えば、金融商品をどの顧客が購入するかを予測する場合が該当します。このモデルでは、まず「顧客が商品を購入するかどうか」を判別します。その上で、「どのような顧客がどの期間に購入するのか」といった分類を行い、次に顧客予測を行います。
この情報を基に、効果的なダイレクトメール(DM)などを送付して購買率を上げる戦略を立てることが可能です。レーダーを使って魚群を捉えるように、ターゲット顧客を絞り込み、効率的なアプローチを図る方法です。
左下:回帰 × 予測 — 季節商品の需要予測
「回帰」と「予測」を組み合わせたモデルは、過去のデータを基に将来の数値を予測するものです。
たとえば季節商品の需要予測がこのモデルにあたります。このモデルでは、気温の変化や前年の気温データ、売上数などのデータを使って、次のシーズンの需要を予測します。
これにより、企業は在庫の適正化を図ることができ、余分なコストを削減しながらも必要な商品を十分に供給することが可能になります。農家が天候を読みながら適切な時期に作物を植えるように、ビジネスにおいても最適なタイミングでの意思決定が求められるのです。
右上:判別 × 要因分析 — 製造業における不良品判別
「判別」と「要因分析」を組み合わせたモデルは、特定の事象の発生原因を特定するために使用されます。
製造業における不良品判別がその一例です。このモデルでは、まず「不良品であるかどうか」を判別します。そして、不良品の発生原因を究明します。
例えば、工程Aで製品の表面温度が平均値よりも高いと不良品になりやすい、工程Bで電力量のばらつきが多いと不良品になりやすい、といった分析を行います。
このような結果を基に、製造工程を改善することができます。探偵が事件の現場から証拠を収集し、犯人を特定するように、不良品の原因を突き止め、製造プロセスを改善する作業です。
右下:回帰 × 要因分析 — 適切なテナント料の決定要因
「回帰」と「要因分析」を組み合わせたモデルは、数値の変動を予測し、その変動の要因を特定するために使われます。
たとえば、適切なテナント料の決定要因を分析する場合がこれに該当します。このモデルでは、過去のデータを基に適切なテナント料を回帰分析で予測します。同時に、そのテナント料に影響を与える要因(立地、周辺の商業施設の状況、交通の便など)を定量的に特定します。
こうした分析は、テナント料の設定をより客観的で公正なものにし、オーナーとテナント双方にとって納得のいく結果を導くための基盤となります。これは不動産の価値を慎重に評価し、最適な売買価格を設定する不動産鑑定士のような役割を果たします。
ビジネスの多様なモデル活用の意義
これらの四つのモデルの組み合わせは、それぞれ異なるビジネスの課題に対して有効となります。ビジネスの世界では、目の前のデータをどのように解釈し、活用するかが成功の鍵となります。判別と回帰、予測と要因分析という異なる視点を持つことで、企業はより柔軟で効果的な戦略を立てることが可能になるでしょう。
結局のところ、ビジネスにおけるモデルの活用は、どのようにデータを解釈し、それに基づいて行動を取るかにかかっています。
これらのモデルは多様なビジネスの課題を解くための道具箱のようなものであり、正しい道具を選ぶことで、企業は常に変化し続ける市場環境に適応し、競争力を維持することができるのです。
総括
今回の講義で強調されたのは、「業務をどうやって数値化していくのか」というテーマでした。ビジネスの基本とは、船の舵取りのように、さまざまな要因に対する判断の集合体です。私たちはビジネスという荒波の中で、絶え間ない判断と選択を繰り返しながら、進むべき航路を見出していかなければなりません。
現代のビジネス環境は、顧客の動向、市場の変化、競合の動き、新たな技術の進展といった無数の因子が絡み合い、嵐の中で舞う落ち葉のように常に変化し続けます。
この多様で複雑な因子を正しく選び、迅速かつ的確に判断することは、経営者にとって極めて難しい作業と言えるでえしょう。
ビジネスの基本方程式である「顧客数 × 購入頻度 × 単価」を向上させるため、最適な手を選び続ける必要がある中で、それをどう継続して実施していくのかを考えなければなりません。。
プロの経営者たちは、複雑な情報の渦の中で直感と経験を駆使し、最適な判断を下すために戦っています。しかし、これをAIが模倣するとなると、単なるデータ処理だけではなく、プロの経営者の思考プロセスそのものを学ばせる必要があります。AIの導入は技術の進化を超えて、経営の本質に迫る挑戦でもあるのです。
ここで重要なポイントとなるのが「AIのモデル化」です。
AIは、データの因子を見極め、それを基に意思決定をサポートするための「モデル」を構築する技術と言えます。AIのモデル化とは、現実の問題を解決するために、データを因子に分解し、その関係性を理解するための数学的なルールやアルゴリズムを設計することを指します。
例えば、金融商品の購入顧客の予測や、季節商品の需要予測、製造業における不良品の判別、適切なテナント料の決定など、さまざまなビジネス課題に対してAIモデルを適用することができます。
これらのモデル化は、経営者の判断を支援し、より良い意思決定を可能にするための重要な手段となるのです。
AIがプロ経営者の思考を学ぶことで、経験の少ない人々でも高度な判断力を持てるようになります。これは単なる技術的な進歩ではなく、知見の民主化とも言えるものでしょう。
AIが提供する判断を人間が評価し、フィードバックを与えることで、AIはさらに進化し、より優れた判断を行うようになります。
AIは単なる道具ではなく、人間の知見と直感を取り込み、さらに強化される存在へと変貌していきます。
AIが人間の経験や直感に基づく思考を学び続けることで、人間とAIは共進化し、新たな知見と革新が生まれるということです。このプロセスを通じて、AIは人間の限界を超える力を持ち、人間が直面する複雑な問題に対して新しい解決策を提供するパートナーとなるでしょう。
ビジネスの世界において、AIと人間の協働は、新たな知見と可能性を生み出すための鍵です。
AIのモデル化を通じて、私たちはデータを深く理解し、経営判断をより効果的に行うことができるようになるでしょう。そして、人間とAIが互いに補完し合いながら共進化することで、未来のビジネスの航路をより明確に切り開くことが可能になるのです。
以上、
抜けや漏れは講座のアーカイブにて。
<「他人の予習を覗き見してみる?」の企画として現在6万文字以上の学びを記しています。参考にどうぞ>