
Day10_Azureパイプライン生成の続き【備忘録】

今回は前回からの続きでAzureのパイプライン生成の部分を触っていくことになります。
よって前回を見ていないと「はい?」となるので、まだ復習サれていない方は下記より前回分をご覧下さい。
まず、AzureのDataFactoryの続きを触る前にデータパイプラインを復習しておきます。
データパイプラインとは、データの取得、処理、保存、分析などの一連の工程を自動化して連携させる仕組みを指す。データパイプラインは、複数のデータソースからデータを集め、必要な変換や処理を行い、最終的にデータウェアハウスやデータベースなどのストレージに格納するまでのプロセスを統合的に管理する。
データパイプラインの主な役割
データの収集:さまざまなソース(例:センサーデータ、ログファイル、APIなど)からデータを自動的に取得する。
データの変換とクレンジング:収集したデータを必要な形式に変換し、不正確なデータや欠損データを処理する。
データの保存:処理後のデータをデータベースやデータウェアハウスに格納し、分析や報告に利用できる。
データの分析と活用:保存されたデータを基に、レポート作成や機械学習モデルのトレーニングなどの分析作業を行う。
データパイプラインの目的は、データの流れを効率的に管理し、手動の介入を減らして、リアルタイムまたは定期的にデータを処理・活用できるようにすること。これにより、データドリブンな意思決定を支援し、ビジネスの効率化や価値創出を図れる。
それでは、前回からプラスしてストレージ部分でコンテナの追加作業を行います。
ストレージからコンテナを追加する
先日つくったストレージから「コンテナ」を作ります。
名前はここでは講座で扱っている自分のIDを付けています。

すると下記の様にコンテナが一つ増えているのが分かります。
この状態にしてから、次のステップに進みましょう。

前回の復習のようになりますが、新しく作ったコンテナにデータを保存していくので、その手順を確認します。
データフローの部分を選択します。

まずはデータフローのデバックを行いましょう。
それが完了したら、次にデータセットを選択していきます。
このあたりは先日の講座と同じ流れです。

新規を選択し、Azure BLOB ストレージを選択します。

選ぶのはJSONと呼ばれる形式です。
【ワンポイント調べ】
JSON(JavaScript Object Notation)は、データを構造化して記述するための軽量なフォーマットで、主にウェブアプリケーション間でデータを交換する際に使われる。
JSONは、オブジェクトや配列でデータを表現し、シンプルで人間にも機械にも扱いやすい形式である。多くのプログラミング言語でサポートされており、API通信や設定ファイルなどに広く利用されている。
(用語説明)
オブジェクト:キーと値の組み合わせでデータを表現する。
例:{"name": "Taro", "age": 30}
配列:順番があるリスト形式でデータを表現する。
例:["apple", "banana", "cherry"]

次のJSONのリンクサービスを新規で選びます。

内容は前回と同じで、SUNABACOで利用させてもらっているサブスクリプションであるAI1stを選びます。
※ちなみに黒塗りされているキーが分かると他の人も使われてしまう可能性があるので外部発信の際には注意が必要です。
次にストレージアカウント名は、以前付けたものを使用しましょう。これは前回の講座で作成しています。

作成を押すと、次にコンテナを選べる画面が出てきます。
このファイルパスのところに、今日の講座で最初に行った追加したコンテナ名をコピーして貼り付けましょう。

あとはテスト接続を行い、接続成功が表示されたら処理は終了です。

前回と同様に、検証を行い、問題なければ発行をします。

発行の内容を確認したら、そのまま発行ボタンを押すだけです。
右上に完了の合図が出たら保存も完了です。
(未保存のマークである●が消えているはずです)
トリガー設定を追加する
続いて今回は「トリガーの追加」を行います。
トリガーというのは、どういった条件でデータの抽出を開始するかを決定するものです。

トリガー追加を選択して、新規/編集を選択します。

ここでも今まで同じく新規を選択。
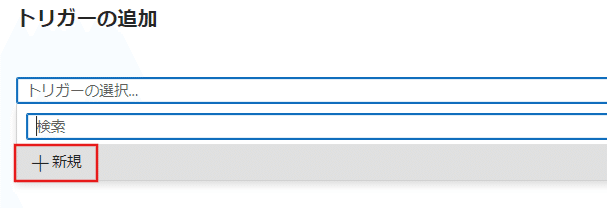
新しいトリガーの種類などが出てきますので、ここではスケジュールを選択します。
スケジュールとは、日付や曜日や日数感覚などをきっかけとして作動させるシステムです。
今回は1週に1度、日曜日の2時という設定で行ってみます。

あとはそのまま進めば、最終的にトリガーのところに(1)と表示されるようになります。

勿論、今回はテストなので、週イチの日曜日の2時にしていますが、実際は必要な頻度で実行を行うが良いでしょう。
またトリガーの種類についても、様々なものがありますので、確認しながら最も適していると考えられるものを利用していくと良いです。
同じく最後は「すべて発行」で保存をして終了です。

これで週に1回、天気予報のAPIでデータを取ってくるという作業が行われることになります。
APIは、アプリやソフトウェアが他のサービスやシステムとデータをやり取りしたり、機能を使ったりするための仕組み。天気アプリがAPIを使って気象情報を取得するように、APIを使うことで開発者は他のサービスを自分のアプリに簡単に組み込むことができる。APIは、システム同士をつなぐ「橋渡し」の役割を果たす。
ここまでがデータに対して、それを抽出するまでの一連の流れの一例となります。
ETLのEの部分、その初歩です。
【ワンポイント復習】
ETLは、「Extract, Transform, Load」の略で、データ処理の一連のプロセスを指します。主にデータウェアハウス(整理された倉庫ね)やデータ分析のために使用されます。
ETLの3つのステップ
Extract(抽出):さまざまなデータソース(データベース、API、ファイルなど)から必要なデータを取り出す。
Transform(変換):抽出したデータを目的に応じて整理・変換する。たとえば、データのクレンジング、形式変換、集計などを行う。(今日のところ)
Load(ロード):変換されたデータをターゲットのシステム(データウェアハウスやデータベース)にロード(書き込み)する。
ETLの用途
ETLは、大量のデータを効率的に集約・分析するために必要なプロセスで、企業の意思決定支援やビジネスインテリジェンス(BI)に広く利用されています。
※ビジネスインテリジェンスは、企業がデータを活用して意思決定を支援するための技術やプロセス、ツールの総称です。
データを変換していく
今回はデータの抽出から、次のステップである「変換」を実施していきます。
保存しているデータは、まだ使える形にはなっていません。
それを整理して倉庫に入れていく必要があります。
その整理手順の一例を今回は行っていきます。
まずは同じ様にパイプラインを新たに作成していきます。
手順は前回のものと今回のものを重ねて理解できていれば難しくはないはずです。
(トリガー設定はしなくてOK)

天気予報のAPI情報が取れる状態になったら、変換の作業を行っていきます。
ここで大事なポイントがあります。
ETLにおけるデータの変換について「どうなって欲しいのか」が分かっていなければ変換できない。
【ワンポイント考察】
ETLプロセスの「変換」段階で最も重要なのは、「データをどう変えたいのか」という明確な目標を持つことだ。
データの変換とは、単に形式を変更するだけでなく、業務ニーズに応じてデータを適切な形に整えるプロセスを指している。
たとえば販売データを分析する際、単に「販売件数」を取り出すだけでは不十分で、期間別や地域別など、目的に応じた集計や分類が必要になるだろう。それが出来得る形で変換していなければ意味がない。
もし変換の目的が曖昧であれば、不必要なデータの削除や重要な情報の欠落といったリスクが生じてしまう。
データが「どうなって欲しいのか」を理解していないと、適切な変換ルールを設定できず、結果として誤った意思決定につながる可能性が高まってしまうのだ。
データを効果的に活用するためには、具体的なビジネスゴールを明確にすることが不可欠と言える。
これはどんなビジネスで使用するデータにも言えることである。
たとえば、今は天気のデータを使っていますが、その表はバラバラな形で整理されていません。
実際にデータを見れば分かりますが、たとえば列と行が整合性の取れた形になっていないのが分かります。
この状態ではデータ分析をすることは出来ません。
よって、今回はデータ分析するためには1行目にtimeやdescriptionなどの列名を表記すべく整理していきます。
まずは列名を確定させましょう。今回は下記を列名とします。
forecast_date
forecast_time
location
today_weather
tomorrow_weather
まずは第一の手順として、新たな列に上記列名を入力していきます。
(forecast_datetimeは一時的に同じになりますが、この分離については後日実施するとのことです。なので今回はdatetimeを同一として4つの列を新たに増やす工程です)
まずはSourceからプロジェクションを選び、インポートを実施しましょう。

インポートが完了したら、次に+から派生列を追加。
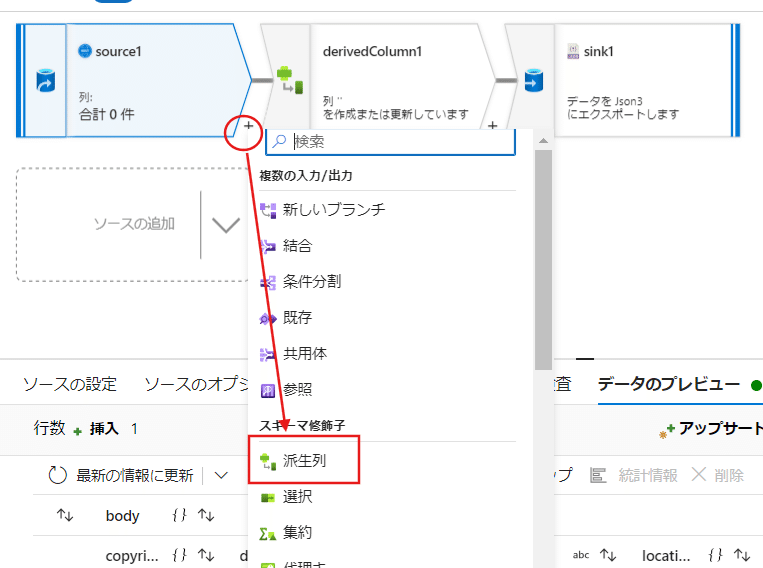
派生列の設定で+追加を押して列追加を4つ行います。

【列】には改めて作る列名を入れましょう。
【式】にはどの元データを意味するのかを記します。

天気予報のAPIの中に元データの名前が出ているので、それを参考に入力します。

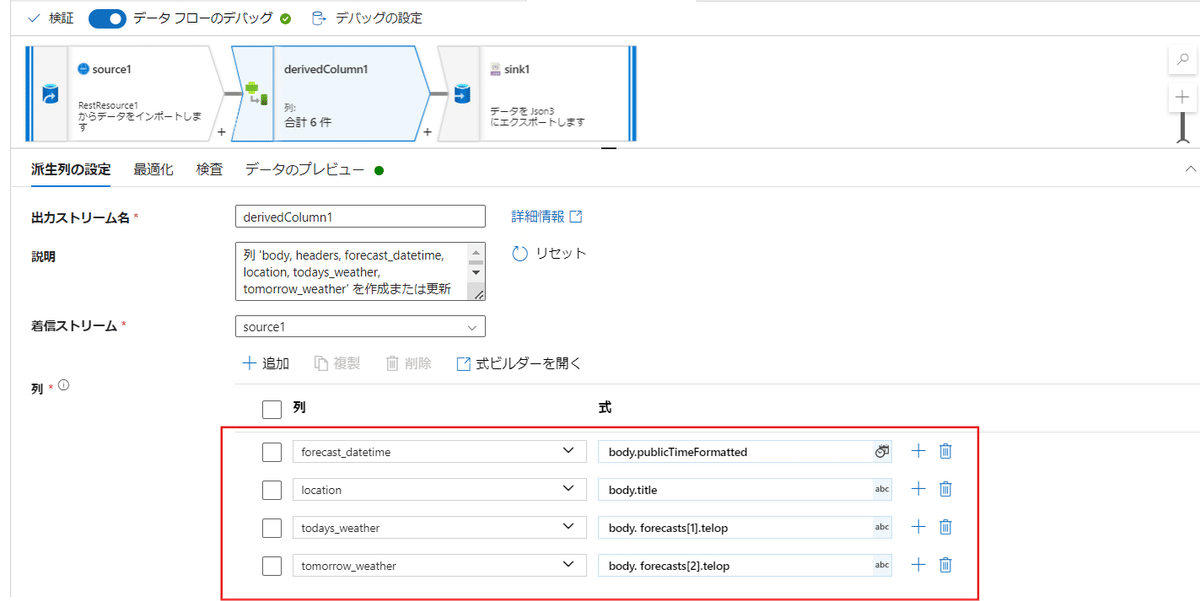
セットしたらデータをプレビューして最新状態に更新しましょう。
それで新しく作った列名が出ていれば完成です。
保存する場合は、同じ様に【すべて発行】を行います。

細かく設定していくのが非常に面倒に思えたかもしれません。
ただ一度目は面倒な作業になりますが、今後は全て自動で行ってくれるようになるので、度重なるデータ抽出がある場合は非常に有効です。
現在Azureの作業の難易度が増しているからこそ、改めて原点に戻る必要があると感じます。
「一体、今何のために、この分析工程を行っているのか」です。
ボトルネックの解消を目指すデータ分析の重要性
データ分析の目的・ボトルネックの特定と解消
データ分析を成功させるためには、まず「何がボトルネックになっているのか」を明確にすることが求められます。
ボトルネックの特定なしには、どのデータを使うべきか、どの分析手法が有効かを決定することはできません。
たとえば製造業での生産ラインの効率を向上させたい場合、ボトルネックがどこにあるのかを明確にすることが最初のステップです。そのためのデータ分析としては、各工程の処理時間や待ち時間を収集・分析し、どの工程が全体のスループットを制限しているのかを特定します。
ボトルネック解消のためのデータ分析の原則
目的の定義とボトルネックの特定
まず、「どのボトルネックを解消したいのか」を明確に定義します。この目的が定まらないと、収集するデータや選ぶ分析手法が意味を持たなくなってしまいます。データ収集とボトルネックの可視化
特定したボトルネックに関するデータを収集し、その状況を正確に把握するために可視化します。グラフやチャートを用いて、各工程のパフォーマンスを視覚的に示し、ボトルネックの影響を具体化します。適切な分析手法の選択
ボトルネックを解消するためのデータ分析手法を選びます。例えば、統計的手法やシミュレーション分析やモデル分析を用いて、ボトルネックの影響を数値化し、その解消策を見つけ出します。解決策の実行とモニタリング
分析結果に基づいて解決策を実行し、その効果を継続的にモニタリングします。ボトルネックが解消されたかを確認し、必要に応じてさらなる改善策を講じます。
意味のあるデータ分析のために
データ分析の本質は、単なるデータの操作ではなく、ボトルネックを見つけ出し、それを解消することで組織のパフォーマンスを最大化することにあります。
『ザ・ゴール』が示すように、すべてのデータ分析は「何がボトルネックであるのか」「それをどう解消するのか」という目的を中心に据えるべきです。
この目的を見失うことなく、分析を進めることで初めて、データは価値を生み出すものとなるでしょう。