
【MiLB】RとExcelでMiLB Percentile Rankingsを作成する

ブルワーズ担当のあなんです。
MLB分析指南noteみたいなのが流行ってるっぽいので便乗します。
ですが、ただ乗っかるのもアレなんで、差別化をはかってテーマはMiLB(マイナーリーグ)です。
今回はbaseball savantに掲載されてるPercentile Rankingsのマイナーリーグverを作成します。

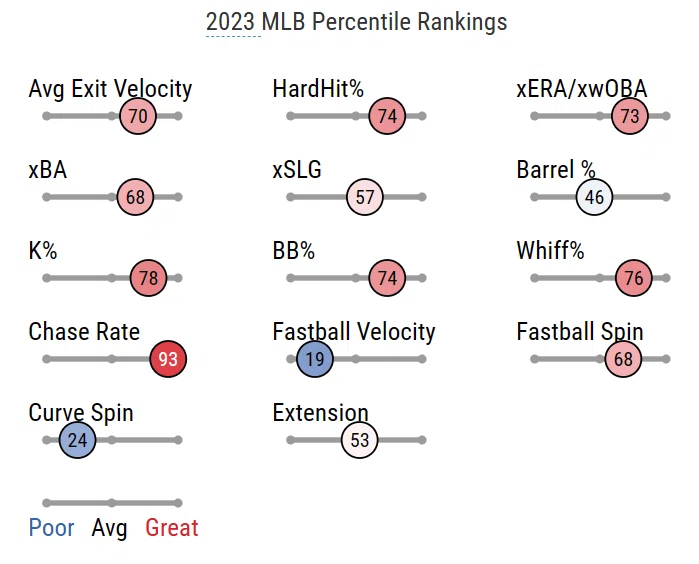
これって各選手の指標の良し悪しを一目で判断できる画期的なツールですよね。これのマイナーリーグver.あったら面白くね?という好奇心が作成のきっかけです。
また、わたしはマイナーに大変疎いため、導入として贔屓のプロスペクトの状態を感覚的に知りたいという動機もあります。あと、K%いくら、BB%いくらと言われても、相対的な良しあしがいまいちわからないので、それならいっそ自力でpersentileに落とし込んでみようというシンプルな(コストとか考えない)発想で作ってます。
○ 必要な道具
◇ Rstudio
・baseballrパッケージ
・mlb_schedule関数
・get_pbp_mlb関数
・code_barrel関数
・tidyverseパッケージ
◇ Excel
ここからは、ランキングの作成方法を順に説明します。
○ その1 ~game_pk取得~
get_pbp_mlb関数は引数にgame_pkをとるため、あらかじめmlb_schedule関数を用いてgame_pkを取得します。
pk <- mlb_schedule(season, level_id)1つ目の引数には年、2つ目には階級IDをとります。階級IDに関しては、以下のように分類されています。
・MLB = 1 ・AAA = 11
・AA = 12 ・A+ = 13 ・A = 14
・Class A Short Season = 15
・Rookie Advanced = 5442
・Rookie = 16
・Winter League = 17
このnoteでは4月までのAAA階級を例にとるので、levels_idは11です。
pk <- mlb_schedule(2023, 11)
pk4 <- pk %>% filter(date <= "2023-04-30", status_coded_game_state == "F") %>%
pull(game_pk) %>% unique()○ その2 ~pitch_by_pitchデータ取得~
get_pbp_mlb関数でマイナーのpitch_by_pitch(以降、pbp)データを取得します。
pbp <- get_pbp_mlb(game_pk)get_pbp_mlbで得られるpbpデータは153行に及びます。scrape_statcast_savantは90行ほどですので、実に1.5倍以上の情報量です。

そのため必要(そう)なデータだけピックアップします。
use <- c("isPitch", "game_pk", "about.inning", "about.isTopInning",
"batting_team", "fielding_team", "atBatIndex",
"home_team", "home_parentOrg_name",
"away_team", "away_parentOrg_name",
"matchup.batter.id", "matchup.batter.fullName",
"matchup.pitcher.id", "matchup.pitcher.fullName",
"about.isTopInning" , "home_team", "home_parentOrg_name",
"away_team", "away_parentOrg_name",
"pitchData.strikeZoneTop", "pitchData.strikeZoneBottom",
"pitchData.coordinates.pfxX", "pitchData.coordinates.pfxZ",
"pitchData.coordinates.pX", "pitchData.coordinates.pZ",
"pitchData.coordinates.aX", "details.type.description",
"pitchNumber", "details.description",
"pitchData.extension", "pitchData.breaks.spinRate",
"pitchData.startSpeed",
"result.eventType", "pitchData.zone",
"hitData.launchSpeed", "hitData.launchAngle", "hitData.totalDistance")投球通過位置を示すデータがどれを指すか定かでないが
pitchData.coordinates.pXがx座標、
pitchData.coordinates.pZがy座標に当たると推測。
1試合分のpbpデータはgame_pkを入力してゲットできますが、実際は100試合単位のpbpデータが欲しいです。そのため繰り返し関数(map関数)を使って一気に取ります。
unzip <- function(...)rbind(data.frame(), ...)
dat <- map(.x = pk4,
~get_pbp_mlb(.x) %>%
select(all_of(use))) %>%
do.call(unzip, .)余談ですけど、map_df関数では空のデータフレームを結合できずエラーが発生するのでおすすめしません。
列名がクソ長いのでrename関数でスリムにします。その後HardHit判定列とbarrel判定列を追加します。
dat1 <- dat %>%
filter(isPitch == TRUE) %>%
rename(sz_top = pitchData.strikeZoneTop,
sz_bot = pitchData.strikeZoneBottom,
batter = matchup.batter.id,
batter_name = matchup.batter.fullName,
pitcher = matchup.pitcher.id,
pitcher_name = matchup.pitcher.fullName,
TopBot = about.isTopInning,
inning = about.inning,
home_parent = home_parentOrg_name,
away_parent = away_parentOrg_name,
plate_x = pitchData.coordinates.pX,
plate_z = pitchData.coordinates.pZ,
description = details.description,
zone = pitchData.zone,
events = result.eventType,
pitch_name = details.type.description,
launch_speed = hitData.launchSpeed,
launch_angle = hitData.launchAngle,
distance = hitData.totalDistance) %>%
mutate(TopBot = ifelse(TopBot == TRUE, "Top", "Bot"),
Hard = ifelse(launch_speed >= 95, 1, 0),
fielding_org_team = ifelse(TopBot == "Top", home_parent, away_parent),
batting_org_team = ifelse(TopBot == "Top", away_parent, home_parent)) %>%
code_barrel()
write_csv(dat1, "statcast/sci2023.csv")○ その3 ~各指標の計算~
Percentile Rankingsで扱ってる指標のうち、xスタッツ系(xERA・xwOBAなど)やsprint speed以外の指標は自力で計算できます。
sci23 <- read_csv("statcast/sci2023.csv")read_csv関数で保存したcsvを読み込みます。
以降、投手を例に。
◇ Batted Ball & extension
平均打球速度、バレル率、HardHit率、エクステンションを求めます。
pit1 <- sci23 %>%
group_by(pitcher_name) %>%
summarize(N = n(),
avg_exit_velocity = round(mean(launch_speed, na.rm = TRUE),1),
barrel = round(100 * mean(barrel, na.rm = TRUE), 1),
Hard = round(100 * mean(Hard, na.rm = TRUE), 1),
extension = round(mean(extension, na.rm = TRUE), 1),.groups = "drop")四捨五入するのにround関数を用いたが、
厳密には四捨五入する関数ではない。
◇ K%, BB%
filter関数(とstr_detect関数)を用いて1打席1行のデータフレームに変換します。
sci231 <- sci23 %>%
group_by(game_pk, atBatIndex) %>%
filter(pitchNumber == max(pitchNumber),
!str_detect(events, "pick |caught| game_advisory"))
pit2 <- sci231 %>%
group_by(pitcher_name) %>%
summarize(PA = n(),
K_percent = round(100 * sum(events == "strikeout") / PA, 1),
BB_percent = round(100 * sum(events == "walk") / PA, 1))◇ Chase%, Whiff%
Chase%:ボール球を振らせた割合
Whiff%:スイング数に対する空振りの割合
swing <- c("Swinging Strike", "Swinging Strike (Blocked)", "Foul", "Foul Tip",
"In play, no out", "In play, out(s)", "In play, run(s)")
whiff <- c("Swinging Strike", "Swinging Strike (Blocked)")
sci232 <- sci23 %>%
filter(!grepl("Bunt", description))
pit3 <- sci232 %>%
group_by(pitcher_name) %>%
summarize(chase_rate = round(100 * sum(description %in% swing & zone %in% c(11:14)) /
sum(zone %in% c(11:14)), 1),
whiff = round(100 * sum(description %in% whiff)/
sum(description %in% swing), 1))※バントが絡むデータは省いています
◇ Fastball Velocity, Fastball Spin
fb <- sci23 %>%
filter(pitch_name %in% c("Four-Seam Fastball", "Sinker", "Cutter"))
pit4 <- fb %>%
group_by(pitcher_name) %>%
summarize(Fastball_velocity = round(mean(release_speed, na.rm = TRUE), 1),
Fastball_spin_rate = round(mean(spin_rate, na.rm = TRUE)))ここまで集計したデータを結合。
pit <- pit1 %>%
left_join(pit2, by = "pitcher_name") %>%
left_join(pit3, by = "pitcher_name") %>%
left_join(pit4, by = "pitcher_name") %>%
filter(PA >= 30)◇ percentileに変換
選手名とチーム名のデータフレームを作成。
percent_rank関数で全指標をパーセンタイルに変換して結合。
pit5 <- sci23 %>% distinct(pitcher_name, fielding_team, fielding_org_team)
pits <- pit %>%
transmute(pitcher_name = pitcher_name,
Pit = N, PA = PA,
Avg_EV = round(percent_rank(-avg_exit_velocity) * 100, 1),
Barrel = round(percent_rank(-barrel) * 100, 1),
Hard = round(percent_rank(-Hard) * 100, 1),
Extension = round(percent_rank(extension) * 100, 1),
K = round(percent_rank(K_percent) * 100, 1),
BB = round(percent_rank(-BB_percent) * 100, 1),
Fastball_velocity = round(percent_rank(Fastball_velocity) * 100, 1),
Fastball_spin_rate = round(percent_rank(Fastball_spin_rate) * 100, 1),
Chase_rate = round(percent_rank(chase_rate) * 100, 1),
Whiff = round(percent_rank(whiff) * 100, 1)) %>%
inner_join(pit5, by = "pitcher_name", multiple = "all") %>%
select(pitcher_name, fielding_team, fielding_org_team, everything())
write_csv(pits, "pit.csv")完成。

○ その4 ~色付け~
ようやくExcelの出番です。
条件付き書式のカラースケールを用います。

ルールの種類は「セルの値に基づいて全てのセルを書式設定」。savantと同様、平均を白として、劣っていれば青色、優れていれば赤色に塗ります。

完成。

実際は全球団色塗り済み。
○ おまけ~打者編~
#batted ball
bat1 <- sci23 %>%
group_by(batter_name) %>%
summarize(N = n(),
avg_exit_velocity = round(mean(launch_speed, na.rm = TRUE),1),
max_exit_velocity = max(launch_speed, na.rm = TRUE),
barrel = round(100 * mean(barrel, na.rm = TRUE), 1),
Hard = round(100 * mean(Hard, na.rm = TRUE), 1), .groups = "drop")
#K BB
bat2 <- sci231 %>%
group_by(batter_name) %>%
summarize(PA = n(),
K_percent = round(100 * sum(events == "strikeout") / PA, 1),
BB_percent = round(100 * sum(events == "walk") / PA, 1))
#chase_whiff
bat3 <- sci232 %>%
group_by(batter_name) %>%
summarize(chase_rate = round(100 * sum(description %in% swing & zone %in% c(11:14)) /
sum(zone %in% c(11:14)), 1),
whiff = round(100 * sum(description %in% whiff)/
sum(description %in% swing), 1))
#team
bat4 <- sci23 %>% distinct(batter_name, batting_team, batting_org_team)
bat <- bat1 %>%
left_join(bat2, by = "batter_name") %>%
left_join(bat3, by = "batter_name") %>%
filter(PA >= 30)
bats <- bat %>%
transmute(batter_name = batter_name,
Pit = N, PA = PA,
Avg_EV = round(percent_rank(avg_exit_velocity) * 100, 1),
Max_avg_EV = round(percent_rank(max_exit_velocity) * 100, 1),
Barrel = round(percent_rank(barrel) * 100, 1),
Hard = round(percent_rank(Hard) * 100, 1),
K = round(percent_rank(-K_percent) * 100, 1),
BB = round(percent_rank(BB_percent) * 100, 1),
Chase_rate = round(percent_rank(-chase_rate) * 100, 1),
Whiff = round(percent_rank(-whiff) * 100, 1)) %>%
inner_join(bat4, by = "batter_name", multiple = "all") %>%
select(batter_name, batting_team, batting_org_team, everything())
write_csv(bats, "bat.csv")
本noteでは、集計したデータをもとに考察する意図は一切ないのでこれにて終了です。
皆さんもぜひマイナーリーグをチェックする際に使ってみてはいかがでしょう。え、そんな手間かかることしないって…??