
$1でTwitter(X)のブックマークをスプシ保存&カテゴライズして保存する【with AI】

はじめに
みなさん、Twitter(X)で「あ、後で読も」って思ってブックマークしたツイート、ちゃんと読んでますか?
僕は「いいえ」です。Twitter(X)のブックマークは溜まる一方で、その数3000を超えていました。

せめてブックマークを自動カテゴライズできたり、検索機能があったら良いのに。。。って思ってます。
この記事を読めば、そんな課題を解決できます。
1. Twitter(X)のブックマークのツイートを全て出力し、
2. AIを使って半自動でカテゴライズして、
3. フォルダ分けして保存する方法
をステップバイステップで解説するからです。

僕の3000ほどのツイートも全てカテゴライズして保存することができました。

あとはこのツイートたちをGPTに読み込ませれば「ChatGPTのプロンプトに関するツイート教えてー」と言えば出してくれたり、(何かClaudeのプロンプトの書き方について、ブックマークしたいいツイートないかな。。。)となった時に素早く引き出すことができます。

そしてこのフロー、実はChatGPTやClaude、GeminiなどのLLMにそのまま投げるだけではうまく処理ができません。
なので僕も色々実験をし、数々の失敗を繰り返して最終的に90点ほどのクオリティに仕上げました。
その実験時間は10時間を超えました。今回はその実験の成果をまとめます。
正直残り10点を高めるにはさらに多くの時間を要しそうだったので、この時点で記事にさせていただきました。
そのせいで全自動ではなく半自動で作業をする必要があります。
ここは残念ですが、大半はAIに作業をさせ、AIの処理が終わったら定型文をコピペするだけ、まで仕上げてありますので、ご了承ください。
僕も部屋の片付けをしたり、この記事を書きながら回しています。
今回はそこを詰めきれなかったので、値段も安くしてノウハウを販売します。ですが、今後Cozeなどを用いて全自動化できた場合、値上げを予定しています。
Twitter(X)のブックマークが氾濫してどうしようもない、あそこに溜まった知識を活かせればもっと成長できる、そう感じている方には役に立てる自信があります。

※ブックマークはその時点で出力したものが処理の対象になります。出力した後にブックマークしたツイートについては対象外です。
有料部分では、Twitter(X)のブックマーク出力に使ったツール、カテゴライズをするときに使ったAI、そしてプロンプトを紹介しています。
気になるけど、、、という方向けに、Twitter(X)でツイートをリツイートしていただいた方には割引も行っています。対象のツイートをリツイートしていただければ、安く手に入れることができますので、ぜひ!
購入していただき、ありがとうございます!それでは解説していきます。
Twitter(X)のブックマークを全てcsvに出力する方法
このChrome拡張機能を使用します。
Twitter APIの値上げ前はプログラムを書いて自動で出力もできましたが、それも高くなったようで、少し調べた感じではこれが一番安かったです。
その料金、なんと$1。ブックマーク内のツイート数が100を超えると有料になるのですが、いくらあったとしても$1でダウンロード可能。
しかもユーザーネームもパスワードも入力する必要ありません。
早速Chrome拡張機能を追加して、クリックします。
すると勝手にTwitterのブックマークが開いてダウンロードが開始されます。

僕みたいにブックマークに溜め込む人間は3000を超えるブックマークがあるようです。
ここで、後程の処理を考えて「CSV」形式でダウンロードします。
以下のようなスプレッドシートを得られたらOKです

※もしかしたら日本語が文字化けしているかもしれません。その場合は文字コードが原因なので、ChatGPTに頼んで直してもらいましょう。
使用するAI
さて、このcsvファイルを単純にLLMに投げてもやりたい処理がうまくできません。ファイルが少なければ良いのですが、分割すればするほど一括検索が難しくなります。

※そのまま渡して、「ChatGPTに関するツイートを教えて」などもできますが、抜け漏れが多く、精度が悪いです。(ツイート内に「ChatGPT」という文言があるかどうかで判断されてしまうため)
これはツイートを一つずつ確認し、そのツイートの中身を吟味、カテゴライズしてそのタグをデータとして追加しておくことでより精度を上げられます。

このように、ツイートに対してタグ付けをすることで、カテゴリ別にフォルダごとに分けて保存することができ、後々の処理も精度を上げられます。
Gemini 1.5 Proとは
Gemini 1.5 Proとは、Googleが作成しているLLMで、その精度はGPT-4oにも匹敵します。
1番の特徴はコンテキストウィンドウの大きさ(扱えるトークン数)が100万トークン(この前のアップデートで200万まで増えることが発表されました)であることで、他社のLLMを圧倒しています。
なので、今回のような大量のツイートをうまく処理するにはGeminiが最適になります。
Gemini 1.5 proはChatGPTのようにチャット形式で使えますが、今回使うのはGoogle AI Studioから使えるものです。こっちのものの方が今回の処理に適しています。
こちらのGemini 1.5 Proは無料で使うことができます。(2024.06.01時点)
詳しくはこちらをご覧ください。
利用登録が完了すると、以下のようになります。

ここまできたらひとまずOKです。左上の「Create new prompt」を押すと新しいチャットを開いて会話が開始できるので遊んでみても良いでしょう。
右上の「Token Count」を見ると上限が約100万トークンになっていることがわかります。とんでもないです。
ChatGPT
AIには得意不得意があるので、ChatGPTも利用します。
ChatGPTの主な用途は前処理と後処理です。
上記のGemini 1.5 Proでは、なんとcsvファイルの直接編集ができません。。。
従ってcsvファイルの直接編集が必要な場面ではChatGPTを利用します。
具体的にChatGPTを利用する場面は後程お伝えします。
全体のフロー
さて、これらのツールをつかってやりたいことを実現します。
全体像を軽くいうと、
1. ブックマークを出力
2. ChatGPTと手動で前処理
3. ツイート一つ一つをGemini 1.5 Proにカテゴライズしてもらう
4. スプシにコピペ
5. ChatGPTにカテゴリーごとにフォルダ分け&保存
です。詳しくみていきます。
1. ブックマークをcsvファイルに出力
まずは先ほどのChrome拡張機能を使ってブックマークのツイートを全てエクスポートしましょう。
2. 前処理(ツイートにid付け&ファイル分割)
ここで早速前処理を行います。
・ツイートにid付け
Gemini 1.5 Pro、いくら長文を扱えるといっても精度に限界はあるようで、
自分が試した限りでは単純に処理を行うと150ツイートほどが限界っぽく、これでは3000もあるツイートを処理するのに20回もフローを繰り返す必要があります。。。
ただ、試行錯誤により、ある工夫をすることでその限界を1000ツイートまでに増やすことができました。
それがid付けです。
1つずつツイートを処理するのに、csvファイルからツイートを読み込むのですが、そのツイートの読み込みがある程度処理を繰り返すと正常にできなくなります。
同じツイートが出てきたり、ツイートをいくつか飛ばして処理をしてしまうのです。
そこで、ツイートにidをつけて、処理時にそのidも同時に出力させることによって、LLMに順番を意識させました。
本当にこれの効果かはわかりませんが、正しくツイートを抽出してくれるようになりました。
従って、ツイートを保存したcsvの一番左の列に「tweet_id」列を追加し、1番目から1, 2, 3…と番号を振っていきます。
(Excelを使い慣れた方はわかると思いますが、1と2と3だけ入力し、右下の四角をダブルクリックすれば全て番号づけが自動でできます)

・|を\に変える
これは僕が処理を終えてから気づいたことなのですが、|という文字が含まれていると、のちにGeminiが表形式で出力するときに混同してしまい、表が崩れてしまいます。
なので、この段階でファイル内の|を全て他の文字(例えば\)に変換しておけば、より正常に処理をできると思います。
・ファイル分割
次のステップはファイルを分割することです。
先ほども言いましたが、いくらGemini 1.5 Proといえど、処理の長さには限界があります。僕が試した限りでは大体1000ツイートが限界でした。
プロンプトの工夫をしても全然正しく抽出ができなくなります。
ファイル分割はChatGPTに任せます。全てのツイートが入ったcsvファイルを渡し、分割してもらいます。
プロンプト
このファイルは私のTwitterのブックマークのツイート情報をまとめたcsvファイルです。
このファイルにはツイートのidを示す「id」列があるので、その「id」の番号を参照し、1000ツイートごとにファイルを分割してください。
分割後のファイル名は自由です。今の実験段階では1000ツイートが限界なので、もっと実験を繰り返してより多くの処理が可能になればまたこのブログにて共有します。
3. Gemini 1.5 Proでカテゴライズ
カテゴライズをしていきます。Gemini 1.5 Proの画面を開いてください。
いくつか準備が必要です。
・Gemini 1.5 Proを選択

Gemini 1.5は現状二つのモデルが存在します。Flashの方は精度がやや落ちる代わりに処理が早くなります。Proの方は速度が少し遅い代わりに精度が高いです。
Proでも遅いわけですし、Flashを使うと250ツイートあたりが限界であったため、Proを使用します。ここがFlashになっているとうまくいかないので注意してください。
・Temperature=0とする

Temparetureは、LLMに独創性を持たせるパラメータです。1に近いほどよりクリエイティブな出力に、0に近い方がよりプロンプトに忠実で安定した出力になります。
今回はcsvファイルから正確に抽出して欲しいので、クリエイティブさは必要ありません。Temperature=0にします。
・Safety Settingsを全て「Block none」にする
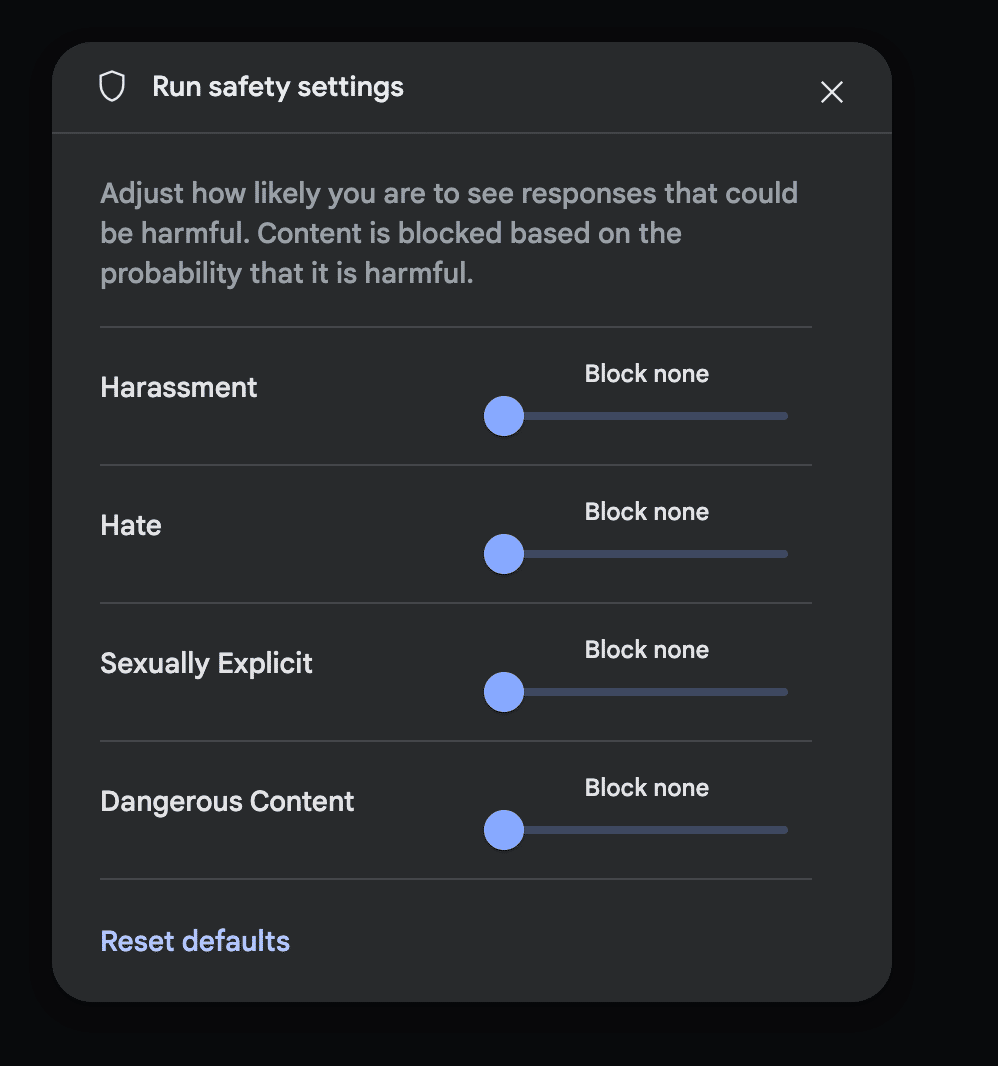
ツイートの内容によっては、Geminiが不適切と判断したものがあるとそこで処理が止まってしまいます。止まったらそれを飛ばして次から、でも良いのですが、なるべく止まる回数を少なくしたいので制限をゆるくします。
初期プロンプト
ここまでくれば準備完了です。早速カテゴライズを開始しましょう。
画面中央の下の+ボタンからツイートをまとめたcsvファイルをインポートします。

ファイルを読み込むと70万トークンほど行きました。(3000ツイートの場合)
これと以下のプロンプトを貼り付け、実行します。
# 指示書
file_name = "ツイートを保存したcsvファイル名"
あなたには、「{file_name}」を使ってデータ抽出を行ってもらいます。
具体的な処理は# 処理内容 を参照してください。
# 前提
あなたに渡した「{file_name}」は、私のTwitterのブックマークにあるツイートをすべてまとめたものになります。
ツイートは「{file_name}」ファイルの「full_text」列に格納されています。
ツイートのリンクは「{file_name}」ファイルの「tweet_url」列に格納されています。
ツイートした人は「{file_name}」ファイルの「name」列に格納されています。
# 処理内容
1. カテゴリー作成
- それぞれのツイートをカテゴライズしたいので、カテゴリーを作ります。具体的には、大きなカテゴリ、その中に中カテゴリ、そしてさらにその中に小カテゴリを作り、フォルダ分けしていくので、あなたにはそのそれぞれのカテゴリを作成して欲しいです。カテゴリはMECEにお願いします。
- ツイートは必ずどれかのカテゴリに所属するようにしてください。大カテゴリ、中カテゴリ、小カテゴリ、全てについて空欄は許されません。
2. ツイート分類
- ファイル内のツイートについて、カテゴリ分類を行なってください。
- カテゴリ分類は# 分類ルール を守ってください。
- すべてのツイートに対して生成し終わるまで、処理を続けてください。
- 出力は指定した表以外は表示しないでください。
# 全体的な制約
- think in English, output must be in Japanese
- ツイートは抜け漏れなく、正確に抽出して処理してください。
- 「{file_name}」には「id」という列があり、それぞれのツイートに固有の番号が振られています。このidを1から順番に処理してください。
- プロンプトに忠実に従ってください。
# 分類ルール
- 既存のカテゴリに分類できればそのカテゴリに分類する。
- 既存のカテゴライズが不適切であれば、新たにカテゴリを作成し、それに分類する。
# 出力ルール
- 列は「id」「ツイート内容」「ツイートリンク」「大カテゴリ」「中カテゴリ」「小カテゴリ」です。
- Googleスプレッドシートにコピペするだけで表として認識されるようにしてください。
- 表は途中で途切れないようにしてください。
- 上記の# 全体的な制約 を必ず守ってください。
# 出力基本的なプロンプトの書き方については、別の記事で解説していますので、そちらをご覧ください。
これによって、Gemini 1.5 Proに一つずつツイートをみてもらい、カテゴリーをつけていきます。
決まったカテゴリーにしたい場合はその旨をプロンプトに追加しましょう。
実行すると以下のような出力が得られます。
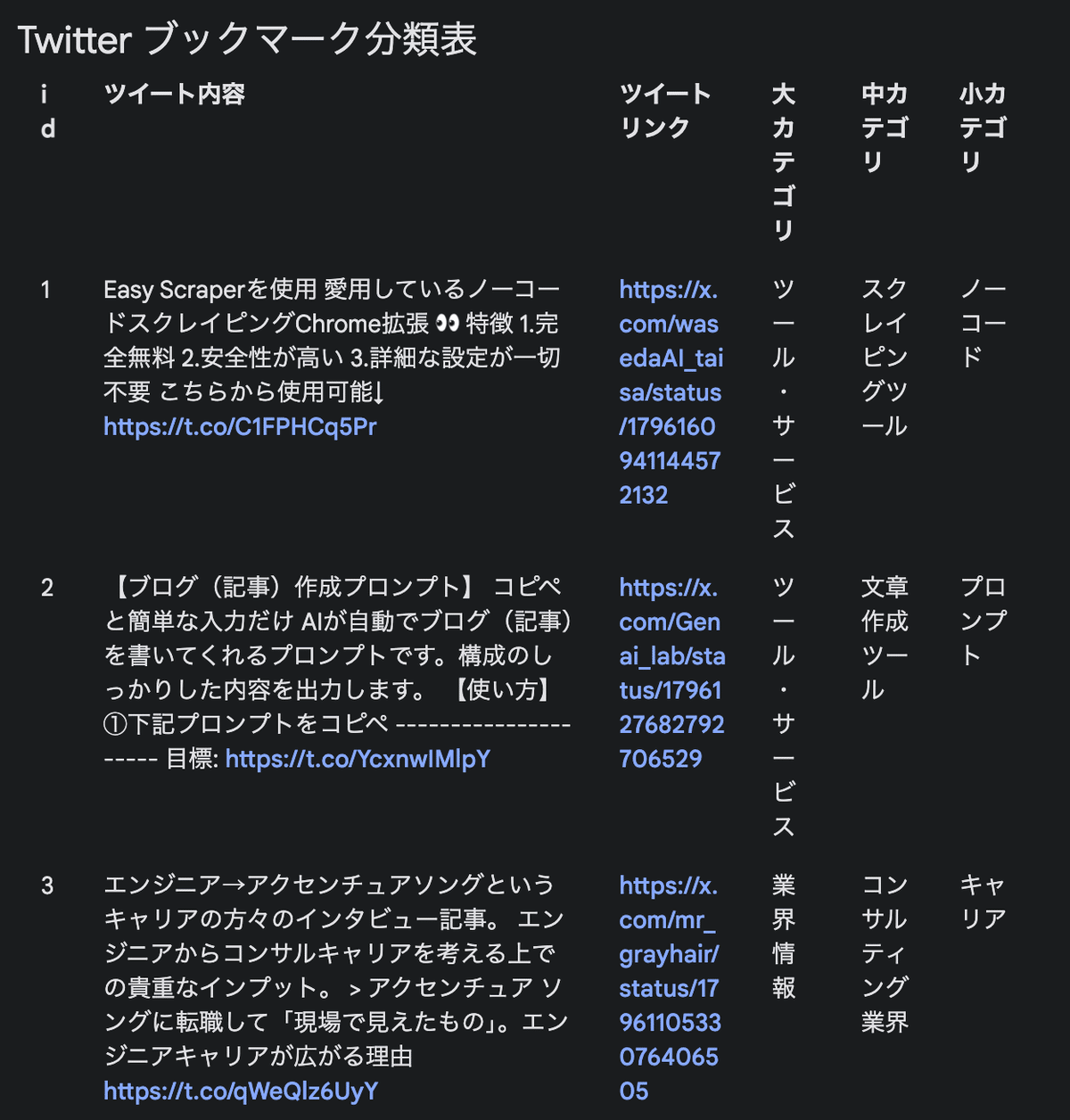
大体100-150ツイートくらいを一回で処理してくれます。
ここをもっと増やしたかった。。。
・注意
いくつか、注意があります。
・ツイートに「|」が含まれているとそこが表の区切りとみなされて崩れる
・たまにcsvファイルから正しく抽出してくれない(体感99%は正しく処理されます。似たようなツイートがあると混同してしまうようです。)
この場合は、後でスプレッドシートにコピペするときに手作業で直す必要があります。
継続プロンプト
処理が止まったら続きをお願いします。ここでもただ「続けてください」だと処理がうまくできなくなるまでの寿命が短くなります。
ありがとうございます。ここまで完璧です。
続き(id{続きのidを入力}から)をお願いします。
処理の前に「{あなたのファイルの名前}」を参照し、対応するidとツイートを必ず確認してください。
# 出力ルール
- 列は「id」「ツイート内容」「ツイートリンク」「大カテゴリ」「中カテゴリ」「小カテゴリ」です。
- Googleスプレッドシートにコピペするだけで表として認識されるようにしてください。
- 表は途中で途切れないようにしてください。二箇所ほど、手作業での入力が必要です。この作業をしないと全体の処理の繰り返し数が増えてしまうので、仕方ありませんが手作業をお願いします。
これを繰り返すと、大体1000ツイート目くらいまではほぼ完璧に抽出してくれます。
うまくいかない時
たまに連続してツイートを正しく抽出できなくなります。その時は継続プロンプトを書き換えてもっと工夫を施しても良いのですが、この継続プロンプトは僕がそれを繰り返して行き着いたものになっています。笑
従って、うまくいかないときは処理を止めて、モデルの出力を削除し、もう一度その回の出力を生成させるとうまくいくことがほとんどでした。
(1000ツイートを超えると6回やり直しても正しい抽出ができなくなり、限界と判断しました。)
4. csvファイルに貼り付け、エクスポート
もう一つだけ手作業が必要です。
Geminiが出力した表を選択し、Google Spreadsheetに貼り付けます。
おそらくそのままコピペで行けるはずです。
Geminiの出力にブレがある場合(表が崩れているなど)は、ここで整える必要があります。
5. あとは自由に
コピペが終わったら、あとはやりたい処理に応じた形式でエクスポートします。処理の例としては、以下のようなものがあります。
・NotionのDBに保存
Notionはcsvファイルをインポートしてデータベースにすることができます。
Notionを普段よく使う人はDBに保存するのもいいかもしれません。
・ChatGPTなどにcsvファイルとして渡して会話
冒頭のように、カテゴリごとのフォルダに分けて保存するには、カテゴリ付けしたスプレッドシートをcsvファイルで出力し、ChatGPTにカテゴリを参照してフォルダ分けしてもらいます。
その後はそのフォルダのいくつかを渡し、「ChatGPTのプロンプトに関するツイートは?」や「統計検定に役立つツイート教えて」などと聞くことができます。
得た知見
最後に今回の試行錯誤で得た知見をまとめます。
・数あるものからMECEに抽出するにはidを同時出力すると良い
今回のように大量にツイートをまとめたcsvファイルからMECEに抽出するにはそのidを同時に出力させることでより正確に処理を行えるようですね。
・Gemini 1.5 Proでも超長い処理はできない
1000件くらいが限界だったように、100万トークンを扱えるとは言っても僕のプロンプト術では限界があるようです。
ここはLLM自体の性能向上や、僕のプロンプト技術を向上させるしかないですね。
・処理は具体的に伝える
プロンプトで今回やりたいことを具体的に伝え、処理の順番まで伝えると精度が向上しました。やはり、具体的に伝えるべきなのでしょう。
また、処理の過程で何度か試行錯誤を繰り返して良いプロンプトを練りました。このようにプロンプトをより良くしていくのが良さそうです。
まとめ
今回は記事にまとめましたが、Xでは日頃から最新のAI・データサイエンス系の情報を発信しつつ、勉強記録も呟いています。
もっとリアルな情報を知りたい、頑張ってる人に刺激を受けたいという方はぜひ、覗いてみてください😌
X:@A7_data連絡をくだされば、いつでも対応させていただきます。
また、ぜひこの記事の感想をなんでも良いので教えていただけるととても嬉しいです!匿名が良い方は以下の質問箱にお願いします!
共に、日々1歩でも成長していきましょう🔥