
人間の動画を模倣してロボット学習:Vid2Robot

なにこれ

操作タスクのデモンストレーションビデオと現在の視覚的観察が与えられると、ロボットのアクションを直接生成
人間のビデオとロボットの軌跡の大規模なデータセットでトレーニングされた統一された表現モデルによって実現される
このモデルは、cross attentionを活用して、プロンプトビデオの特徴をロボットの現在の状態に融合し、観察されたタスクを模倣する適切なアクションを生成
さらに、政策性能を向上させるために、人間とロボットのビデオ表現の整合性を強化する補助的な損失を提案
人間のデモンストレーションビデオを使用した場合に、他のビデオ条件付き手法と比較して20%の性能向上
visual imitation learningという
Vid2Robot: End-to-end Video-conditioned Policy Learning with Cross-Attention Transformers
データセット

Robot-Robot: 異なる環境で同じタスクを実行している場合に2つのビデオを一致
RT-Xなどのデータ+アノテーションでできる
目的
すでのラベル付けされ収集されたロボットの軌跡データセットを活用
同じタスクが異なる環境でデモンストレーションされた場合でも、ロボットが模倣できるようにする
タスクは、ロボットの軌跡を記録するときに使用される自然言語の指示に基づいて定義
指示は通常、名詞を囲む1つまたは2つの動詞で構成され、「水のボトルを立てる」「コーラの缶を緑のチップバッグに移動する」「上の引き出しを開ける」など
Hindsight Human-Robot: ロボットの軌跡データセットのタスク指示を使用し、1〜5人の人間の参加者にそのタスクを実行させ、ロボットと同じ視点からデモンストレーションビデオを記録
新しいロボット軌跡を収集することなく、低コストでロボットデータセット内の指示セットに対するポリシーのトレーニングに必要な多くのペアデータを収集できる
Co-located Human-Robot: 人間とロボットが同じ作業空間で同じタスクを実行
理想的なデータだが収集コストが高い
モデルアーキテクチャ

Prompt Video Encoder:
以下のモデルがベース
フレームごとのイメージエンコーダー
ViT
Perceiver Resampler
Flamingo: a Visual Language Model for Few-Shot Learning
Goal-Conditioned End-to-End Visuomotor Control for Versatile Skill Primitives
N個のd次元トークンに動画を変換
Robot State Encoder: 現在のフレームと過去kフレームを入力として、ロボットの現在の状態をエンコード
アーキテクチャはプロンプトエンコーダとほぼ同じ
1と同じイメージエンコーダϕの重みを使用
State-Prompt Encoder: Cross Attention
Robot State EncodeをQ、Prompt Video EncodeをK, Vとしてcross attentionする
Robot State Encodeから必要な状態情報を取り出す
Robot Action Decoder: cross attentionで状態を受け取りアクションを予想する
前処理
ビデオの長さが異なることを考慮し、効率的にトレーニングするために、常に最初と最後のフレームを含めて、ランダムにN=16フレームをサンプリングし、それらを時間順に並べ替える
次に、直前のk-1フレームを選択し、合計でk=8フレームのロボット状態ビデオを作成します。もし現在のタイムステップ前にk-1フレームより少ない場合、固定サイズのロボット状態ビデオを作成するために最初のフレームを繰り返す
各フレームのピクセル値は0から1に正規化され、画像サイズは(224, 224)にリサイズ
アクションベクトルは、mode、gripper poseと閉じ具合、さらにベースの移動と回転を示す値で構成
それらの値を0から1の範囲にスケーリングして、各値を256のビンに離散化最終的には、[0, 255]の範囲で11次元のアクションベクトルとなる
学習

1以外のロスは過学習を防ぐため、プロンプトビデオの意味を理解するのに役立つ特徴を学習させるものである。よってポリシー学習には用いられず、State Encoderの学習に用いられる
1. アクション予測ロス
behavior cloningを行う
=単純にデータセットを用いて教師あり学習を行う
=クロスエントロピー

2. Video Alignment Loss
プロンプトV_pとロボットV_rビデオのフレームごとの画像埋め込みに適用
この損失を適用するために、画像エンコーダϕの空間次元からフレームごとの埋め込み出力を平均プールし、2層のMLPプロジェクタヘッドを適用 (alignment pooling layer)プロンプトビデオと同じタスクを実行しているロボットビデオ間で時間的な一致を促進する
temporal-cycle consistency loss (TCC) を用いる (One-Shot Imitation Learning)
同じタスクを実行する異なるエージェントのビデオでトレーニングした場合に、タスク進行をエンコードすることが示されている[Masked Visual Pre-training for Motor Control]
TCCの詳細
E_p(プロンプト)の各フレームの表現がE_r(ロボット)内に対応するものを持つべき(State Encoderの学習)
$${α_k}$$: プロンプトビデオの各フレームがロボットビデオ内の複数のフレームに対してどれだけ近いかを重み付きで計算
フレームの類似度に基づいてロボットビデオ内のフレーム $${E_r^k}$$ からの重み付き平均が計算され、ソフトネイバー $${E~prt\tilde{E}_{pr}^tE~prt }$$が得られる

計算されたソフトネイバーに対応するフレームを$${E_p}$$内で見つける。これはcycle-backと呼ばれ、式(1)と同様のソフトネイバー計算を行って$${ \hat{E}_{pr}^t}$$を取得し、理想的にはこれが元のフレーム$${t}$$と同じであるべき
よって$${t}$$とのMSEをとる
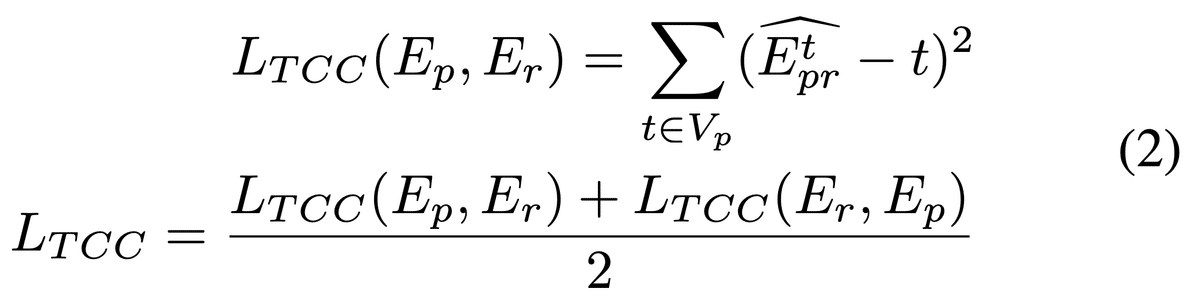
3. Prompt-Robot Video Contrastive Loss (VVCL)
同じタスクを実行しているprompt videoおよびrobot videoから生成されたプロンプトトークン間にContrastive Lossを適用
4. Video-text Contrastive Loss (VTCL)
プロンプトトークンZ_promptおよびロボットビデオZ_robotによって生成されたトークンと、タスクのテキスト指示の埋め込みZ_textとの間にContrastive Lossを追加
これにより、プロンプトビデオとロボットビデオ内のオブジェクト名や動詞に関連する部分が埋め込み空間で認識されるように促す。
実装
Jax
200K iterations
AdamW
lr: 8e-5
warmup: 200step, cosin
64個の潜在変数を持つ2つのPerceiver Resampler
state-prompt encoderおよびaction decoderは、それぞれ4層のcross-attention transformersで構成
実験

実験概要:
目標: Vid2Robotモデルを用いて、ロボットが人間のタスクを模倣できるかどうかを評価
課題: 人間とロボットの動作の違い(速度、スタイル)により、ロボットが人間の操作をどれだけ模倣できるかが問われる
評価方法: 各タスクについて、複数のロボットロールアウトを実行し、その成功率を測定。成功とは、タスクが正しく実行されること
評価指標:
Success Rate(成功率): プロンプト動画で示されたタスクをロールアウトで正しく実行できた割合
Overall Success Rate: 複数のタスクの成功率を平均したもの
Partial Success: 進捗度合いに応じてタスクの各ステップの成否を記録(例:オブジェクトに到達、正しく掴む、正しい位置に解放するなど)
評価設定:
環境の変化: 照明、オブジェクト、チェストなどが変化する中での評価。
ランダム化された初期状態: すべてのポリシー評価後に初期状態をランダムに設定。
比較モデル:
BC-Z: ResNet-18エンコーダを用いたビデオ条件付きポリシー。BC-Zは、ロボットの動作デモを使って学習するが、タスク終了制御がない。
結果:
タスク成功率(表 I):

結果1: Vid2RobotはBC-Zに比べて、人間のプロンプト動画で約20%高い成功率を示し、ロボットのプロンプトではほぼ同等の性能。
結果2: Vid2Robotは、特に「引き出しを開ける/閉める」や「引き出しから取り出してカウンターに置く」タスクで大きな改善を見せた。
部分的成功率(図6):
正しいオブジェクトへの到達: Vid2Robotは78%(BC-Zは70%)の成功率。
正しい掴み: Vid2Robotは65%、BC-Zは45%。
タスク終了時のリリースと終了: Vid2Robotは57%の成功率、BC-Zも同等。
クロスオブジェクトモーション転送(表 II):
見たことのないオブジェクトに対しても学習済みの操作を適用できるか評価


結果3: Vid2Robotはクロスオブジェクトモーション転送でBC-Zに対して優位性を示し、特に引き出しに物を入れるタスクで顕著な改善(29%→54%)。
結果4: Vid2Robotは、見たことのないオブジェクトに対しても学習済みの操作を適用できる
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?