
ComfyUIを入れるメモ

このメモを読むと
・ComfyUIを導入できる
・画像生成を試せる
検証環境
・OS : Windows11
・Mem : 64GB
・GPU : GeForce RTX™ 4090
・ローカル(pyenv+venv)
・python 3.10.12
・2024/8/B時点
ComfyUI
主に画像生成AIの作業を視覚的に管理できるようにしたツール。
拡張機能を追加した高度な画像生成も直感的に行えるようです。
今回は最小単位での動作確認を目標に、試してみましょう!
事前準備
環境構築
とても簡単です!
※ PCの環境によって構築手順が異なります。
Windows + NVIDIA製GPUの場合は、zipを
ダウンロードするだけのお手軽な方法があります。
しかし、せっかくなのでCLIからインストールしてみます。
1. リポジトリをインストールし、ディレクトリ移動
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI2. 仮想環境を作成し、環境切替
python -m venv .venv
.venv\scripts\activate3. 追加パッケージのインストール
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu124
pip install -r requirements.txt完了です!
ComfyUIを動かしてみる
画像を生成してみましょう。
1. 追加ファイルのダウンロード
こちら(Hugging Face) から下記をダウンロードします。
・sd_xl_base_1.0.safetensors (6.94GB)

2. 追加ファイルの格納
ダウンロードしたファイルを下記の構成で格納します。
ComfyUI
└─ models
└─ checkpoints
└─ sd_xl_base_1.0.safetensors
3. 下記コマンドにて、ComfyUIを起動
python main.py4. http://127.0.0.1:8188 をクリックしWebUIを起動
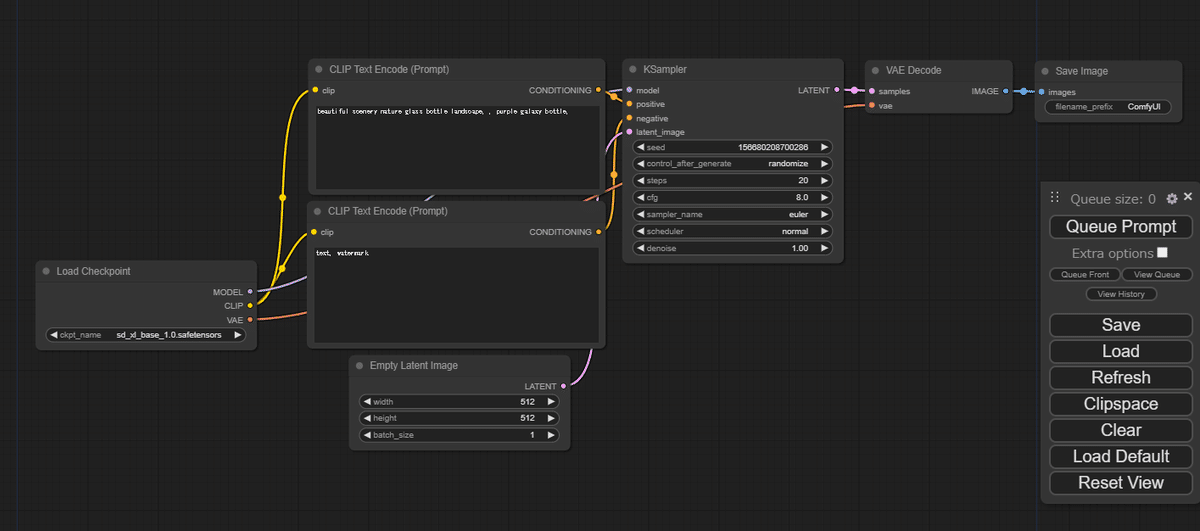
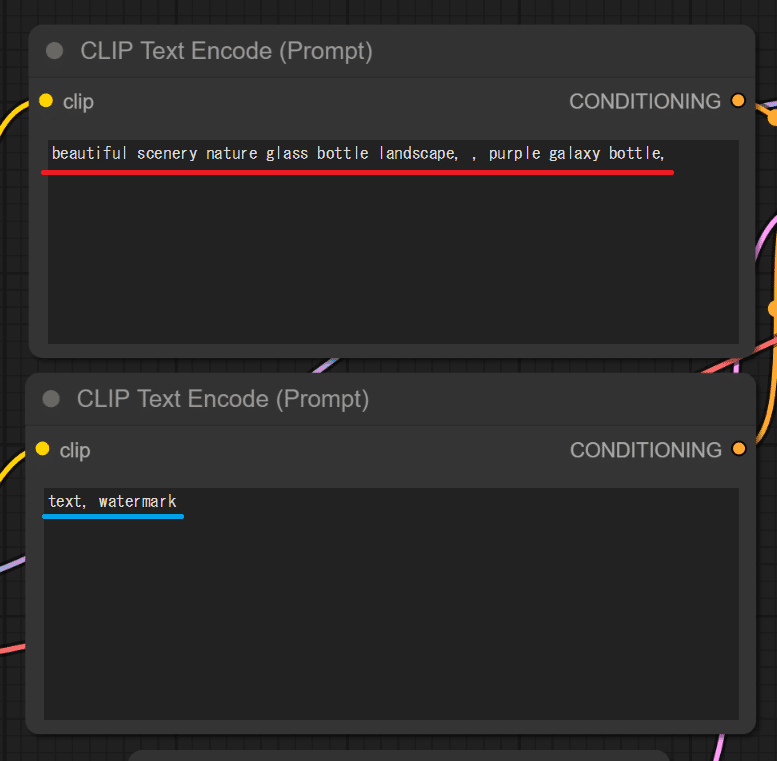
5. モデル(checkpoint)を選択し、好きな生成文(prompt)を記述

6. 生成開始

7. できた

./output へ成果物が格納されます。
おまけ
こんなエラーが出たら
OSError: [WinError 126] 指定されたモジュールが見つかりません。 Error loading "C:\Users\owner\AppData\Local\Temp\pip-build-env-4mypfhm_\overlay\Lib\site-packages\torch\lib\fbgemm.dll" or one of its dependencies.
1. こちらから libomp140.x86_64_x86-64.zip をDLし解凍
2. C:\Windows\System32 へ libomp140.x86_64.dll を格納
これでエラーがなくなります。
おわり
ComfyUIで画像を生成できた。
直感的でお手軽です!
SDXLはVRAM16GB以上が推奨されているモデルでしたが、
ComfyUIでは8GB程度で生成できました。
おしょうしな
参考にさせていただきました。ありがとうございました。