
Convolution + AveragePoolingのAIモデルに対してAffineのパラメータ設定の影響を調べてみた

今回はAffineのパラメータを設定した結果を確認します
今回の記事では、Convolution + AveragePoolingのAIモデルに対して、Affineのパラメータ設定をアレコレ設定した場合にどうなるかを確認します。
対象のAIモデルの構造図は、以下の通りです。

上図のAIモデルの構造図において、ConvolutionレイヤーとAveragePoolingレイヤーの設定は、以下の通りです。
Convolutionレイヤーのパラメータ設定値
OutMaps → 2
KernelShape → 80
BorderMode → valid
Strides → 1
Dilation → 1
Group → 1(デフォルト値)
ChannelLast → False(デフォルト値)
BaseAxis → 0(デフォルト値)
WithBias → True(デフォルト値)
ParameterScope → Convolustion(デフォルト値)
W.File → 未設定(デフォルト値)
W.Initializer → NormalConvolutionGlorot(デフォルト値)
W.InitializerMultiplier → 1(デフォルト値)
W.LRateMultiplier → 1(デフォルト値)
b.File → 未設定(デフォルト値)
b.Initializer → Constant(デフォルト値)
b.InitializerMultiplier → 0(デフォルト値)
b.LRateMultiplier → 1(デフォルト値)
AveragePoolingレイヤーのパラメータ設定値
KernelShape → 1,80
Strides → 1,80
IgnoreBorder → True
Padding → 0,0(デフォルト値)
ChannelLast → False
IncludingPad → False
パラメータを設定する対象のAffineレイヤーは、Affine_1とAffine_2です。
Affine_3が対象外なのは、AIモデルの出力が0か1の1ビットであるため、パラメータを1に固定する必要があるからです。
また、AIモデルの学習および評価に使用する説明変数と目的変数は、これまでと同じく、以下の通りです。
説明変数: 30日分の日経平均株価(始値、高値、安値、終値)およびVIX指数(始値、高値、安値、終値)
目的変数: 翌営業日の日経平均株価のローソク足が陽線か陰線かを表す0(陰線) or 1(陽線)のデータ
Affineのパラメータ設定と予測精度の関係について
下記に、Affineのパラメータ設定と予測精度(ACC)の関係を示します。
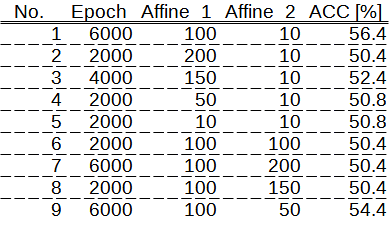
これまでの経験から、AIモデルの構造は、キュッ、ボン、キュッが良いと思われます。
最初のキュッは、AveragePoolingの出力である高さ2, 幅2のデータサイズです。
次のボンは、Affine_1のデータサイズで、最後のキュッはAffine_2のデータサイズです。
今回の検証結果は、私のこれまでの経験を裏付けるものとなりました。
No. 1を除くと、キュッ、ボン、キュッの構造に近いのは、No. 2, 3, 4, 9ですが、予測精度の観点から、どれもイマイチでした。
理由は分かりませんが、100 → 10のつながりが良いようです。
Affineのパラメータ設定と学習曲線の関係について
続いて、No. 1~9の条件における学習曲線を以下に示します。





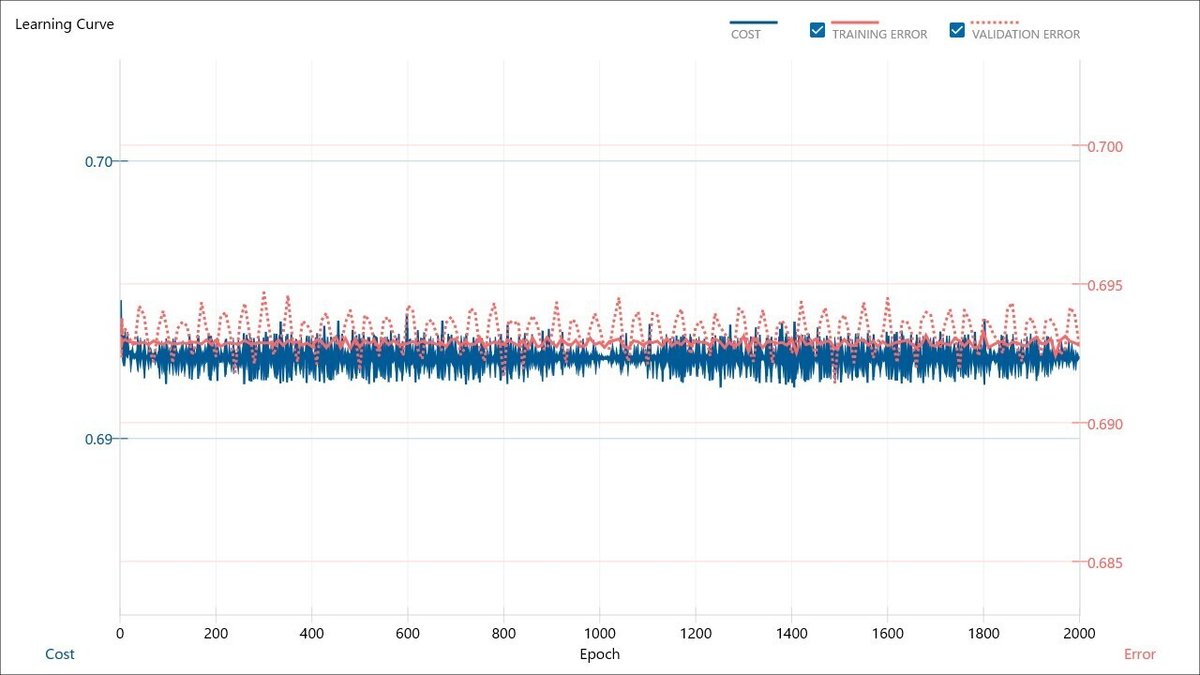



VALIDATION ERRORの最小値
No. 1 → 0.666236
No. 2 → 0.690939
No. 3 → 0.682109
No. 4 → 0.687369
No. 5 → 0.690720
No. 6 → 0.691445
No. 7 → 0.691693
No. 8 → 0.691450
No. 9 → 0.682402
No. 1の学習曲線を基準とした場合に、Affine_1およびAffine_2のパラメータを変更することで、過学習が進んだり、そもそもAIモデルの学習が全く進まなかったりすることが確認できました。
No. 6, 7, 8は、Affine_1のパラメータ設定が100であるのに対して、Affine_2のパラメータ設定が100以上のケースですが、AIモデルの学習が全く進みませんでした。
Affineのパラメータ設定と混同行列の関係について
最後に、No. 1~20の条件における混同行列を以下に示します。
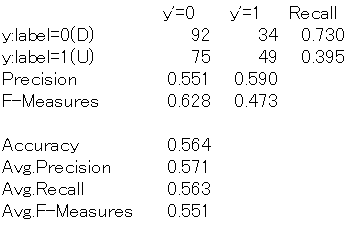







混同行列では、AIモデルの予測がy'=0あるいはy'=1の何れかに偏っているのがNo. 2, 5, 6, 7, 8でした。
各ケースでのAffineの設定値を確認すると、以下の通りです。
No. 2(Affine_1, Affine_2) → 200, 10
No. 5(Affine_1, Affine_2) → 10, 10
No. 6(Affine_1, Affine_2) → 100, 100
No. 7(Affine_1, Affine_2) → 100, 200
No. 8(Affine_1, Affine_2) → 100, 150
ハッキリしたことは読み取れませんが、私の理解は次の通りです。
Affine_1とAffine_2は、Affine_1 > Affine_2の関係が成り立つ必要がある
ただし、Affine_1とAffine_2の差が大きすぎても良くない
結果に対する感想
それにしても、AIモデルの学習は進むものの、VALIDATION ERRORは全く低下しない状況が続いています。
学習が進むということは、学習データに対してAIモデルの最適化が行われているということです。
一方で、VALIDATION ERRORが低下しないというのは、学習データに最適化されたAIモデルに評価データをインプットすると、エラーが多発するということです。
それはつまり、評価データに含まれる特徴が学習データに含まれていないということではないかと私は考えます。
ちなみに、現状の学習データと評価データは、以下のようになっています。
学習データ
期間: 1990-01-04 ~ 2022-11-14
評価データ
期間: 2022-11-15 ~ 2023-11-17
学習データおよび評価データ共通
説明変数: 日経平均株価(始値、高値、安値、終値)とVIX指数(始値、高値、安値、終値)の30日分
目的変数: 0(翌営業日の日経平均株価が陰線) or 1(翌営業日の日経平均株価が陽線)
どうすべきか悩ましい状況ですので、久しぶりにChatGPTの知恵を借りようと思います。