
ConvolutionレイヤーとPoolingレイヤーのパラメータをアレコレ設定するとどうなるの? AveragePooling編

ConvolutionレイヤーとAveragePoolingレイヤーを組み合わせて各パラメータと予測精度、等の関係を確認します
今回は、ConvolutionレイヤーとAveragePoolingレイヤーのパラメータをアレコレ設定したらどうなるのかを確認します。
確認する内容
予測精度
学習曲線
混同行列
ちなみに、ConvolutionレイヤーおよびMaxPoolingレイヤーの組み合わせに対する各パラメータ設定の検証結果は、前回の記事を参照ください。
Convolutionレイヤーの各パラメータ設定値は、以下の通りです。
Convolutionレイヤーのパラメータ設定値
OutMaps → アレコレ設定します
KernelShape → アレコレ設定します(ただし、1次元に限定)
BorderMode → valid
Strides → 1
Dilation → 1
Group → 1(デフォルト値)
ChannelLast → False(デフォルト値)
BaseAxis → 0(デフォルト値)
WithBias → True(デフォルト値)
ParameterScope → Convolustion(デフォルト値)
W.File → 未設定(デフォルト値)
W.Initializer → NormalConvolutionGlorot(デフォルト値)
W.InitializerMultiplier → 1(デフォルト値)
W.LRateMultiplier → 1(デフォルト値)
b.File → 未設定(デフォルト値)
b.Initializer → Constant(デフォルト値)
b.InitializerMultiplier → 0(デフォルト値)
b.LRateMultiplier → 1(デフォルト値)
AveragePoolingレイヤーの各パラメータ設定値は、次の通りです。
AveragePoolingレイヤーのパラメータ設定値
KernelShape → アレコレ設定します(ただし、1次元に限定)
Strides → KernelShapeと同じ設定値を使用します
IgnoreBorder → True
Padding → 0,0(デフォルト値)
ChannelLast → False
IncludingPad → False
AveragePoolingレイヤーのパラメータに、MaxPoolingレイヤーでは存在しなかったIncludingPadが存在します。
IncludingPadは、Neural Network Consoleのオンラインマニュアルにも記載がないため、機能については分かりません。
このため、IncludingPadの影響を抑える目的で、今回はFalseとしました。
AIモデルの構成
今回の確認で使用するAIモデルの構成は、下記の通りです。

Inputレイヤーに入力する説明変数は、30日分の日経平均株価(始値、高値、安値、終値)およびVIX指数(始値、高値、安値、終値)です。
また、目的変数は、翌営業日の日経平均株価のローソク足が陽線か陰線かを表す0(陰線) or 1(陽線)のデータです。
ConvolutionレイヤーおよびAveragePoolingレイヤーの各パラメータ設定と予測精度の関係について
下記に、ConvolutionレイヤーおよびAveragePoolingレイヤーの各パラメータ設定と予測精度(ACC)の関係を示します。

予測精度が最も高いのは、No. 7の58.0%でした。
ちなみに、これまでの予測精度の最高値は58.4%ですので、それに近い数値となります。
また、予測精度が最も低いのは、No. 5の49.2%でした。
ConvolutionレイヤーおよびAveragePoolingレイヤーの各パラメータ設定と学習曲線の関係について
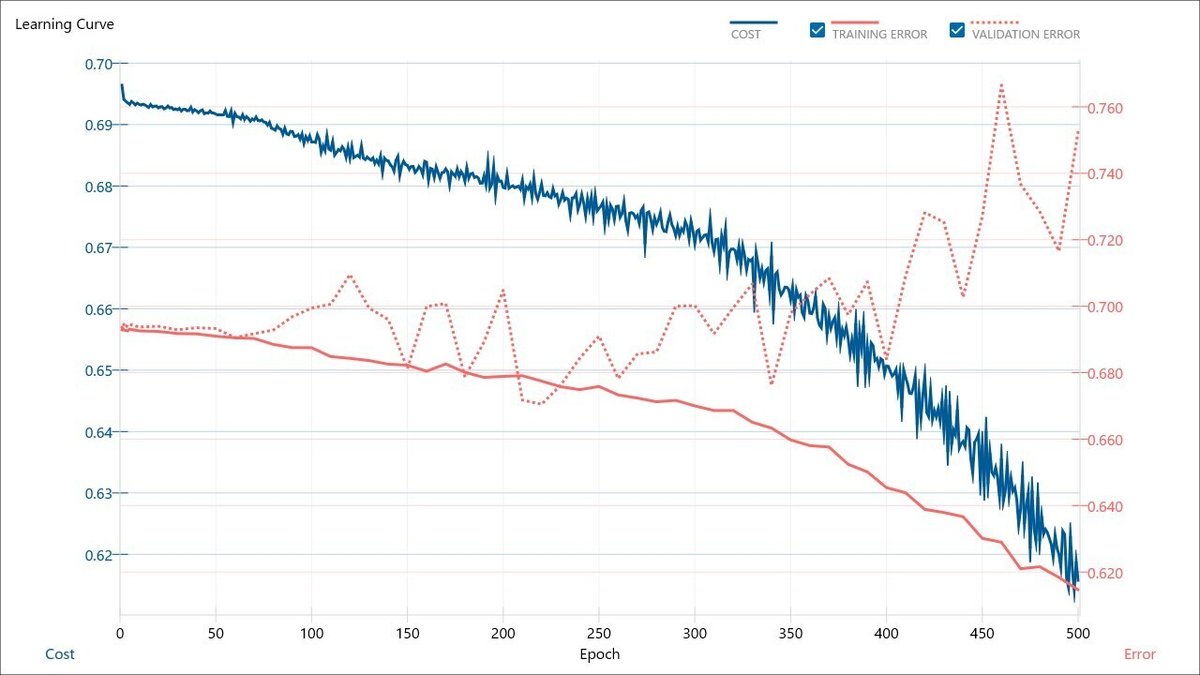
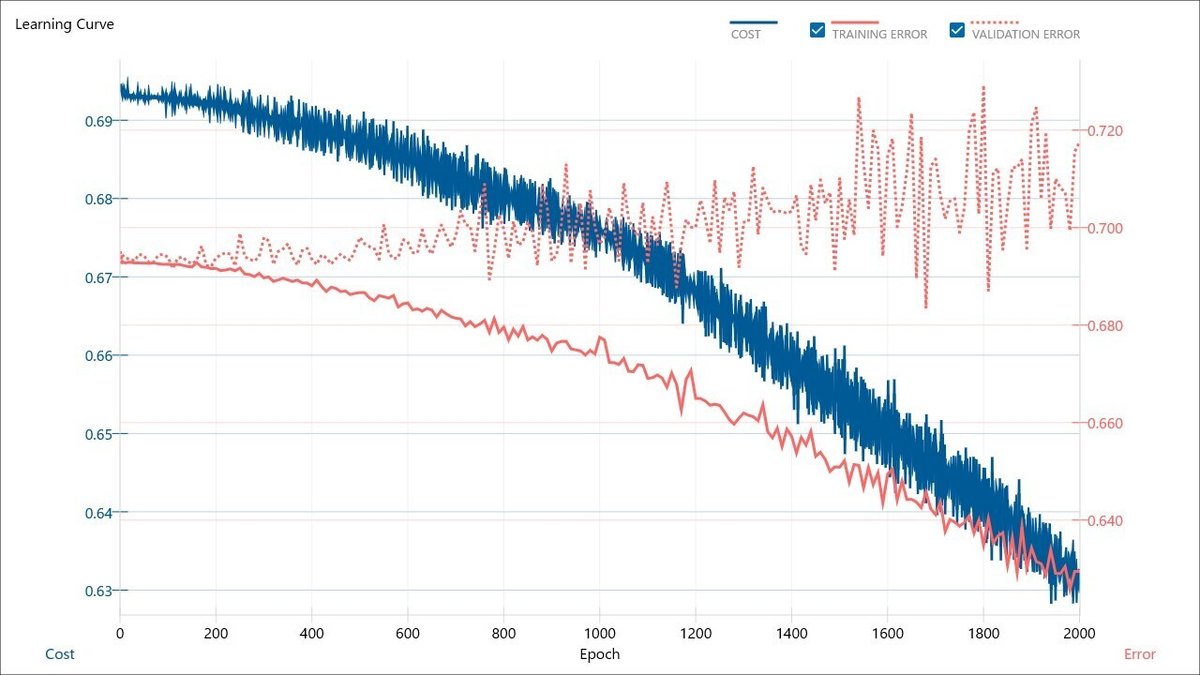
続いて、No. 1~20の条件における学習曲線を以下に示します。


















VALIDATION ERRORの最小値
No. 1 → 0.687357
No. 2 → 0.690776
No. 3 → 0.684326
No. 4 → 0.689254
No. 5 → 0.692470
No. 6 → 0.688724
No. 7 → 0.670504
No. 8 → 0.688365
No. 9 → 0.688880
No. 10 → 0.691052
No. 11 → 0.681332
No. 12 → 0.684718
No. 13 → 0.691641
No. 14 → 0.688593
No. 15 → 0.683443
No. 16 → 0.689396
No. 17 → 0.692010
No. 18 → 0.680783
No. 19 → 0.688185
No. 20 → 0.666236
最も予測精度が高かったNo. 7の学習曲線は、過学習が進んでいるのが確認できます。
また、VALIDATION ERRORの最小値が最も小さかったNo. 20の学習曲線は、AIモデルの学習は進みつつも、過学習が抑えられていて、何だか良さそうです。
今回の検証における学習曲線に対して、過学習が進むものと進まないものに分けると、下記の通りです。
過学習が進むもの
No. 5, 6, 7, 8, 11, 12, 13, 14, 15, 17, 18, 19
過学習が進まないもの
No. 1, 2, 3, 4, 9, 10, 16, 20
ConvolutionレイヤーおよびAveragePoolingレイヤーの各パラメータ設定と混同行列の関係について
最後に、No. 1~20の条件における混同行列を以下に示します。




















最も予測精度が高かったNo. 7の混同行列を見ると、AIモデルの予測がy'=0とy'=1にそれなりにバランス良く分布しているのが確認できます。
y'=0 → 明日の日経平均株価のローソク足は陰線と予測
y'=1 → 明日の日経平均株価のローソク足は陽線と予測
AIモデルの予測が、y'=0 or y'=1に偏っているかいないかで整理すると、以下の通りです。
AIモデルの予測が、y'=0 or y'=1に偏っている
No. 3, 13, 17, 19
AIモデルの予測が、y'=0 or y'=1に偏っていない
No. 1, 2, 4, 5, 6, 7, 8, 9, 10, 11, 12, 14, 15, 16, 18, 20
ほとんどの条件において、AIモデルの予測がy'=0 or y'=1に偏っていないことが確認できました。
前回の記事で検証したConvolutionレイヤーとMaxPoolingレイヤーの組み合わせでは、全20条件の内8つの条件でAIモデルの予測がy'=0 or y'=1に偏っていました。
この結果から、PoolingにはAveragePoolingを使用するのが良さそうです。
結果に対する考察
学習曲線において、No. 20の結果は、非常に気になります。
その理由は、AIモデルの学習は進んでいて、かつ、VALIDATION ERRORの上昇も抑えられているからです。
しかし、No. 20での予測精度は56.4%と、それなりではあるものの、最高値である58.0%には届いていません。
もしかしたら、説明変数を変更したり、Affineレイヤーのパラメーター設定を調整したりすることで、予測精度の改善が可能かもしれません。
また、混同行列におけるAIモデルの予測のバラつき度合いより、Poolingは、MaxPoolingよりもAveragePoolingの方が良さそうだと分かりました。
以上を整理すると、下記の通りです。
1D CNNでは、AveragePoolingを使用する
No. 20の構成で、説明変数の影響を確認する
No. 20の構成に対して、Affineのパラメーター設定による影響を確認する
1D CNN + LSTM構造のAIモデルを使用した評価を行う
次回は、No. 20の構成に対して、Affineのパラメーター設定による影響を確認したいと思います。