
実践的ジョブ理論④ 〜ユーザーインタビューの分析方法

外資系IT企業でプロダクトマネージャーをしています、ハヤカワです。
日々、Twitterでプロダクトマネージャーのノウハウや考え方などを発信しています。
⚡️ “プロダクトマネージャーのあれこれ”https://t.co/o4Ki7dMhRB
— Kazuki Hayakawa☁️AI製品のPM (@kzkHykw1991) July 23, 2020
今回は、ジョブ理論の考え方を実践しよう!というのを目指した「実践的ジョブ理論」の第4弾です🎉🎉🎉
ジョブ理論って聞いたことあるけど、なんだっけ???という方はまずはこちらをご覧ください🙌
このジョブ理論の考え方にもとづいて、実際にプロダクトマネージャーの業務でこの考え方を使うためにはどうすればよいのか?🤔と考えて作ったのがこの「実践的ジョブ理論」というnoteシリーズです。
そして、今回ご紹介するのはシリーズ④「ユーザーインタビューの分析方法」についてです👏
今回もGoogle Slideで作ったスライドをベースに説明していきます!
0. はじめに ✍️
ジョブ理論そのものや、ユーザーインタビューの目的ややり方については実践的ジョブ理論②で解説したので、まだの方はぜひはじめにご覧ください👀
ユーザーインタビューの目的は「顧客の実際の声を聞き、顧客が本当に求めていることを明らかにする」ということです。
1. インタビューの分析方法について 📝
それでは早速、ユーザーインタビューの分析方法について解説していこうと思います。
突然ですが、みなさんはこんな形でインタビューを行っていませんか?

なんとなくで場当たり的で、雑談のようなユーザーインタビューをおこなって、思ってた通りの課題があったとか共通点があったとか決めつけて、最終的には、結局もともと頭の中にあったアイデアをもとに作りたいものを作ってしまう・・・たしかにユーザーインタビューを行っているものの、顧客の声に基づいたものではなく、CEOやPMが作りたいものをただ作っているだけになります。
一方で、そういうのは良くないので、さまざまな分析方法が語られていますが・・・

という傾向があるのではないでしょうか?
しかし、プロダクトマネージャーとしては、できるだけ主観を排除してデータに基づいて意思決定することが求められます。

そこで、使えるのがGTA・・・

ではなく、「グランデッド・セオリー・アプローチ」です

今回はそんなGTAという質的調査手法について解説していきます👏
2. 🧪 GTAによるユーザーインタビューの分析
GTAでは、その名の通りデータに基づいて、分析を行い、何かしらの現象やプロセスを理論として示すことができます。

この考え方が、ジョブ理論のコンセプトに合致しており、ジョブ理論と非常に相性の良い質的調査手法であると個人的に考えています。
さらに、データに基づいた分析にはこのようなメリットがあります。

特に、ソフトウェアの開発やプロダクトマネジメントの世界では、データドリブンの分析や意思決定が必要不可欠になります。
ここから先は、ユーザーインタビューをデータ化する手順について紹介します。正直、かなり時間と労力を使う大変な作業になります🤯
ここまでで「いやいや、今まで通り経験と勘でインタビューを行って、自分たちが作りたいものを作っていくんだ!」という方はそっとお戻りください🙇
3. 実際にインタビューをGTAで分析してみよう!

さて、インタビューをちゃんと分析してみたい!という方向けに、実際にGTAを使ってユーザーインタビュー内容を分析する方法を説明します。
GTAでは大きく分けて、3つのステップ、①データ化、②抽象化、③関連付けを行って、インタビュー動画をデータ化しながら主観を排除した分析をおこなっていきます。

いくつか、専門用語がありますが、この後解説します。GTAのポイントは、何度も抽象化を行い、関連性を考察し、インタビューを1人するごとにこの分析を繰り返すという方法であるということです。
それでは、もう少し具体的に分析手順を見ていきます。
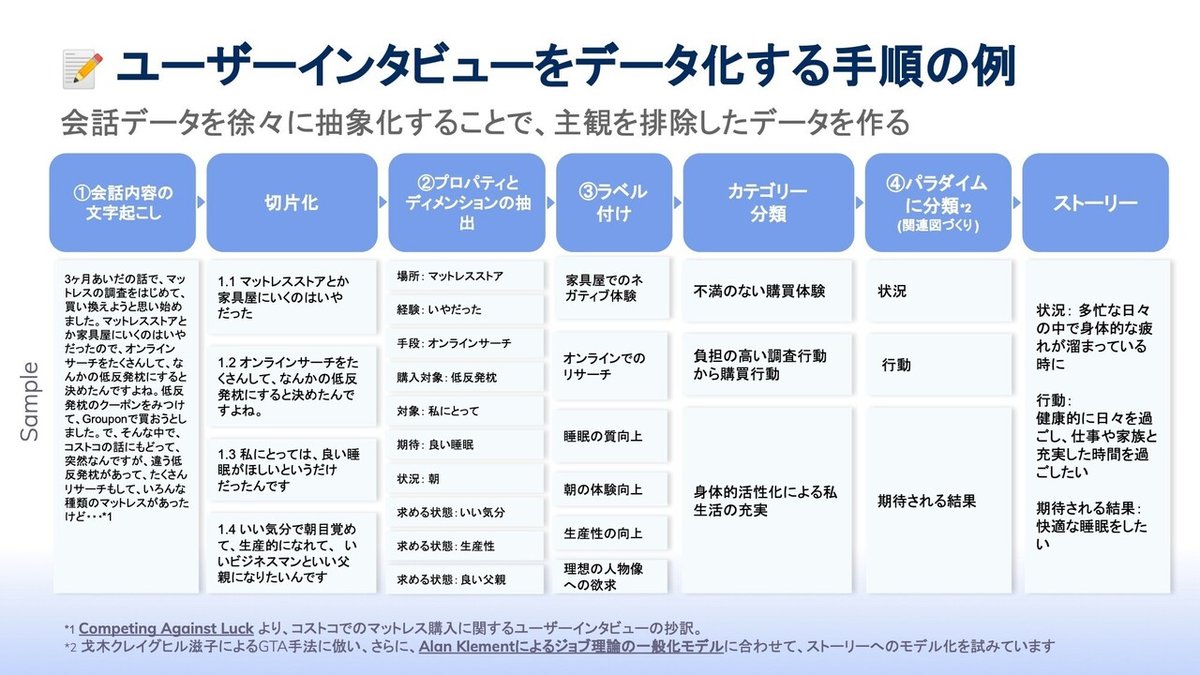
大きな流れとしては、インタビュー動画の文字起こしを行い、テキストを細かく分割し、それぞれに対して、要素を抽出し、分類することで抽象化(ラベルとカテゴリー、パラダイム)し、整理して分析するという手順になります。
それでは、それぞれの方法を見ていきましょう!
と、その前にインタビュー前の前提をご確認ください

上記のスライドの説明がよくわからない方は、ジョブの仮説作りやインタビューそのものを解説している下記のnoteをご覧ください!
①インタビュー動画からデータを作ろう!
それではさっそく、インタビュー内容を分析していきます。まず最初にやることはインタビュー動画を文字起こしして、テキストデータを作る作業です。

インタビュー動画の文字起こしは、任意の文字起こしアプリまたは、内容が多くない場合は人手による文字起こしを行います。
ただし、経験上1時間のインタビューでは、2万文字以上のテキストデータができるため、手動だけだとめちゃくちゃきついです。
私は、AmazonのTranscribe APIによる文字起こし方法について、notionでメモ程度にまとめてるのでご覧ください
https://www.notion.so/fa7d623178ba442890104c30371dd2c4
インタビュー動画を自動で文字起こしすれば、テキストデータを得られるのですが、実はそれだけではありません。インタビューの前、中、後のさまざまなことを観察し、インタビュー対象者の人的環境や、インタビュー中の非言語情報などの付加情報を観察データとして記載することも欠かせません。
また、GTAでは分析者によって解釈や捉え方、判断の根拠もさまざまになります。だからといって、そういうものを記載しないというのは、データとして十分ではありません。データドリブンのアプローチにおいては、いくら頑張って考察していたとしても、データとして存在しないものは、世の中に存在しないことと同義なので、いかなる情報でもまずはテキストに起こして、データとして存在させましょう

②プロパティとディメンションを抽出しよう!
次に、文字に起こした発言データと観察データそれぞれに対して、要素を抽出します。

発言データと観察データからはプロパティとディメンションという2つの要素を抽出する必要あがります。
プロパティは、データから考えられる情報の箱 = 変数 (5W1Hで抜き出せる)
ディメンションは、その箱に入る情報 = 値
まずはこの5W1Hの観点で、テキストを読み込みます。
たとえば、この発言にはWhereの観点があるな?とか、人について言及しているからWhoで、これは方法について話しているから、Howだな?とか考えて、プロパティとディメンションの要素を書き込んでいきます。
抽出の判断は、文脈やテキスト全体から切り離して、切片化された1つのデータのみを見て、考えられる要素をできるだけ多く書き出します。
最初はこの作業がとても難しく感じると思います。1つのテキストを読み込んで、そこからどのような5W1Hの観点が含まれているのかを分析者の解釈によって抽出しなければいけないからです。そのため、一定の知識と経験が必要になります。
そこで、まずは簡単で身近な例でインタビューを繰り返し練習しましょう。ここばかりは何度も試してみる、という経験が必要になります💪
③データを抽象化しよう!
次に、抽出したプロパティとディメンションを使って、ラベル付け、カテゴリー分けなどの抽象化の作業を行います。

まずはじめに、テキストに対して抽出したプロパティ、ディメンションで出てきた言葉を組み合わせて、そのテキストから得られる事実やインサイト、気付き、課題やニーズなどを抽象化します。つまり、切片化した1組の発言+観察データに対して、1つのラベルをつけていきます。
次に、関連するラベルをまとめて、一つの表現でまとめたカテゴリーに分類します。カテゴリーの表現は、複数のラベルを抽象度高く表現した、簡潔な表現で行います。複数のラベルを1つのカテゴリーでまとめていきます。
最後に、パラダイムと呼ばれる、状況、行動、結果からなる3つのパターンにそれぞれのカテゴリーを分類します。
これによって、1人のインタビュー動画から、その人の過去の経験に基づいた、何かしら直面した状況と、それに対して取った行動、それによって起きた結果を整理することができました。
次に、ここまで整理したものを図で書き起こします。
④カテゴリー関連図を描こう
ここまでやると1人のインタビュー動画から、複数のカテゴリーと複数の状況、行動、結果が分類されます。このままでは、それらが並んでいるだけなので、それぞれの関係性を可視化するために、図に起こしてみます。

書き方としては、右上の凡例を見てください。ここまで分類してきた、すべての要素、プロパティ、ディメンション、ラベル、カテゴリー、パラダイムを1つのブロックに分けることができます。
そして、ブロック同士を矢印で結ぶことでその関係性を可視化します。
ここで、注意するのはそれぞれの関係性は時系列ではなく、変化のプロセスで繋がっているという点です。何かしらの状況から、プロパティとの変化が起き、それに対してどういう行動を取ったか、そしてどういう結果を生んだのか?この変化のプロセスを図に起こすことになります。
また、一つのカテゴリー関連図には、状況は1つしか存在しません。つまり、インタビュー内容から複数の状況が出てきた場合は、その分だけカテゴリー関連図を作る必要があります。
⑤分析と考察をおこない、次のインタビューを行う
カテゴリー関連図を描くと、下記のようなことに気づけます。
特に、インタビューで聞くことができた、プロパティとディメンションの逆の要素を考えると、What if, もしこうだったら、ユーザーはどう行動するだろう?という観点を見つけることができます。

これらのポイントを分析すると、ジョブの仮説証明に重要な点と仮説証明に不足している点に気づけます。
そして、上記を補完する質問項目を追加し、次に誰に聞けば、上記の重要な点と不足している点を更に聞くことができるのか?という点で、次のインタビュー対象者を選択することができます。 (このことを理論的サンプリングといいます)
つまり、闇雲にユーザーを集めて、ひたするインタビューするのではなく、インタビューしては分析を行うことで、最小限のインタビューで、正確に理論の構築を行うことができます。
だからこそ、最初に説明したように、一気にインタビューを行うのではなく、インタビューと分析を交互に繰り返すことが、GTA分析の基本になります。
本来であれば、理論的飽和と呼ばれる、これ以上聞いてもあたらしいインサイトがない状態までインタビューを繰り返します。
ただし、実際のビジネスにおいては時間やコストの制約があります。そこで、仮説の範囲にもよりますが、だいたい10-20人くらいのインタビューを行うことで、十分なデータが集まると考えられます。
最後に、複数人のインタビューを行い、複数のカテゴリー関連図を作成したあとの、分析方法について説明します。

⑥インタビュー結果からジョブを作成する
複数人のインタビューの後、完成したカテゴリー関連図から、ユーザーが取っている行動パターンをストーリーとして解釈します。そこで出てきたストーリーをジョブ理論の記述に書き直すことで、ジョブを定義していきます。

最初に述べたように、GTAによる分析ではユーザーの変化のプロセスをみつけることができます。
そして、ジョブ理論では、ユーザーは何かしらの変化、進捗(Progress)を求めて、行動を取る、という基本的な考え方があります。
つまり、GTAによる分析結果から、ユーザーはどういう進捗を求めて、どのような行動を取っているかというジョブを見つけることができます。
カテゴリー関連図の行動や結果に記載されているデータから、ユーザーの行動を促す、動機や行動の結果から得られるアウトカムが何なのか?というジョブ理論の記述方法に言葉を変換する必要があります。
👀カテゴリー関連図からジョブへの変換は、より再現性が高い、主観をとりのぞいた手法がないかな?と考えているので、もし意見やコメントがある方は教えて下さい!
長くなってしまったので、ジョブの整理や分析、優先順位付けなどについては、次回紹介したいと思います。
実践的ジョブ理論を使った後は?
この実践的ジョブ理論を用いて考えた仮説を立てたジョブ仮説について、正しく書けているか?ちゃんと検証できているか?を評価してくれるツールも作ったので、ぜひ利用してみてください!
さいごに
もちろん、今回紹介した内容はとても時間と労力がかかる作業になります。すべての機能アイデアでこれを行うことは現実的ではないかもしれません。
しかし、1製品を作る上でジョブ理論とインタビュー分析を、全く無視してプロダクトを作ることは、完全に博打です。博打でも良い場合は好きなものを作るべきですが、できるだけ顧客にとって良いプロダクトを作りたい場合に、顧客の声に基づいて作るべきものを決められる実践的ジョブ理論が役に立てば嬉しいです。
実践的ジョブ理論のフレームワークを配布
実際に自分でも実践的ジョブ理論を試してみたいな、と思った方向けに「実践ジョブ理論フレームワーク」を、有料ではありますが本noteでダウンロードできます!🙇

このシート、第一弾の実践的ジョブ理論の記事でも公開したのですが、さらにバージョンアップを加え、今回紹介したユーザーインタビューシートやGTAの分析シートも入っています!
さいごに、この記事が良かったと思う方は、Twitterのフォロー(@kzkHykw1991)、noteのスキ、そして「実践ジョブ理論フレームワーク」のダウンロードをおねがいします!🙇
追記:2021/12/31
今年1年間このnoteを販売させていただいて、多くの方にダウンロードいただきました。もっと多くの方にお使いいただくために、価格を値下げして販売したいと思います!
¥1500 → ¥980
追記: 2022/08/06
本有料noteをご購入いただいた皆さんに、この実践的ジョブ理論テンプレートをさらに発展させて開発したサービス「Value Assessor」(仮説検証のためのプロダクトマネジメント支援ツール)を無料でご利用いただけるキャンペーンをご用意しました!
ご興味のある方は、下記のDiscordに参加いただき、自己紹介チャンネルで、noteを購入していただいたアカウント名と、Value Assessorをご利用してみたい旨をご連絡ください!
それでは、より良いプロダクト開発を!
🔗実践的ジョブ理論フレームワークのダウンロードリンク↓
購入いただくとリンクが見えるようになります。
🚨「実践的ジョブ理論①」「実践的ジョブ理論②」と同様のファイルですので、前回noteをご購入済の方はご購入されないようご注意ください!
ここから先は
¥ 980
この記事が気に入ったらサポートをしてみませんか?