【読書好き】書籍!TSUTAYAからコミックの情報をスクレイピング

TSUTAYAとは?
TSUTAYA オンラインショッピングとは、本(漫画・雑誌・写真集)、映画・ライブ映像のDVD、音楽アルバム、ゲーム、アニメまでTポイントが使える・貯まる通販サイトです。さまざまな特典やおすすめの最新情報・予約受付、ランキングやニュースなど盛りだくさん!長年にわたり日本国内のエンターテインメントとメディアコンテンツの提供に重要な役割を果たしてきたブランドです。
スクレイピングツールの概要
ScrapeStormとは、強い機能を持つ、プログラミングが必要なく、使いやすい人工知能Webスクレイピングツールです。違う基盤のユーザーに二つのスクレイピングモードを提供し、1-Clickで99%のWebスクレイピングを満たします。ScrapeStormにより、大量のWebデータを素早く正確的に取得できます。手動でデータ抽出が直面するさまざまな問題を完全に解決し、情報取得のコストを削減し、作業効率を向上させます。
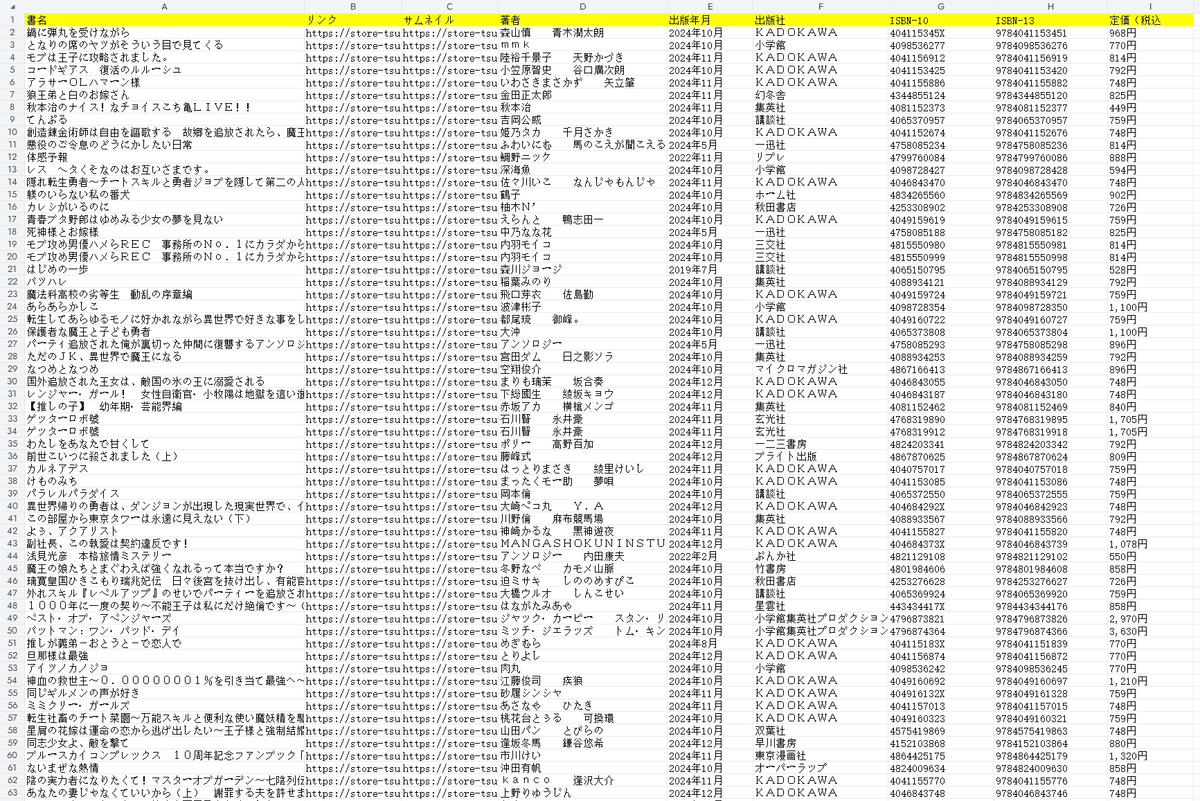
抽出されたデータをご覧ください。
1.タスクを新規作成する
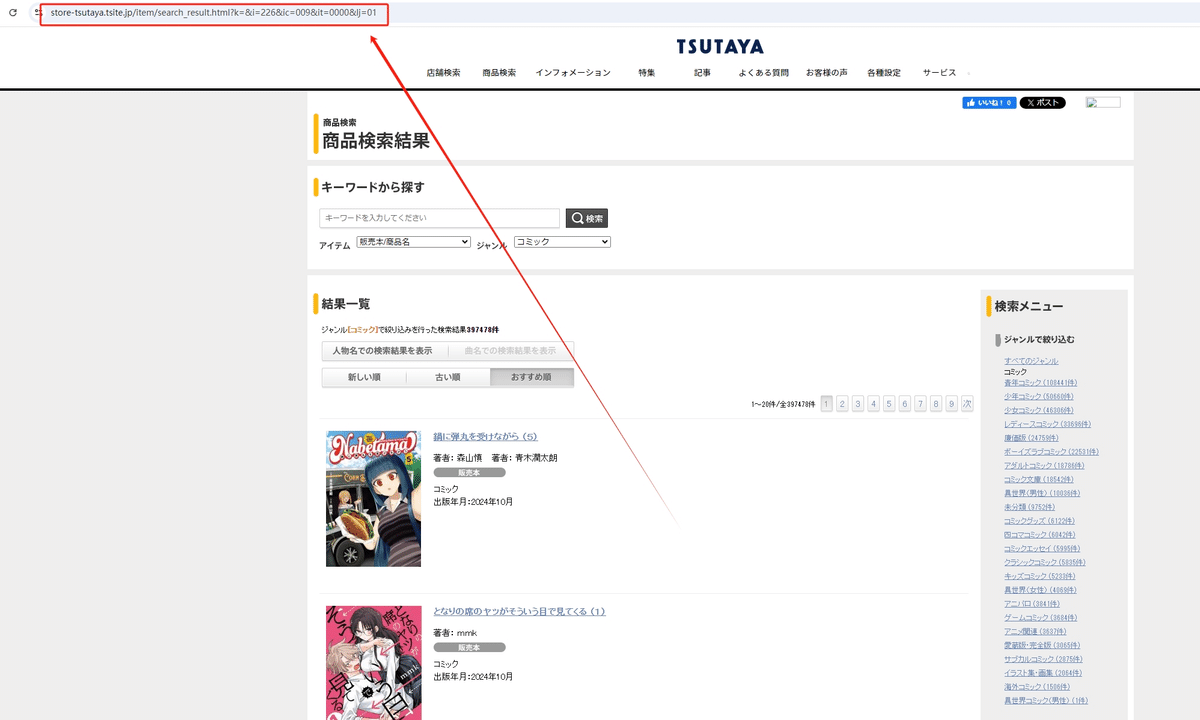
(1)URLをコピーする
今回は販売しているコミックの一覧ページからコミックの情報を収得し、そのスクレイピング方法を紹介します。まず、URLをコピーしてください。
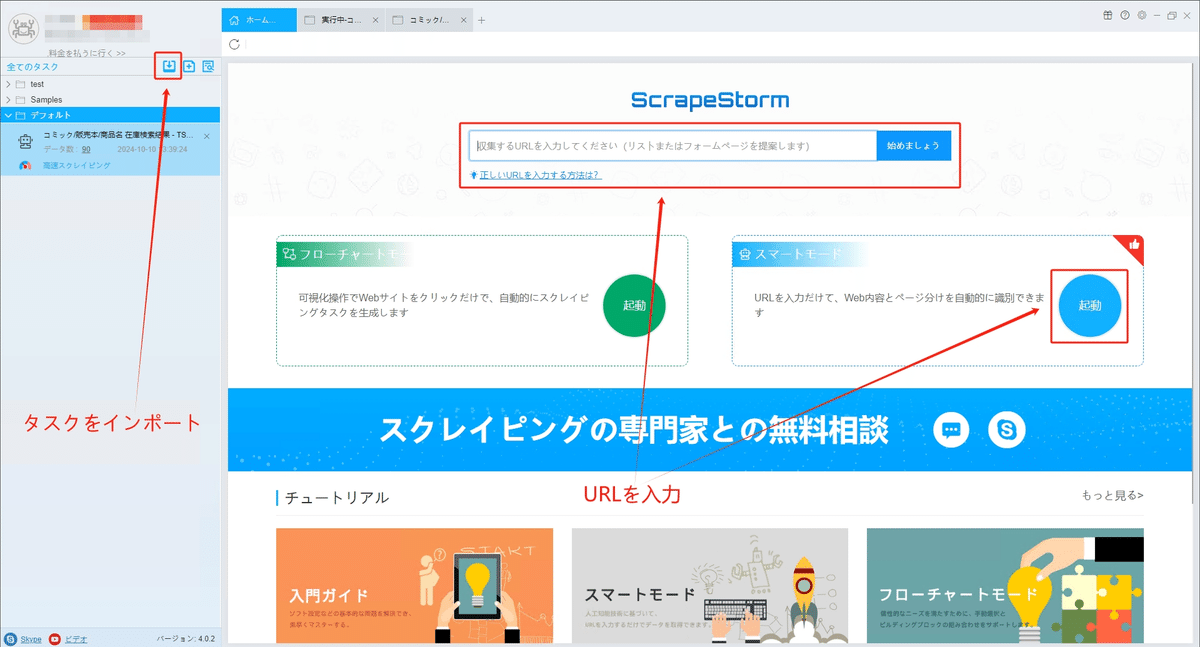
(2)スマートモードタスクを新規作成する
ScrapeStormのホームページ画面にスマートモードタスクを新規作成します。また、持っているタスクをインポートすることもできます。
詳細には下記のチュートリアルをご参照ください。
スマートモードタスクの新規作成方法
2.タスクを構成する
(1)自動識別
ScrapeStormは自動的にリスト要素とページボタンを識別できます。偶に誤差があれば、手動で選択してください。下記のチュートリアルも参照してください。
ページ分けの設定方法
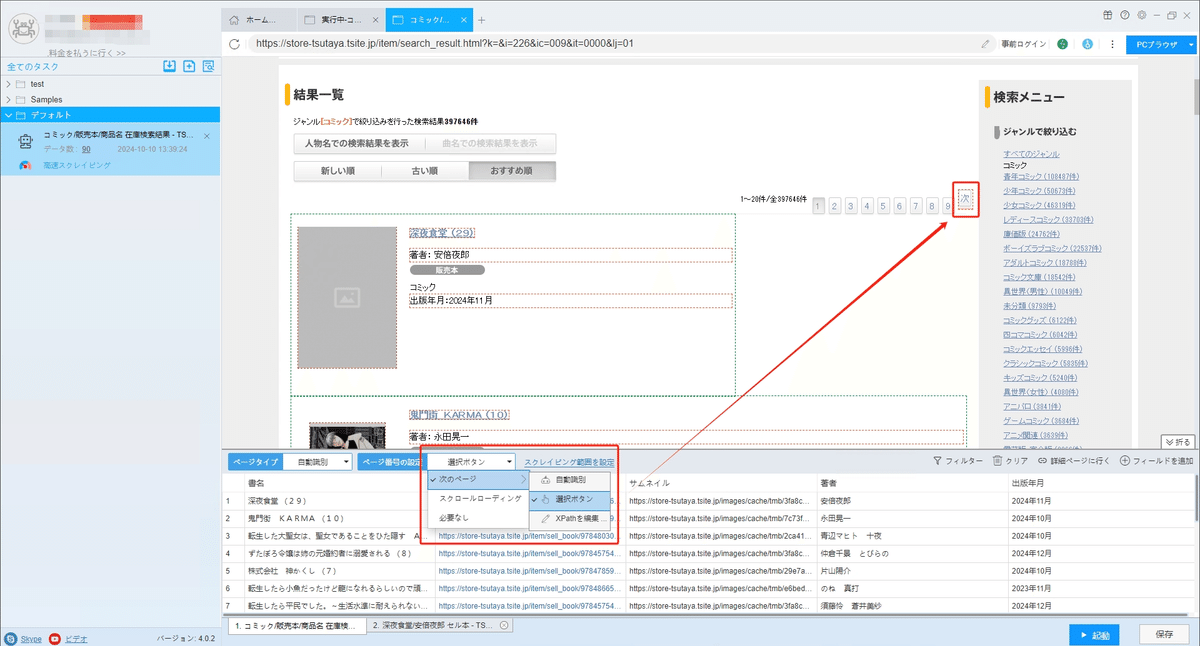
(2)詳細ページに行く
ソフトウェアの「詳細ページに行く」機能を利用し、出版社、定価、ISBNコードなどの情報を抽出します。
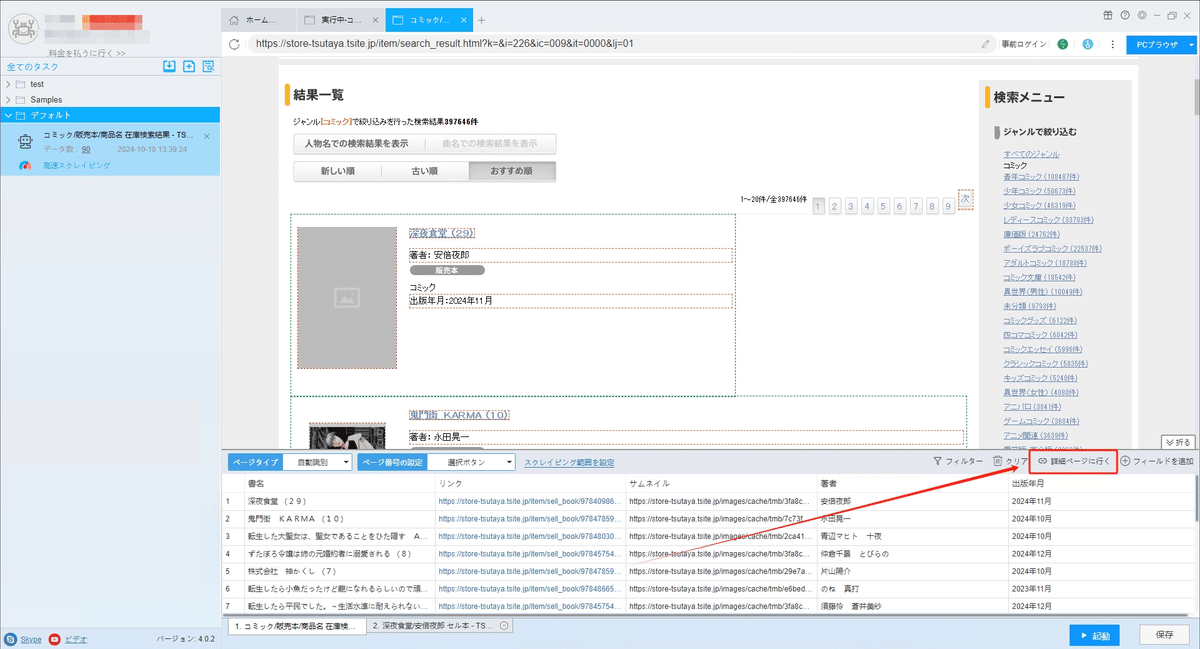
(3)フィールドの追加と編集
「フィールドを追加」ボタンをクリックして、画面に必要な要素を選択、データが自動的に抽出されます。また、必要に応じてフィールドの名前の変更または削除、結合できます。
フィールドの設定の詳細には下記のチュートリアルをご参照ください。
抽出されたフィールドを配置する方法
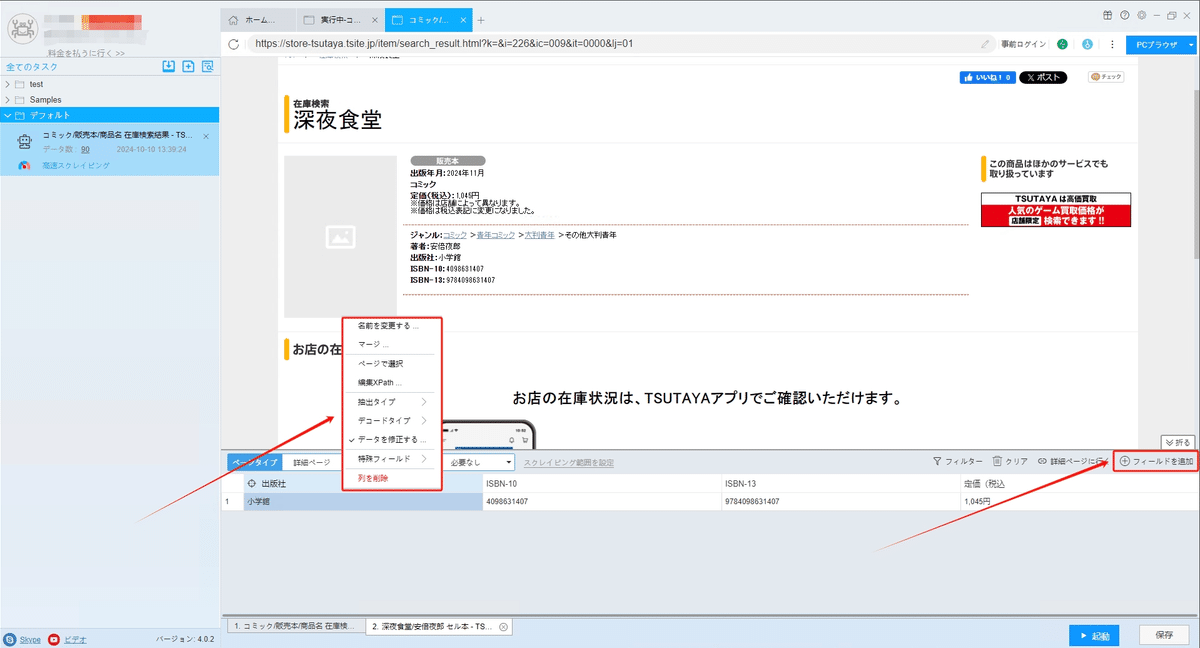
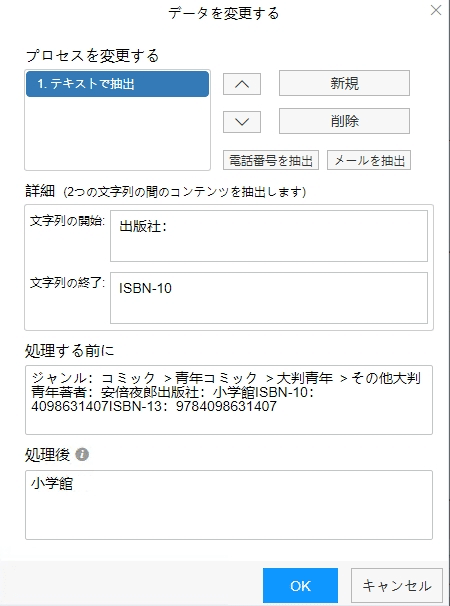
(4)データ処理
抽出されたデータを「データ処理」機能を利用して、クリーニングできます。
3.タスクの設定と起動
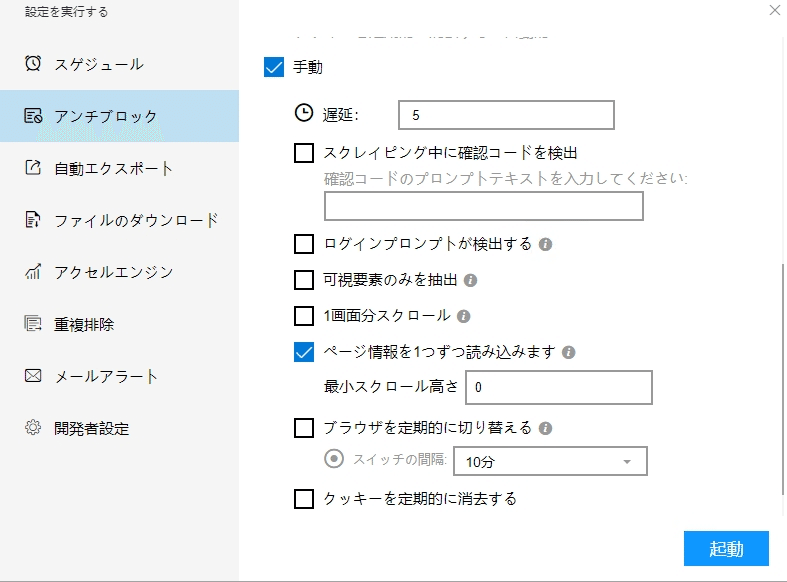
(1)起動の設定
必要に応じて、スケジュール、アンチブロック、自動エクスポート、写真のダウンロード、スピードブーストを設定できます。サーバーに負荷しないように、遅延時間を設定してください。5秒以上を推薦します。スクレイピングタスクを配置する方法については、下記のチュートリアルをご参照ください。
スクレイピングタスクを配置する方法
(2)しばらくすると、データがスクレイピングされる。
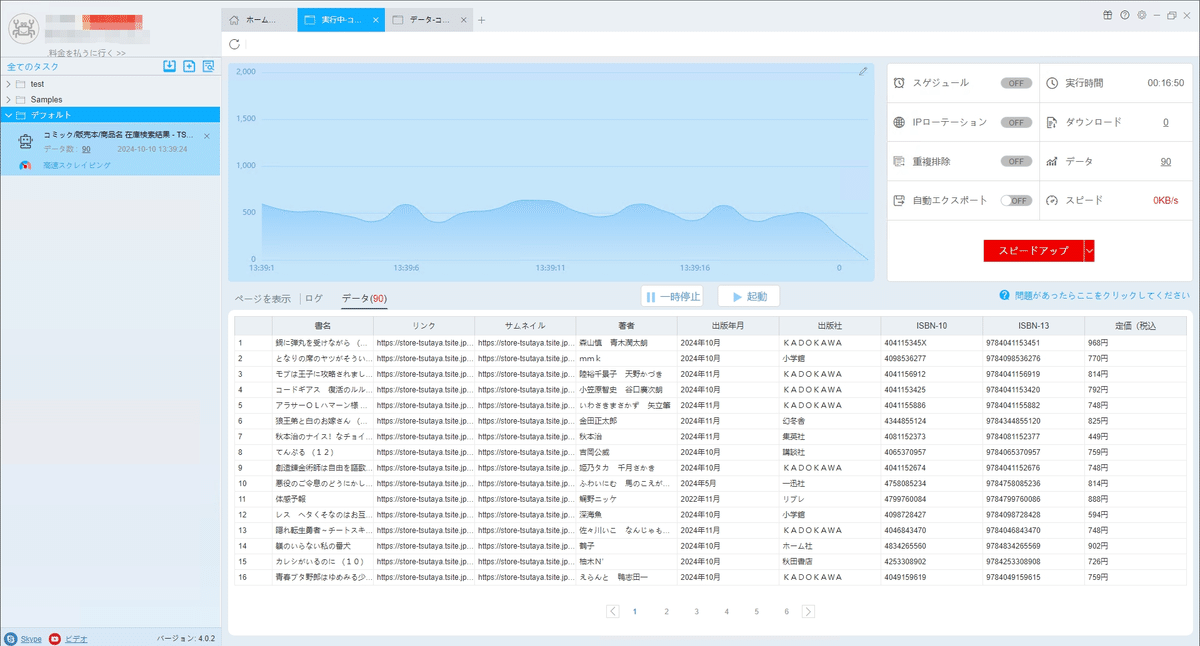
4.抽出されたデータのエクスポートと表示
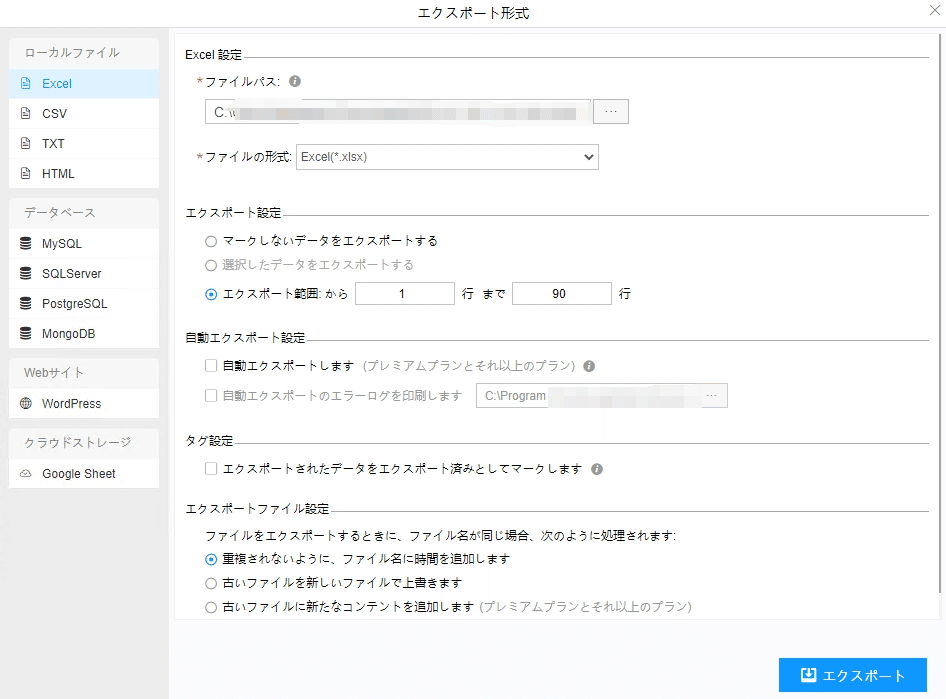
(1)エクスポートをクリックして、データをダウンロードする
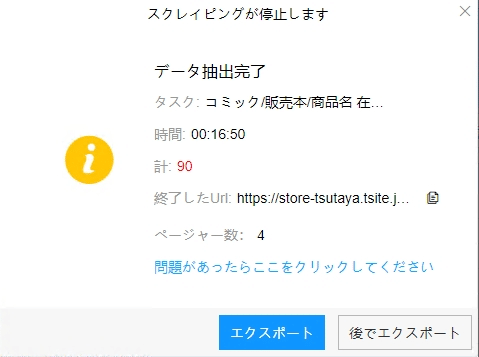
(2)必要に応じてエクスポートする形式を選択します。
ScrapeStormは、Excel、csv、html、txt、データベース、ローカルなどさまざまなエクスポート方法を提供します。抽出結果のエクスポート方法の詳細には下記のチュートリアルをご参照ください。
抽出されたデータのエクスポート方法