
ComfyUIの「animate diff」でアニメーション制作をしたあれこれ

ComfyUIを使い始めてから、animate diffで思い通りに動くアニメーションを作ろうとあれこれ試した記録です。
今回は「SDXL」モデルを利用してanimate diffでアニメーション制作を行いたいと思います。
「Comify UI」とは何ぞやという方は下記の記事をご参照ください。
簡単に導入したい方は「Stability Matrix」の方が良いです。
アニメーション生成
まずはアニメーション生成を行う上で、やりたいことをまとめました。
やりたいことは以下
①アニメーションのサイズを上げて高画質化
②Controlnetを使って、動きを制御する
③フレームごとにプロンプトの指定
①アニメーションのサイズを上げて高画質化
まずはアニメーションのサイズを上げて高画質化してみます。
こちらは「Baku」さんの記事を参考にしています。
ComifyUIでanimate diffを使うためには2種類の拡張機能が必要なのでそちらをダウンロードします。
今回必要な拡張機能は以下の記事で紹介しているので、こちらをご一読ください。
拡張機能を入れたら、以下の画像をComifyUIに読み込ませてください。

流れとしては一度生成した画像をUpscaleを使って拡大して、再度書き出しを行っている感じになります。
モデルを設定して生成すると以下のようになります。
確かに気持ち高画質になったような気がしますね!


②ControlNetを使ってアニメーション生成する
次は「ControlNet」を使って動画をもとにして、アニメーションを作ってみたいと思います。
実写映像を持っていなかったので、以下のサイトでお借りしています。
https://www.pexels.com/videos/
control netのワークフローはこんな感じです。
Load Imageは気にしないでください(笑)

生成した結果はこちら
うん、カメラをめっちゃいじってますね。
指とか確かに変な部分はありますが、中々ではないでしょうか。
今度はゲームの映像で試したら、どうなるのか気になったので試してみます。
動画については良いものが見つからなかったので、別垢で撮影したドンキーコングの動画を使ってみようと思います。
Controlnet周りは以下のようなワークフローで設定しました。
実写の時と全く同じです。
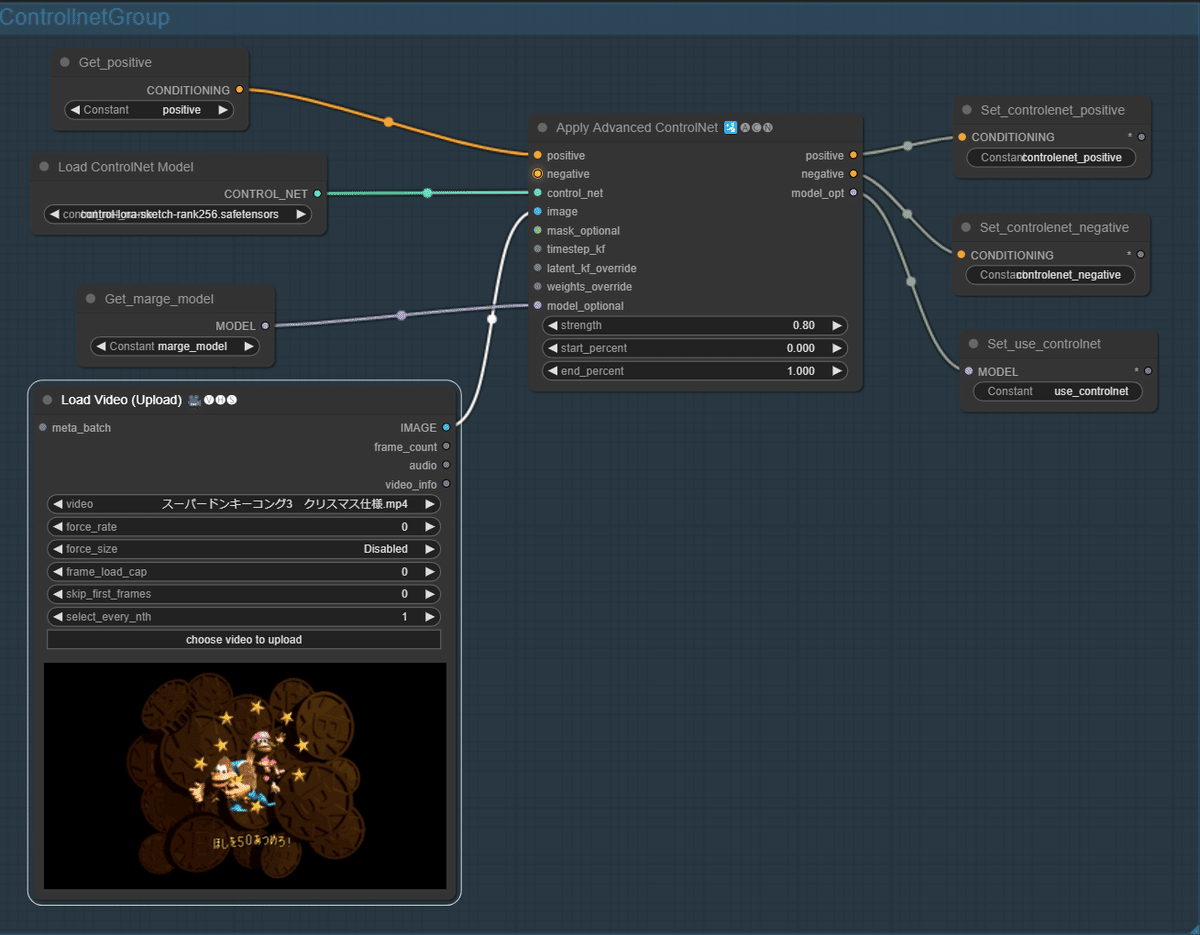
animate diffの部分は以下のようにフローを組んでいます。

それでは実際にどんな風に生成されるのか見てみましょう。
…まあ仕方ないですよねー!
ゲームの映像から動画を作ることは中々ハードルが高いようです。
Clip set Last Layer(勉強用メモ)
渡したプロンプトをもとに、ニューラルネットワークに情報が渡される。
その際に、どの深度まで情報を引き渡すのかを設定する。
clip skipの値が高いほどプロンプトを無視したものになる。
clip skipの値が低いほどプロンプトを反映したものになる。
仕組みはstable diffusionはプロンプトを呼び出す処理を層ごとに判定している。
全部で12層あり、表層から深層に行くにつれて情報量が多くなる。
ただし、情報量が多くなるにつれて、プロンプトが反映されにくくなる。
それは多角的にプロンプトを判定して、情報を持たせていった結果、膨大になり、画像の生成の構図が崩れてしまう。
loraを使う場合は「2」が適当(らしい)。
ポイントはプロンプトが複雑な場合。
解釈の幅が広く、情報量が多くなってしまうので、clip skipの値を変えることで、情報量を調整して、画像の構図を変える。
③フレームごとにアニメーションのプロンプトを使い分ける
これは「batch prompt schedule」を使って、フレームごとにプロンプトを適用させることでできるようになります。
以下のようにフレームごとにプロンプトを記載することで、動きを表現できるようになります。

全体はこんな感じです。
それでは早速生成してみましょう!

完全なウインクとはいきませんが、プロンプト通りに動いていますね!
動画のフレームとかを合わせればもう少し、何とかなりそうです!
こちらのワークフローを掲載しておきますので、よろしければお試しください!
試してみた感想
動画が作れるようになったのはすごく大きいですよね。
狙った動画やテレビアニメーションのような動きができるようになるのはもう少し先になりそうですが、簡単な立ち絵のアニメーションなどは作れるようになっていくのではないかなと感じます。
それでは皆様、よき創作ライフを…!