
DMBOK第14章ビッグデータとデータサイエンス

要約
データサイエンスはデータのパターンを見つけ、予測モデルを構築するためにデータマイニングや統計分析、機械学習を使用します。
ビッグデータアーキテクチャでは、データが統合される前に取り込まれ、非構造化データのためにデータレイクが必要です。サービスベース・アーキテクチャは即時データを提供し、完全な履歴データセットを更新できる仕組みで、バッチ層、スピード層、サービング層の3つのコンポーネントがあります。
データサイエンス業務では、広範なデータソースの選択が重要であり、データ品質の評価やMPPシェアードナッシングテクノロジーの利用も考慮されます。また、分散ファイルベースのデータベース技術やHadoop、Spark、Beamなどが大量のデータを安価に保存し処理するために利用されます。
前章
前の章である第13章データ品質はこちらです。
一般的な知識
データサイエンスとは
データサイエンスは、データコンテンツのパターンを見つける、予測モデルを構築するためにデータマイニングや統計分析、機械学習、データ統合機能やデータモデリング機能を使用します。
ビッグデータアーキテクチャとは
従来のデータウェアハウスでは、データをウェアハウスに取り込むときに統合されますが、ビックデータ環境では、データが統合される前にインジェストされ、取り込まれます。 統合して、初めて使用準備が整うのではなくて、特定の目的用途に合わせてデータが統合されることが多いです。
また、画像や音声などの非構造化データが登場してきたため、それらのデータを格納するデータレイクが必要になります(メタデータ管理が必須)。
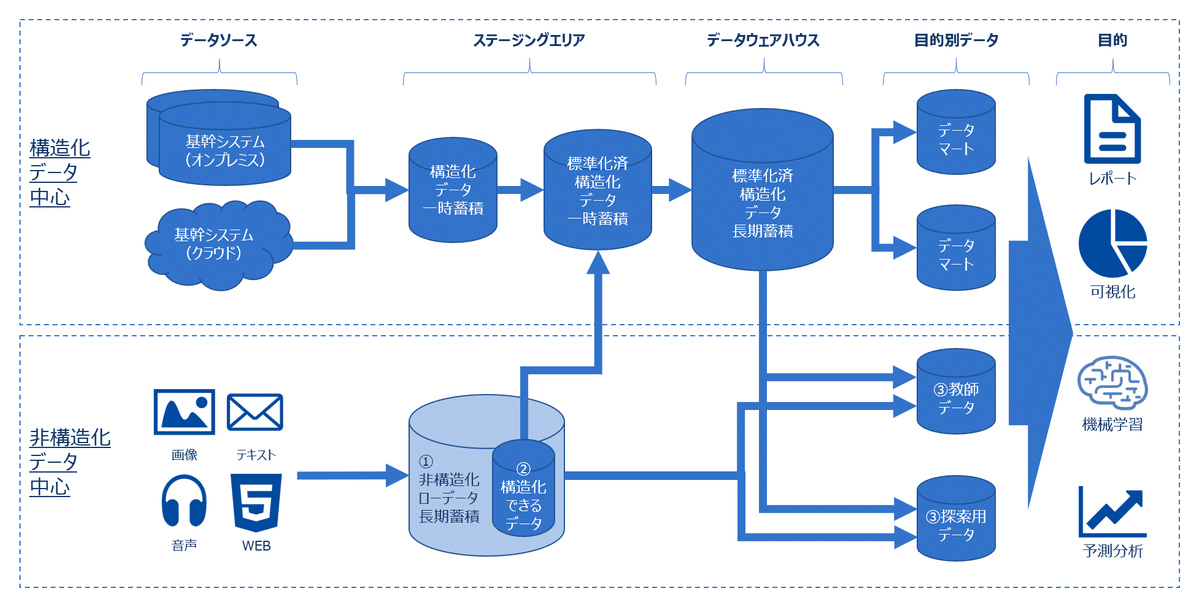
サービスベース・アーキテクチャとは
正確性や完全性が保障されなくても、即時データを提供するために完全で正確な履歴データセットも更新できるようにサービスベースアーキテクチャが登場しました。
サービスベース、アーキテクチャには、バッチ層、スピード層、サービング層の3つの主要コンポーネントがあります。データはバッチ層とスピード層の両方に読み込まれます。そして、サービング層では、データがどこから提供されるべきかが見極められ、ビューして役割を持ちます。
データマッシュアップとは
マッシュアップは、データとサービスを組み合わせて洞察や分析のための資格日を実現します。もともとは規定のコードに名前や摘要を関連付けるために使用されていた機能です。
例としてさまざまなAPIから取得したデータを組み合わせて、顧客に対して豊富な情報や機能を提供したりすることです。
アクティビティ
データソースの選択
開発と同様に組織が解決しようとしている問題を考慮して、データサイエンス業務用のデータソースを選択しなければいけません。データサイエンスの開発が特殊なのは、データソースの範囲が広いことが1つの原因です。フォーマットに制限されず、データをソリューションに組み込むにはリスクが伴います。
データソースの取得・インジェクト
ソースを特定した後に、それがどこにあるかを見つけ、Big Data環境に援助する必要があります。このプロセスでは、コンテンツの発生源サイズ追加で把握しておくべきことなど、ソースに関する重要なメタデータを取得する必要があります。
データを統合する前にその品質を評価すべきです。評価のやり方は、単純な場合や複雑な場合があり、フィールドにNull値が含まれているかを調べるクエリをかける程度のこともある。一方で、プロファイリングし、分類し、識別するために、データ品質つりやプログラムを実行する場合もあります。
MPPシェアードナッシングテクノロジー
超並列処理シェアードナッシングデータベース技術は、ビッグデータセットに対するデータサイエンス分析を行う標準プラットホームとなっています。MPPデータベースでは、データが複数の処理サーバーに分割され、格サーバーがデータを自己処理する専用のメモリを備えています。処理サーバー間の通信は、通常マスターホストによって制御され、ネットワーク相互接続を介して行われます。
MPPを使用すると、サーバー台数を限りなく増加させれば何十、何千というCPUコア並列処理を簡単に拡張できます。超並列拡張性を備えたシェアードナッシングアーキテクチャにより各CPUコアが100%利用され、大規模データに対する線形的拡張性と処理性能が向上します。

分散ファイルベースのデータベース
オープンソースであるHadoopや、Sparkなどの分散ファイルベースのソリューション技術を使えば、大量のデータを様々な形式で安価に保存ができます。
Hadoopは構造化、非構造化等、どんなタイプのファイルでも格納でき、MPPシェアードナッシングと同様の構成を使用して処理サーバー間でファイルを共有します。これはデータを安全に保存するのに理想的です。
Hadoop
Hadoopとは、大規模データの蓄積・分析を分散処理技術によって実現するオープンソースのミドルウェアです。
詳細は以下の記事を参照して下さい。
SparkやBeam
正直、Hadoopは最近使用されなくなってきています。
より早く処理できる並列分散処理が登場してきており、Apache SparkやApache Beam等が台頭しています。
概要だけでも掴んでおくと良いかと思います。
まとめ
以上、ビッグデータとデータサイエンスについて解説しました。
大量のデータを扱うための技術について触れました。また、データが様々な形になっているため、データレイクが登場したりしています。
この章では基本的なデータサイエンスや機械学習については言及していません。それらについては他の書籍に譲ります。
DMBOKのビッグデータとデータサイエンスについて特に重要な点を解説しました。ただし、非常に量が多いため解説していない部分が多々あります。詳細は本書を手にとってみて下さい。
いいなと思ったら応援しよう!
