
Attention機構を用いない拡散モデル: DIFFUSSM

本記事について
本記事は以下の論文の意訳記事になります。
Diffusion Models Without Attention
https://arxiv.org/pdf/2311.18257
概要
高品質な画像生成において、Denoising Diffusion Probabilistic Models (DDPMs)が重要な役割を果たしています。しかし、高解像度の画像生成への適用には計算量が爆発的に増えるという課題があります。既存手法は、UNetやTransformerベースのアーキテクチャで構成されており、プロセスを高速化するためにパッチ化を使用していますが、トレードオフとして表現能力を犠牲にしています。
この問題に対処するため、元論文ではDiffusion State Space Model (DIFFUSSM)を提案しています。DIFFUSSMは注意機構をより拡張性の高いstate space modelバックボーンに置き換えることで、グローバルな圧縮を行わずに高解像度を効果的に扱い、拡散プロセス全体で詳細な画像表現を保持します。
実験としてImageNetとLSUNデータセットの2つの解像度で包括的な評価を行い、DIFFUSSMが注意機構を持つ既存の拡散モデルと同等またはそれ以上のFIDとInception Scoreを達成しながら、総FLOP使用量を大幅に削減することに成功しました。

提案手法
DIFFUSSMの主要な特徴は以下の2つの側面から構成されています:
State Space Models (SSMs)
DIFFUSSM block
State Space Models (SSMs)
SSMsは離散時間の時系列データを処理するためのアーキテクチャクラスです。以下の式で表されるスカラー入力シーケンスu1, ..., uLを出力y1, ..., yLに処理するRNNのように動作します:


SSMsの主な利点は、線形構造により再帰的な処理ではなく長い畳み込みを使用して実装できることです。具体的には、yはuからFFTを使用してO(L log L)の計算量で計算できるため、より長い時系列データに適用できます。
本研究では、簡略化された対角化バージョンのSSMであるS4Dをバックボーンモデルとして使用しています。
DIFFUSSMブロック
DIFFUSSMの中心的なコンポーネントは、長いシーケンスの処理を最適化することを目的とした、ゲート付き双方向SSMです。効率を高めるために、MLP層内に砂時計型アーキテクチャを組み込んでいます。このデザインは、双方向SSMの周りでシーケンス長を拡大と縮小を交互に行い、特にMLPでシーケンス長を縮小します。
具体的には、各砂時計層は短縮された平坦化入力シーケンス\bf{I} \in \mathbb{R}^{J\times D}を受け取ります。ここで、M = L/Jはダウンスケールとアップスケールの比率です。同時に、双方向SSMを含むブロック全体がグローバルコンテキストを完全に活用するために元の長さで計算されます。
DIFFUSSMブロックの計算は以下のように行われます:

ここで、σは活性化関数を表します。
このゲート付きSSMブロックは、スキップ接続と共に各層に統合されています。さらに、過去の研究に従って、各位置でクラスラベルy \in \mathbb{R}^{L\times 1}とタイムステップt \in \mathbb{R}^{L\times 1}の組み合わせを統合しています。

DIFFUSSMブロックのパラメータ数は主に線形変換\bf{W}によって決定され、M = 2の場合13D^2パラメータとなります。これは、DiTトランスフォーマーブロックのコアトランスフォーマー層の12D^2パラメータと比較可能です。
FLOPsに関しては、DIFFUSSMの1層あたりの総FLOPsは13(L/M)D^2 + LD^2 + \alpha 2L \log {LD}となります。ここで、αはFFT実装の定数を表します。M = 2とし、線形層が計算を支配することに注目すると、これはおよそ7.5LD^2 GFLOPsになります。
実験設定
データセット
主な実験は、ImageNet-1kとLSUNデータセットで行われました。
ImageNet-1k: 128万枚の画像と1000クラスのオブジェクトを含むデータセット
LSUN: Church (12.6万枚の画像) とBedroom (300万枚の画像) の2カテゴリーを選択
実験は以下の解像度で行われました:
ImageNet: 256×256および512×512
LSUN: 256×256
潜在空間エンコーディングを使用し、有効サイズは32×32(L = 1024)と64×64(L = 4096)にして行いました。
モデル構成
DIFFUSSMの最終ブロックの後、モデルは逐次画像表現を元の空間次元にデコードして、ノイズ予測と対角共分散予測を出力します。線形デコーダーを使用し、表現を再配置して元の次元を取得します。
DIFFUSSM-XLは約673Mのパラメータを持ち、モデルサイズD = 1152の29層の双方向ゲート付きSSMブロックで構成されています。
学習設定
元論文ではDiTに従い、すべてのモデル間で同一の設定を維持しました。また、モデルの重みの指数移動平均(EMA)を一定の減衰で保持しました。事前学習されたVAEエンコーダーをfreezeして使用されました。
計算コストを減らすために、混合精度トレーニングアプローチを採用しました。拡散の構成、線形分散スケジューリング、時間とクラスラベルの埋め込み、共分散\Sigma_{\theta}のパラメータ化など、ADMと同じ構成に従いました。
評価指標
モデルの画像生成性能を定量化するために、以下の指標を使用しました:
Frechet Inception Distance (FID)
sFID
Inception Score
Precision/Recall
FID-50Kを報告し、250 DDPMサンプリングステップを使用しました。
実験結果
クラス条件付き画像生成
DIFFUSSMを既存のクラス条件付き生成モデルと比較しました。
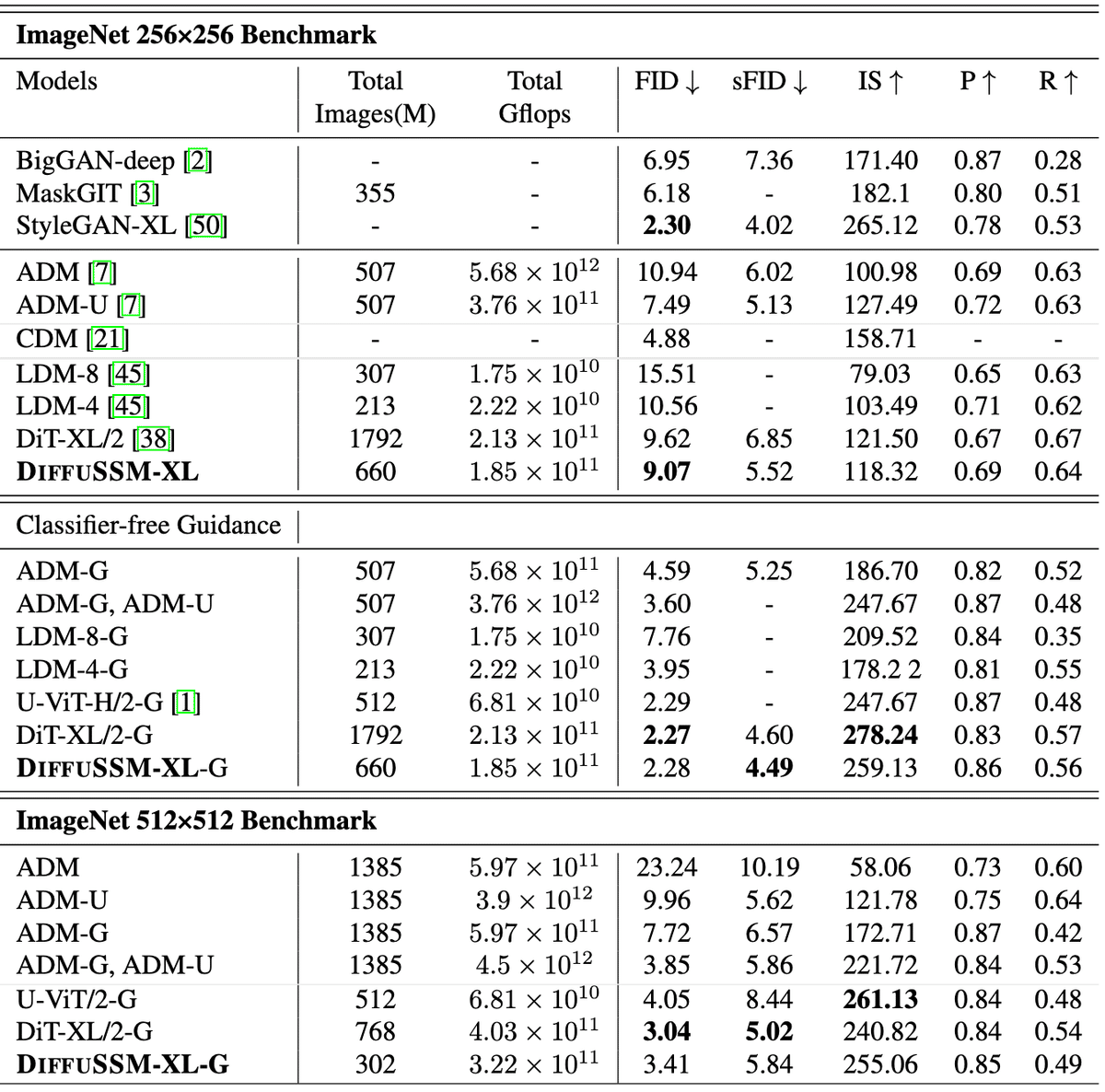
分類器フリーガイダンスを使用しない場合、DIFFUSSMは他の拡散モデルをFIDとsFIDの両方で上回り、以前の非分類器フリーの潜在拡散モデルの最高スコアを9.62から9.07に改善しました。これは約3倍少ないトレーニングステップで達成されました。トレーニングの総GFLOPに関しては、非圧縮モデルはDiTと比較して総GFLOPを20%削減しました。
分類器フリーガイダンスを組み込んだ場合、DIFFUSSMモデルはすべてのDDPMベースのモデルの中で最高のsFIDスコアを達成し、他の最先端の戦略を上回りました。これは、DIFFUSSMによって生成された画像が空間的歪みにより頑健であることを示しています。FIDスコアに関しては、DIFFUSSMは分類器フリーガイダンスを使用した場合にすべてのモデルを上回り、DiTとの差はわずか0.01に留まりました。
高解像度のベンチマークでは、DIFFUSSMは分類器フリーガイダンスを使用した場合、sFIDですべてのモデルを上回り、FIDスコアでも比較可能な結果を達成しました。DIFFUSSMは3.02億枚の画像でトレーニングされ、DiTの40%の画像数と25%少ないGFLOPsを使用しました。
まとめ
本研究では、注意機構を必要としない拡散モデル向けのアーキテクチャであるDIFFUSSMを提案しました。このアプローチは、表現圧縮を必要とせずに長系列の隠れ状態を扱うことができます。
実験結果は、このアーキテクチャが256x256の解像度でDiTモデルよりも少ないGFLOPsを使用してより良いパフォーマンスを達成でき、より高い解像度でも少ないトレーニングで競争力のある結果を得られることを示しています。
このモデルは大規模な効果的な拡散モデルを学習する際の注意機構のボトルネックを取り除くことで、高品質オーディオ、ビデオ、3Dモデリングなど、長系列拡散を必要とする他の分野への応用が考えられます。
この記事が気に入ったらサポートをしてみませんか?