YOSOKU|予測財務諸表グラフ化Pythonツール実践ガイド

ザイマニが開発した「YOSOKU」とは、上場企業の決算データ(実績値)を材料に、将来の業績予測とグラフ化を実現するPythonツールです。
一般的に、予測財務諸表の作成には社内の担当者による精緻な数字の積み上げが必要ですが、プログラミングを活用することで、誰でも公開情報のみでスピーディーに業績を予測できるのが本ツールの強みです。
本記事ではYOSOKUの具体的な使い方、つまり、将来の業績予測&グラフ化手順をわかりやすく解説します。
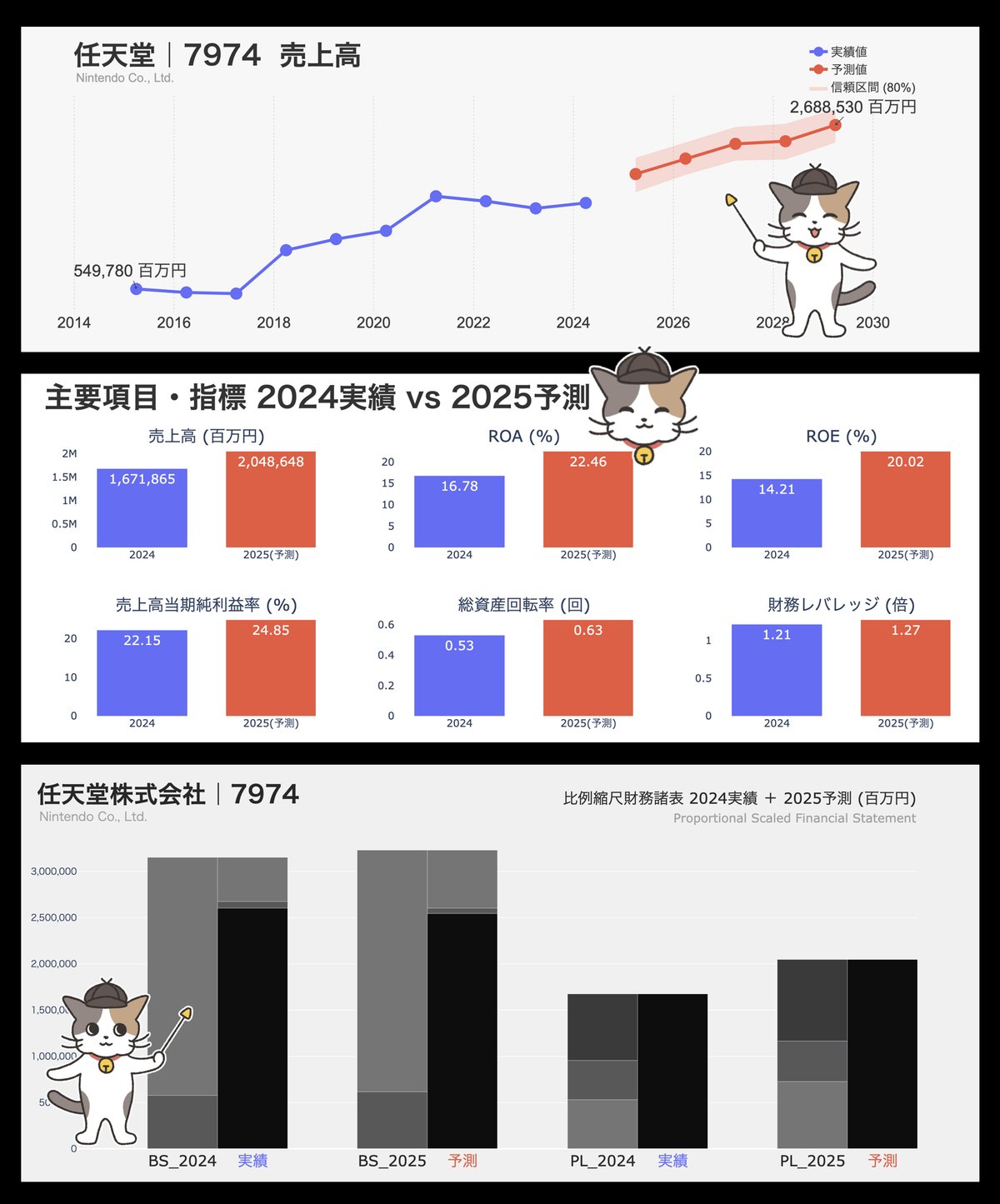
本ツールの全体像と具体的なアウトプットイメージがこちら▼

・気になる企業の業績を予測してみたい
・転職先の将来性を競合他社と比較してみたい
・IRで将来の業績を説明する際の参考にしたい
そんなビジネスパーソンにおすすめです。本ツールの概要がこちら▼
■分析材料
・YOSOKU|予測財務諸表グラフ化Pythonツール(購入ページ)
・YOSOKU専用データセットcsv:ゼミデータセットページの末尾からDL可
■使用ツール
・Google Colaboratory(Python)
※上記のYOSOKU専用データセットcsvに収録されていない上場企業や未上場企業を対象とする場合、ご自身でのデータ準備及びPythonコードの調整が必要となります。
本ツールの概要は以上です。以降はPythonコードにおける各セクションの処理内容や、業績予測・グラフ化の手順、ユーザーが注意して設定すべき変数などをわかりやすく解説します。
ぜひ、YOSOKUを実際にさわりながら読み進めてください▼
❶ YOSOKU(Google Colab)を保存
YOSOKU購入後、リンクから今回使用するGoogle Colaboratory(以下Colab)を開きましょう。ご自身のGoogleDriveにコピーしてからご活用下さい。コピー手順に困った場合はゼミレポート第6話にてご確認下さいませ。
以下は上記Colabの解説となります。Pythonでのデータ分析に慣れている方はそのままColabを読み進めていただいてもOKです。
❷ YOSOKUの全容を解説
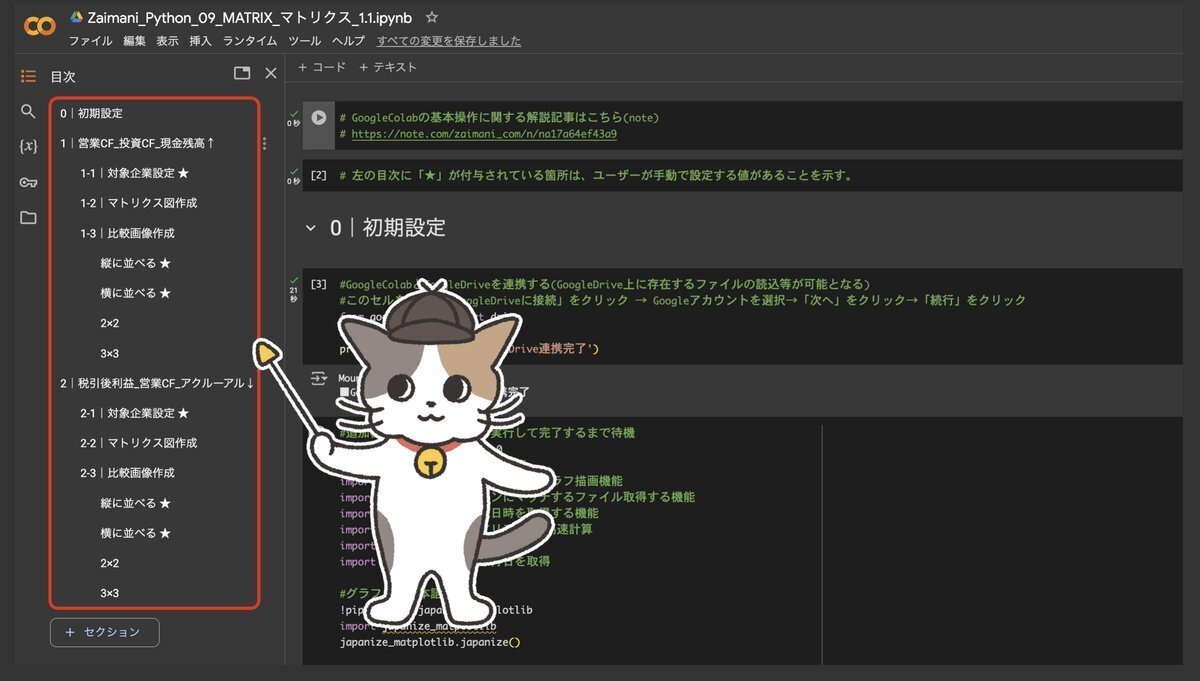
今回使用するプログラミングコードは以下の3セクションで構成されます。
0|初期設定
1|手動入力データで予測
2|YOSOKU用データセットで予測
以下では各セクションのコード内容を端的に解説します。不明点がありましたらザイマニ公式LINEより気軽にご連絡くださいませ。
❸ 各セクション解説
セクション0|初期設定
このセクションでは業績予測・グラフ化の下準備を行います。上からひとつずつセルを実行(「▶︎」をクリック)して下さい。
まずは拡張機能のインポートです。本ツールでは、「Prophet(プロペット)」というMeta社(旧Facebook社)が開発・公開している時系列データ解析用ライブラリ(拡張機能)を利用します。以下のコードで読み込んでいます。
from prophet import Prophetライブラリとは、簡単に言えばあらかじめ用意された便利なツール集です。例えば、ポケモンにおけるわざマシン(わざレコード)のようなもので、Colabに"Prophet"というわざを覚えさせて、簡単に時系列データの解析や予測が行えるようにする、とイメージしてください。
また、以下のコードまで実行すると、あなたのGoogleDrive上に新しいフォルダが作成されます(すでに同名フォルダが存在する場合、この処理はスキップ)。後続のコードでフォルダ名を指定している箇所もあるため、フォルダ名は極力変更しないようにしましょう。
# GoogleDrive上にフォルダ作成
# Pythonツールのアウトプットを保存するフォルダをGoogleDrive上に作成する
python_save_folder_path = '/content/drive/MyDrive/Colab Notebooks/02_Python_Tool_Output'
os.makedirs( python_save_folder_path ,exist_ok=True ) #フォルダが存在しなければフォルダを作成
# YOSOKU関連資料を保存するためのフォルダをGoogleDrive上に作成する
yosoku_save_path = '/content/drive/MyDrive/Colab Notebooks/02_Python_Tool_Output/04_YOSOKU/'
os.makedirs( yosoku_save_path ,exist_ok=True ) #フォルダが存在しなければフォルダを作成
# YOSOKUで使用する実績財務データをアップロードするフォルダをGoogleDrive上に作成する
yosoku_actual_dataset_path = '/content/drive/MyDrive/Colab Notebooks/02_Python_Tool_Output/04_YOSOKU/01_実績財務データ'
os.makedirs( yosoku_actual_dataset_path ,exist_ok=True ) #フォルダが存在しなければフォルダを作成
# YOSOKUで使用する実績財務データをアップロードするフォルダをGoogleDrive上に作成する
yosoku_predict_graph_path = '/content/drive/MyDrive/Colab Notebooks/02_Python_Tool_Output/04_YOSOKU/02_将来予測グラフ'
os.makedirs( yosoku_predict_graph_path ,exist_ok=True ) #フォルダが存在しなければフォルダを作成セクション0|初期設定で注意すべき箇所は以上です。さっそく次のセクションへ進みましょう▼
セクション1|手動入力データで予測
GoogleColab上に手動で入力したデータをもとに、そのデータの将来を予測するセクションです。

以降の処理においてユーザーが手動で設定が必要な箇所には左の目次に「★」が付与されています。例えば「1-1|データ入力 ★」です。
1-1では予測したい項目の年次日付と実績値(過去データ)を入力します。デフォルト状態では日本の人口データと任天堂の売上データ(コメントアウト状態)が入力されています▼
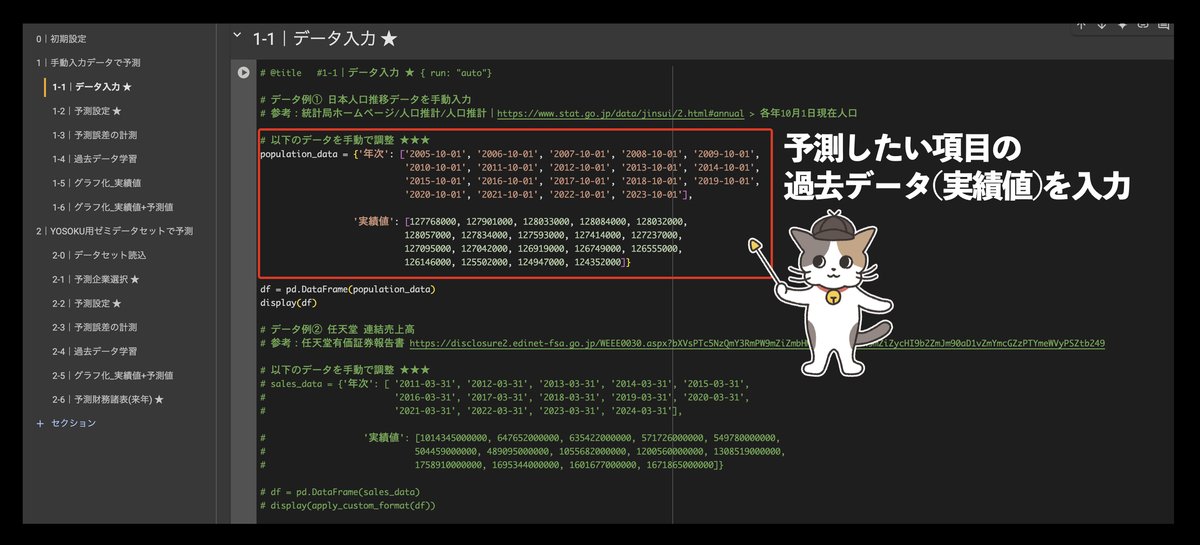
以降のセクション1の解説は、日本の人口データを軸に話を進めます。上場企業の売上高と比べてより親しみのある数字でわかりやすいためです。
これでデータ入力は完了です。忘れずにこのセルを実行して1-2|予測設定へ進みましょう。1-2では予測に関する細かい調整を行います▼
# ★★★ 手動調整可能箇所 ★★★
forecast_years = 5 # 何年間先まで予測するか
graph_title = "日本の人口" # グラフタイトル "任天堂の連結売上高" "日本の人口"など
graph_unit_name = "人" # 単位 "人"や"円"など。
# ★★★ 手動調整可能箇所 ★★★
# 予測精度を評価する期間を設定
# デフォルトでは2005~2021の年データを学習→2022年と2023年の人口を予測→2022年・2023年の実績値(すでに確定している人口データ)と比較して誤差を求める。
train_start_year = 2005 # 最も古い実績データ
train_end_year = 2021
test_start_year = 2022
test_end_year = 2023 # 最も新しい実績データforecast_years, graph_title, graph_unit_nameの3変数は設定内容がイメージしやすい項目なので説明は割愛。その下にある予測精度を評価する期間の設定について詳しく解説します。ここでは1-1で日本の人口データが入力されていると仮定して話を進めます。
1-3以降では将来の日本の人口推移を予測するわけですが、その予測精度がどれだけ高いのかが分からなければ予測値に価値は生まれません。「結局この予測値ってどれくらい信頼できるの?」が分からなければ意思決定の判断材料として採用することはできないからです。
そこで、すでに手元にあるデータだけを使って予測精度テストを行います。その後、テストと同様の誤差が生じると仮定して未知データを予測するのが定石となります。具体的な予測フローを図解で整理したものがこちら▼
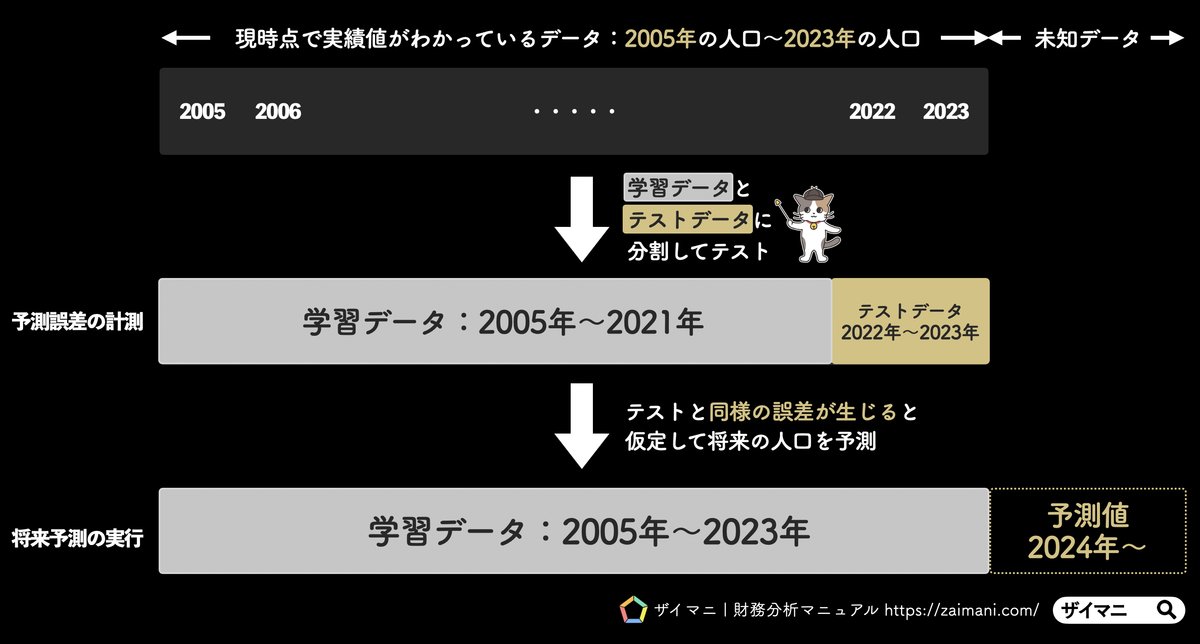
1-2では「予測誤差の計測」に使用するデータをどこで区分するかを設定します。デフォルトでは上記図解と同じ区分で設定されており、まずはこの状態のまま1-6まで実行してみるのがおすすめです。
train_start_year = 2005 # 最も古い実績データ
train_end_year = 2021
test_start_year = 2022
test_end_year = 2023 # 最も新しい実績データでは、さっそく予測誤差の計測(1-3)と予測の実行・グラフ化(1-4〜1-6)を実践してみましょう。と言っても、1-3から1-6まではユーザーが手動で設定する値がないため、上から順番に実行するだけでOKです。チェックすべきポイントだけ端的に解説します▼
1-3ではProphet予測とベースライン予測のMAPEに関するテーブルを確認しましょう。MAPEとは予測と実績のズレを%で示す指標であり、この値が小さいほど予測誤差が小さい(予測精度が高い)ことを示します。
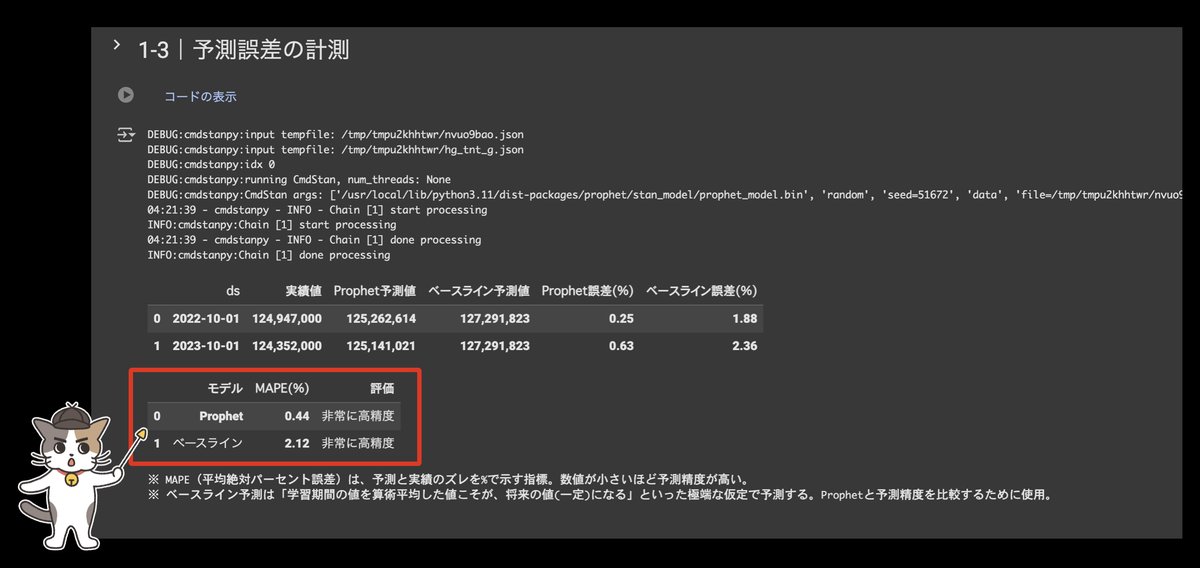
詳細は画像内の補足テキスト参照。
一般的に人口データは将来予測が容易なジャンルであるため、Prophetもベースラインも非常に精度が高いことが分かります。
1-4では改めて実績データを全て学習しているだけなので確認すべき箇所はありません、実行するだけでOKです。そして1-5と1-6で将来予測の結果とグラフが表示されます。
まず、1-5では実績データのみのグラフが2種類表示されます。ひとつはY軸が0始まりのグラフ。もうひとつはY軸が0で始まりではないグラフです▼

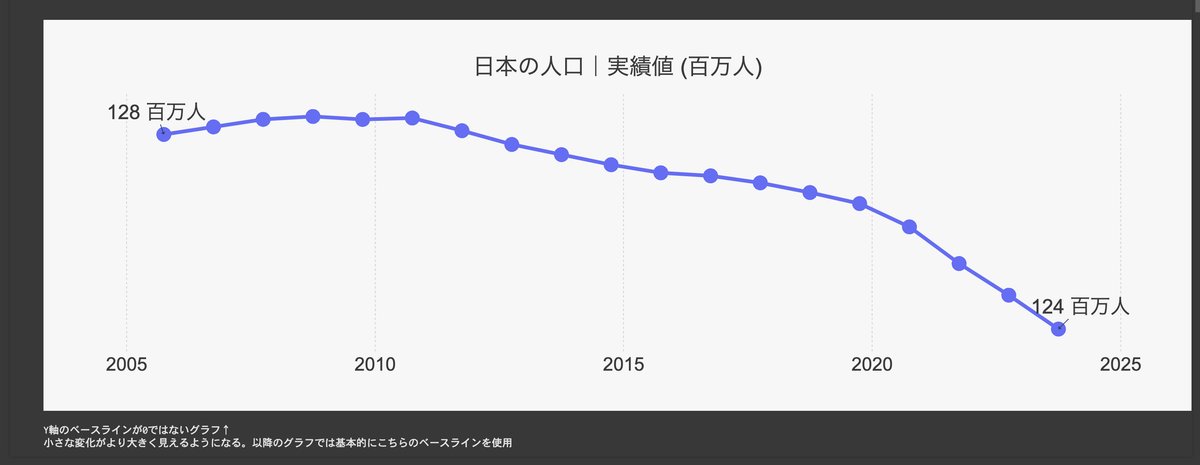
一般的に正の値をグラフ化する場合、Y軸の最小値は0である方が好ましいです。なぜなら、Y軸が0から始まらない(一部を切り取った)グラフは比較的小さな変化を、重大な変化であると誤認させてしまう可能性があるためです。
ただ、今回のような将来予測ケースでは、むしろ小さな変化をわかりやすく視覚化できる方が嬉しいため、後続のコードでは後者のY軸を採用します。
そして遂に1-6。実績値と予測値の両方を含んだグラフが表示されます▼
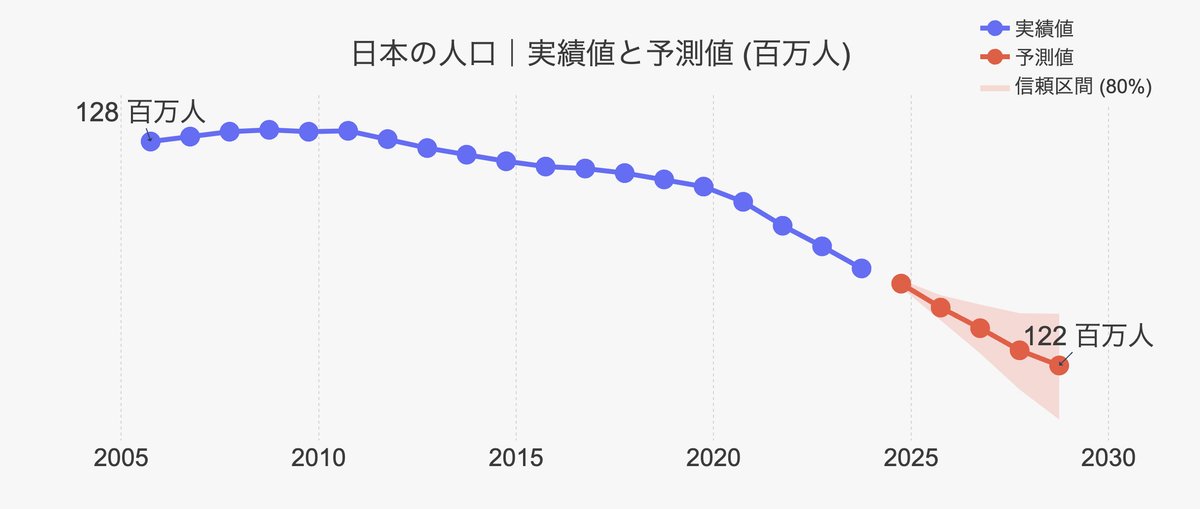
以上がセクション1の大まかな流れです。人口以外のデータを予測したい場合、1-1及び1-2を調整して再度1-6まで実行するだけでOKです。ぜひお試しくださいませ!
ただ、いちいちデータをColabに手動入力するのは正直手間がかかりますよね。そこで、セクション2ではあらかじめ用意されたデータセットcsvを利用して将来予測を行います▼
セクション2|YOSOKU用データセットで予測
YOSOKU用データセットをもとに、気になる上場企業の業績予測・グラフ化を行うセクションです。データ準備→予測誤差の確認→予測実行→グラフ化の流れはセクション1と同じです▼

まずはデータセットの読込です。他のザイマニPythonツール同様、GoogleDrive上にファイルをアップロードし、それをColabで読み込みます。
YOSOKU用のデータセットcsvはゼミデータセットDLページの末尾からダウンロード可能です。このデータセットの概要は以下の通り▼
・上場企業100社10年分のデータセット
・売上高や流動資産など基本項目のみ収録(約1,000行×23列)
・毎年1回4月に更新予定
こちらのデータセットは一般公開しても良いかな、と考えましたが過去10年分の主要項目を収録したデータセットには少なからず価値があると感じたため、2025年2月時点ではザイマニ財務分析ゼミのメンバーだけがダウンロードできる形を採用しております。
ダウンロードしたcsvを以下のフォルダ内にアップロードしましょう。
マイドライブ/Colab Notebooks/
02_Python_Tool_Output/04_YOSOKU/01_実績財務データ
アップロード後のイメージがこちら▼
続いて、2-1の直前までセルを実行すると、以下のテーブルが表示されます▼
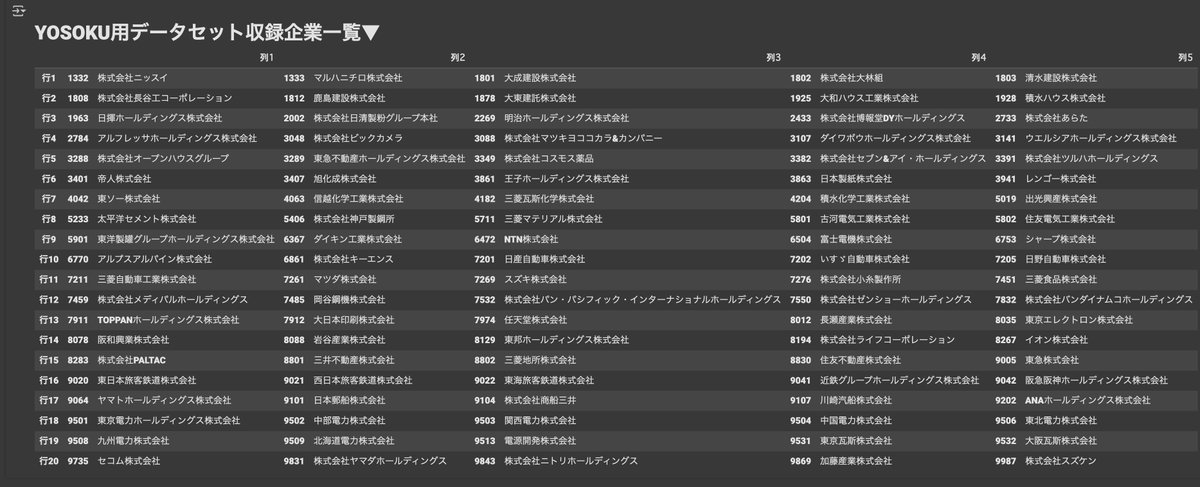
これがYOSOKU用データセットcsvに収録されている企業一覧です。セクション2で効率的に業績予測・グラフ化できる企業一覧とも言えますね。この中から好きな企業を選び、証券コードを2-1に入力しましょう▼

また、2-2では1-2同様に予測に関する設定を行います。こちらもまずはデフォルトのまま最後まで実行してみるのがおすすめです。
# ★★★ 手動調整可能箇所 ★★★
forecast_years = 5 # 何年間先まで予測するか
graph_unit_name = "円" # 単位 基本的に"円"
# ★★★ 手動調整可能箇所 ★★★
# 予測精度を評価する期間を設定
# デフォルトでは2015~2023の年データを学習→2024年の業績を予測→2024年の実績値(すでに確定している業績データ)と比較して誤差を求める。
train_start_year = 2015 # 最も古い実績データ
train_end_year = 2023
test_start_year = 2024
test_end_year = 2024 # 最も新しい実績データ2-3では各勘定科目の予測誤差が表示されます。「03_BS・PL・CF別MAPE(%)」テーブルを見れば財務三表のうち、どの予測精度が高くなりそうか(低くなりそうか)が分かりますよ▼

CF項目はプラス値とマイナス値の両方をとる(ブレが大きい)ため、予測誤差が大きくなりがちです。実務上でもBS・PL項目を中心に予測・分析するのがおすすめです。
続いて2-4で実績データの学習、そして2-5で各項目の実績値+予測値グラフの描画を行います。ユーザーが手動で設定する箇所はないため、コードセルを実行するだけでOKです▼
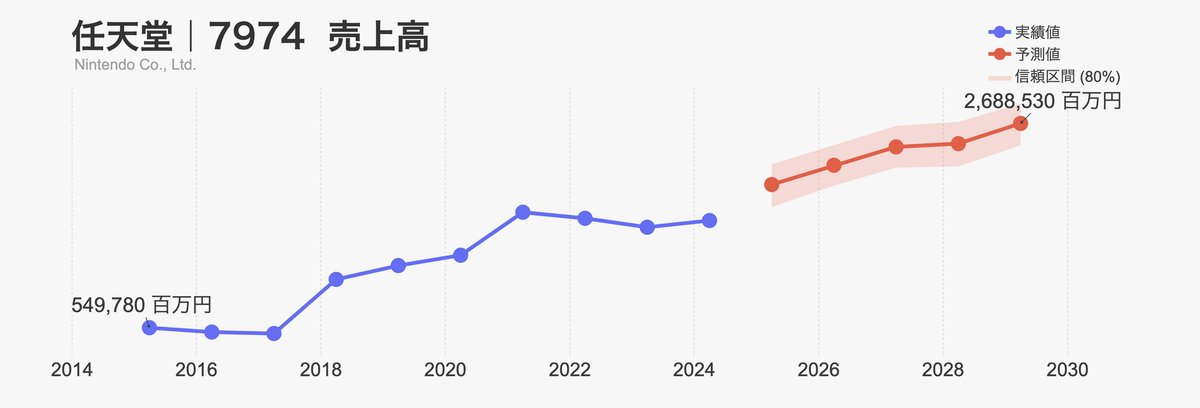
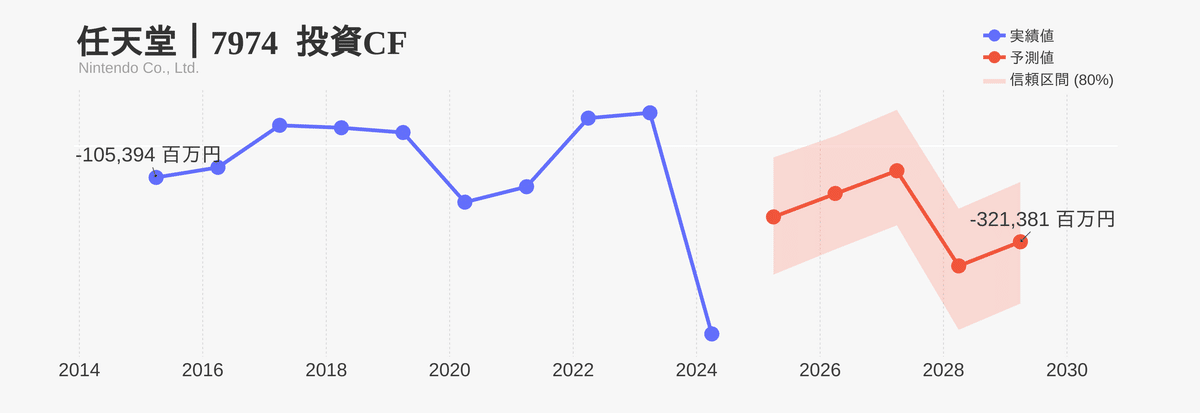
売上高と比べて投資CFの信頼区間の幅は広いですね。やはりCF項目の予測は難しいことが分かります。
最後に2-6です。ここでは来年度の業績予測および比例縮尺財務諸表(BS・PL)のグラフ化を行います。まずは好みの指標を以下で設定しましょう▼
# 以下の業績予測でグラフ化したい項目を6種類設定する ★★★
# 設定可能項目一覧
# 資産合計 流動資産 流動負債 固定資産 固定負債 純資産合計 売上高 売上原価 販管費
# 営業利益 売上高営業利益率 事業利益 当期純利益 流動比率 自己資本比率 ROA ROE 売上高当期純利益率 総資産回転率 財務レバレッジ
selected_indicators = [
"売上高",
"ROA",
"ROE",
"売上高当期純利益率",
"総資産回転率",
"財務レバレッジ"
]上記で選んだ6指標が棒グラフとして表示されます▼

また、比例縮尺財務諸表(BS・PL)も表示されます。BSやPLの全容が大きく変化しているかどうか一目で分かりますね▼

これらセクション2で表示したグラフは自動的にGoogleDriveに保存される仕様です。一度最後まで実行し、フォルダ内の画像をひとつずつ見ていくのも面白いですよ▼
■画像保存場所
マイドライブ/Colab Notebooks/02_Python_Tool_Output/
04_YOSOKU/02_将来予測グラフ/予測企業フォルダ
以上がYOSOKUセクション2の大まかな流れでした。ぜひこの機会に気になる企業の業績予測・グラフ化に挑戦してみましょう。
最後に、FAQを記載して締めくくりとさせて下さい▼
FAQ
Q1.セクション2で使えるデータセットに他の企業のデータを追加する予定はありますか?
A1. 現時点ではございません。リクエストが多ければ他の企業データの追加も検討、といった温度感です。
Q2. その場合、自分でエクセルなどにデータを入力したものをセクション2で使用することは可能ですか?
A2. 可能です。以下の手順をお試し下さい。YOSOKUのデータセットcsvをGoogleDriveにアップ→スプレッドシート化→気になる企業のデータを調べて手動で入力(追加でも上書きでもOK)→再度csv化→04_YOSOKU/01_実績財務データフォルダにアップ
Q3. 予測の精度をさらに上げたいです。どんな方法がありますか?
A3. やや上級者向けですが、Prophetの予測パラメーターをチューニングする方法があります。以下の記事が参考になります▼
・OptunaでProphetのパラメータをいじって時系列予測の精度を改善してみた #Python - Qiita
・Prophetモデルの概要とOptunaで自動でチューニングする方法 | Hakky Handbook
YOSOKU実践ガイドまとめ
この実践ガイド記事を読んだ上でよく分からない箇所やさらに詳しく解説してほしいコードなどあれば、いつでもザイマニ公式LINEのトーク画面から気軽にお声がけくださいませ。FAQとして追記させていただきます。
引き続き、ザイマニをよろしくお願いいたします。
▶︎ YOSOKU購入ページはこちら
▶︎ ザイマニのnote記事一覧はこちら